1.2 现代GPU的体系结构
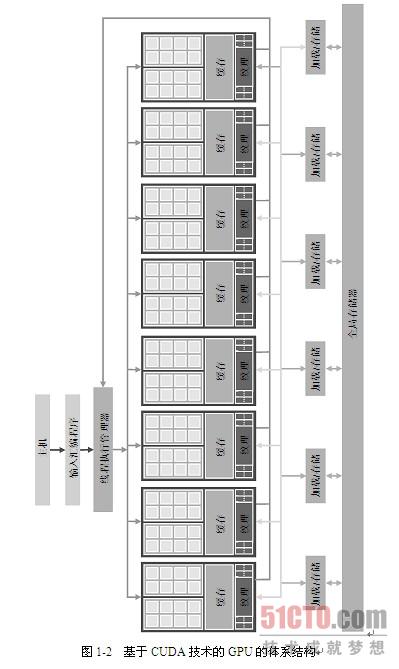
图1-2是一个基于CUDA技术的典型GPU体系结构。这种体系结构由一个高度线程化的多核流处理器(Streaming Multiprocessor,SM)阵列组成。在图1-2中,两个SM形成一个构建块,然而,在基于CUDA技术的GPU的每一代之间,每个构建块中SM的数量可能不同。此外,图1-2中的每个SM又包含多个流处理器(Streaming Processor,SP),它们之间共享控制逻辑和指令缓存。每个GPU都带有若干千兆字节(GB)的图形双数据速率(Graphics Double Data Rate,GDDR)DRAM,在图1-2中称为全局存储器(global memory)。GPU中的这些GDDR DRAM完全不同于CPU体系中安装在主板上的系统DRAM,它们主要是用于图形处理的帧缓冲区存储器。在图形应用程序中,它们用来保存视频图像和用于3D渲染的纹理信息;而对于计算,它们可以作为带宽芯片外存储器。尽管比典型系统存储器的延迟要长,大规模并行应用程序通常通过高带宽来弥补时延。
采用CUDA体系结构的G80系列芯片,其存储器带宽可以达到86.4GB/s,并通过第二代PCI Express总线接口与CPU之间进行通信。CUDA应用程序从系统内存中传输数据的带宽和将数据上传回系统内存中的带宽都可以达到4GB/s,从而使得总带宽可以达到8GB/s。最新的GPU已经开始使用第三代PCI Express,这使得单个方向上的带宽达到了8GB/s。随着GPU存储容量的扩大,应用程序所需的数据基本能够保存在全局存储器(global memory)中,只有当调用只能在CPU上使用的例程库时,才需要与CPU端系统内存进行通信。将来在系统内存中CPU总线带宽增长的同时,通信带宽也会随之增长。
GTX680系列芯片支持16 384个线程,双精度浮点运算速度可以达到每秒1.5万亿次(1.5 teraflops)。一个组织良好的应用程序在这种芯片上一次可同时运行5000~12 000个线程。多核CPU也支持多线程,但同时运行的线程数量取决于CPU中内核的数量,如Intel的CPU可以同时运行2个或4个线程。然而,现在的CPU越来越多地使用单指令多数据(Single Instruction, Multiple Data,SIMD)指令,提高数值计算性能。GPU和CPU支持的并行水平越来越高。在开发计算应用程序时,并行水平对性能而言至关重要。
【责任编辑:
book TEL:(010)68476606】
原文:1.2 现代GPU的体系结构
返回读书频道首页








发表评论 取消回复