
前言
本文主要是为了复刻TSN论文中的实验,使用的是UCF101数据集。
1.数据集及源码准备
1.1数据集介绍
在视频分类项目中,有很多经典的公开数据集,目前主要的数据集如列表所示:
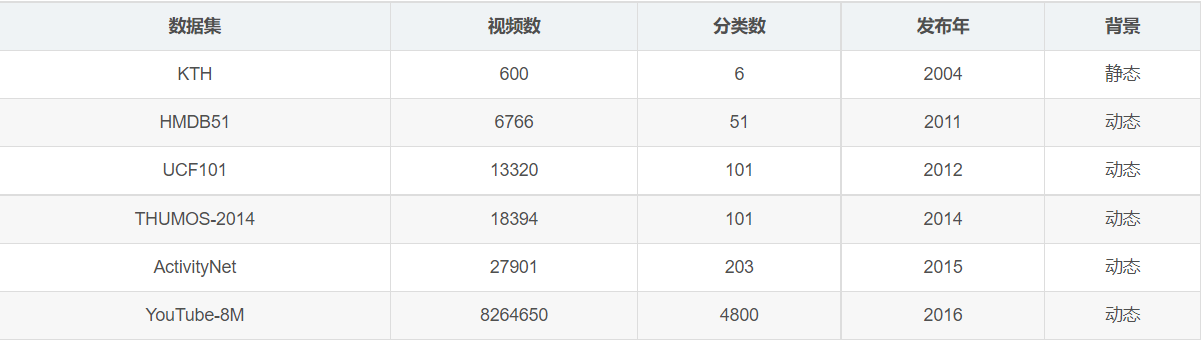
UCF101是动作识别数据集,从Youtube收集而得,共包含101类动作。其中每类动作由25个人做动作,每人做4-7组,共13320个视频,分辨率为320*240。UCF101在动作的采集上具有非常大的多样性,包括相机运行、外观变化、姿态变化、物体比例变化、背景变化、光纤变化等。
主要结构为
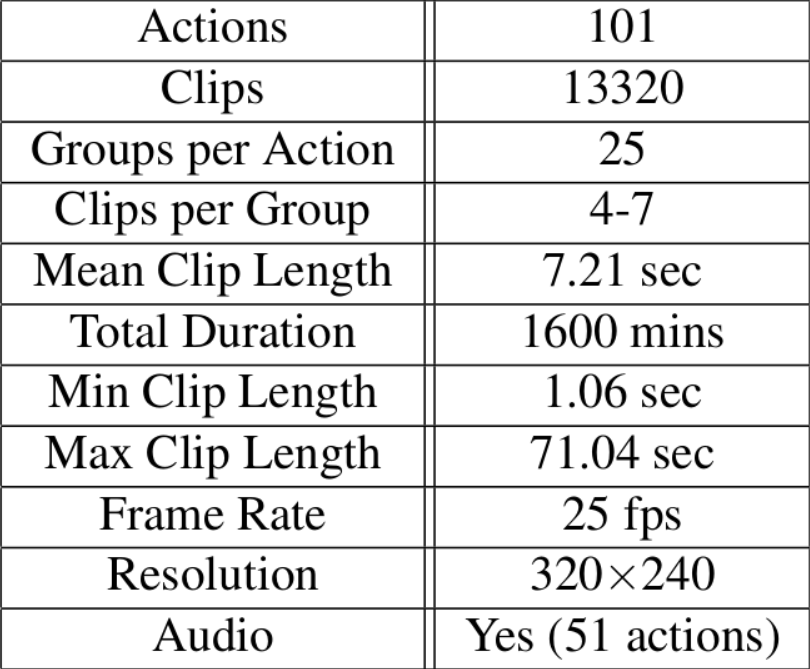
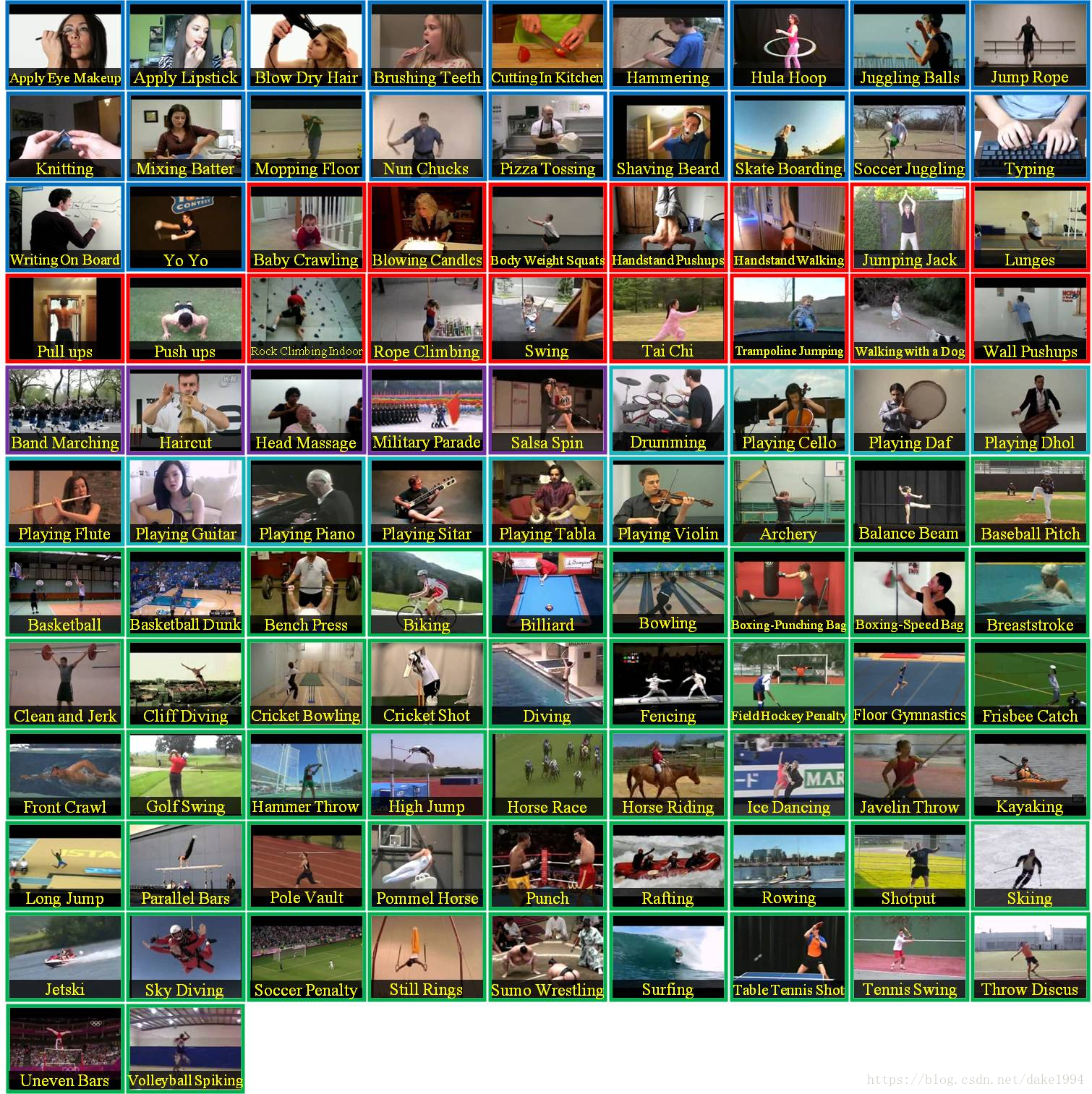
101类动作可以分为5类:人与物体互动、人体动作、人与人互动、乐器演奏、体育运动。
1.2数据集下载
下载地址为: http://www.crcv.ucf.edu/data/UCF101/UCF101.rar
下载成功后文件如下:
下图是UCF101在进行训练和测试时,分割的依据文件:
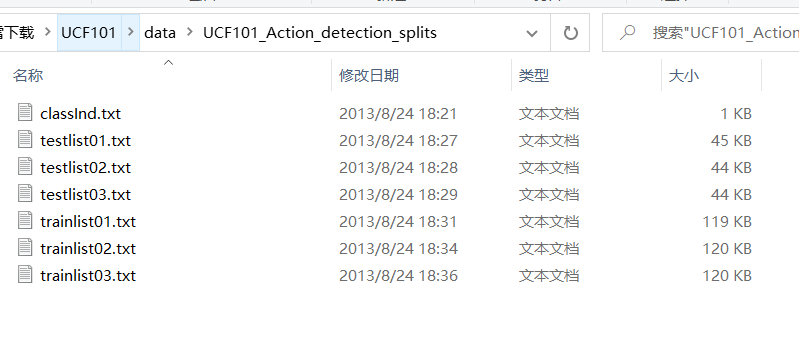
1.3源码下载
直接通过GitHub克隆,在git-cmd中拉入对应的文件夹即可
- 下载mmaction(视频预处理,也可以用mmaction2,内容以及方法差不多):
git clone --recursive https://github.com/open-mmlab/mmaction.git第一次运行需要安装一些工具包,跟着提示安装就行,如安装mmcv
pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu102/torch1.9.0/index.html
- 下载tsn-pytorch:
git clone --recursive https://github.com/yjxiong/tsn-pytorch2.数据处理
在笔记本电脑上跑由于数据过大会报“页面太小”“memoryerror”错误,可以放到算力平台上操作。
2.1提帧
在我们下载好的UCF101数据集中,视频大多是长时间的,很难对其进行动作识别,所以需要进行提帧操作。
文件框架如下:
data文件夹放置的是数据集:
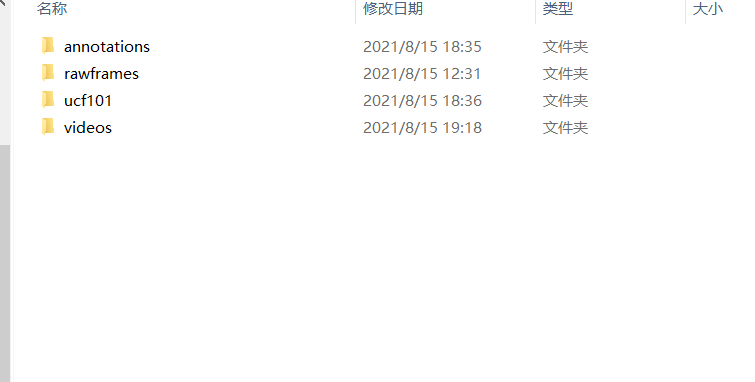
- rawframes:视频提帧后存放的文件目录
- videos:拷贝ucf101数据集中的101个文件目录(本次只拷贝了前8个),放置其中
- annotations:ucf101之后进行分割训练集、测试集的依据文件
- ucf101:存放训练集测试集划分过后的信息
然后在mmaction/data_tools/build_rawframes.py 就是进行视频提帧的代码文件,
在路径..mmactiondata_tools下输入如下命令(地址根据自己data文件的地址自行更改):
python build_rawframes.py ../../data/videos ../../data/rawframes/ --level 2 --ext avi提帧过程如下:

提帧结果如下:
打开第一个文件夹

运行完成后,每一个视频的每一帧会提取出来,放在相应名称的文件夹中。
2.2 生成file_list
命令行中输入一下代码:
python data_tools/build_file_list.py ucf101 ../data/rawframes/ --level 2 --format rawframes --shuffleucf101是数据集类型,后面地址是提帧过后保存的图片
过程如下:

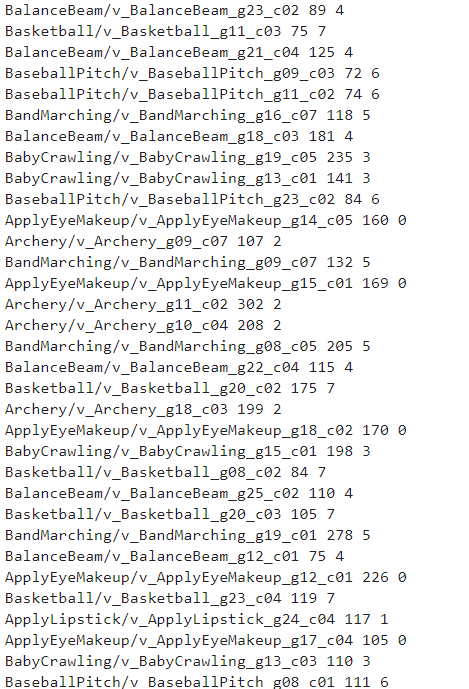
最后会在指定文件夹生成如下file-list
打开后是如下形式(本次实验有8类动作,所有最后数字也有8种)
3.训练部分
3.1修改代码
在ucf101类别中,原本代码是101,我们这里复现只使用ucf101中的前15个类型,所以将代码修改为
if args.dataset == 'ucf101'
num_class = 8
在TSNDataSet中,为了更好的找到对应文件的位置,将args.train_list和args.val_list(这两个输入字符串就是之前生成的file_list的绝对路径)写成指定字符串的形式,所以将代码修改为
train_loader = torch.utils.data.DataLoader(
TSNDataSet("/openbayes/home/Tsn/data/", "/openbayes/home/Tsn/data/ucf101/ucf101_train_split_1_rawframes.txt", num_segments=args.num_segments,
new_length=data_length,
modality=args.modality,
image_tmpl="img_{:05d}.jpg" if args.modality in ["RGB", "RGBDiff"] else args.flow_prefix+"{}_{:05d}.jpg",
transform=torchvision.transforms.Compose([
train_augmentation,
Stack(roll=args.arch == 'BNInception'),
ToTorchFormatTensor(div=args.arch != 'BNInception'),
normalize,
])),
batch_size=args.batch_size, shuffle=True,
num_workers=args.workers, pin_memory=True)同理
val_loader = torch.utils.data.DataLoader(
TSNDataSet("/openbayes/home/Tsn/data/", "/openbayes/home/Tsn/data/ucf101/ucf101_val_split_1_rawframes.txt", num_segments=args.num_segments,
new_length=data_length,
modality=args.modality,
image_tmpl="img_{:05d}.jpg" if args.modality in ["RGB", "RGBDiff"] else args.flow_prefix+"{}_{:05d}.jpg",
random_shift=False,
transform=torchvision.transforms.Compose([
GroupScale(int(scale_size)),
GroupCenterCrop(crop_size),
Stack(roll=args.arch == 'BNInception'),
ToTorchFormatTensor(div=args.arch != 'BNInception'),
normalize,
])),
batch_size=args.batch_size, shuffle=False,
num_workers=args.workers, pin_memory=True)同样还需要对datasets.py中的路径进行修改,
def get(self, record, indices):
images = list()
for seg_ind in indices:
p = int(seg_ind)
for i in range(self.new_length):
seg_imgs = self._load_image('/openbayes/home/Tsn/data/rawframes/'+ record.path, p)
images.extend(seg_imgs)
if p < record.num_frames:
p += 1
process_data = self.transform(images)
return process_data, record.label3.2 TSN训练
在tsn-pytorch/打开命令行,输入命令:
python main.py ucf101 RGB /openbayes/home/Tsn/data/ucf101/ucf101_train_split_1_rawframes.txt /openbayes/home/Tsn/data/ucf101/ucf101_val_split_1_rawframes.txt --arch BNInception --num_segments 7 --gd 40 --lr 0.001 --lr_steps 80 160 --epochs 100 -b 8 -j 8 --dropout 0.8 --snapshot_pref ucf101_bninception
运行命令,命令行打印训练过程和结果并且保存训练好的模型文件:

可以看到 epoch=15左右,准确率基本恒定在100%,

最终结果也是准确率100%
4.测试部分
测试部分需要对test_model.py文件进行运行,但是需要针对自己的情况进行修改才可以成功运行。
将原本的test_segment=25,修改为test_segment=5,即将视频分为5段,减少数据量
parser.add_argument('--test_segments',type=int,default=5)同理,总共有8种类别,
if args.dataset == 'ucf101'
num_class = 8由于我们只有单GPU,实行不了多GPU并行,所以将device_ids=[0,],只进行单GPU运行
net = torch.nn.DataParallel(net.cuda(devices[0]),device_ids=[0,])
4.2 TSN测试
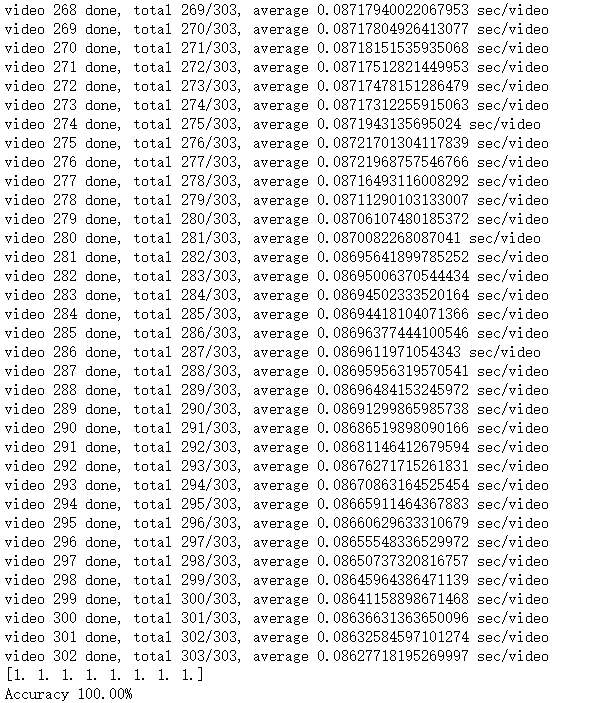
python test_models.py ucf101 RGB ../data/ucf101/ucf101_val_split_3_rawframes.txt ucf101_bninception_rgb_checkpoint.pth.tar --arch BNInception其中ucf101_bninception_rgb_checkpoint.pth.tar是训练过程生成的模型文件。
过程如下:
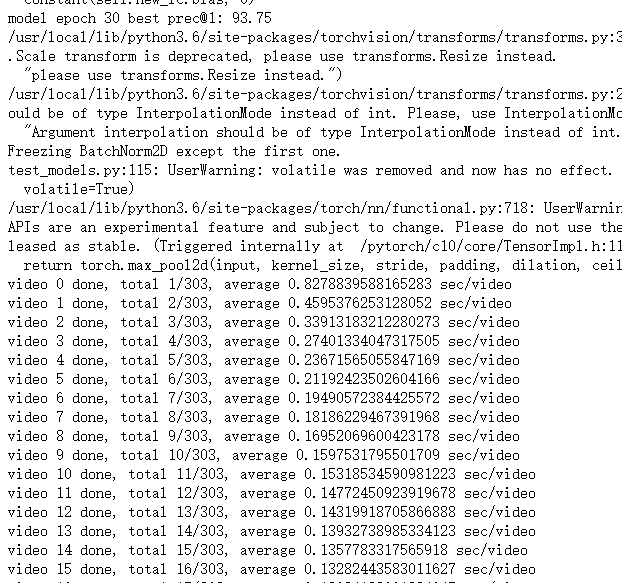
观察命令行可以看到,最后的测试准确率为100%。
5.实验过程中的问题
1.电脑跑不动,可以将代码放到算力平台里面去跑。
2.运行main.py文件时出现错误:size mismatch for Conv2_ 3x3_ bn. weight: copying a
param with shape torch. Size([1, 192]) from checkpoint, the shape
in current model is torch. size([192]).
解决方案:替换base_model模型为resnet,因为该源码与BnInception的网络结构输入不符合。
3.调用父模块中的子模块的子模块,用sys.path解决
4.FileNotFoundError: [Errno 2] No such file or directory: 'ucf101_val_split_3_rawframes.txt'等各种文件路劲问题,使用绝对路径,并且将数据集配置文档等放在data方便管理。
5.test_model时显示模型参数数组越界,之前生成模型ucf101_bninception_rgb_checkpoint.pth.tar没有及时删除,导致读取模型读取上一次的数据,造成数组越界,删除之前模型。
最后
以上就是有魅力信封最近收集整理的关于TSN实验过程 前言1.数据集及源码准备2.数据处理3.训练部分 4.测试部分5.实验过程中的问题的全部内容,更多相关TSN实验过程 前言1.数据集及源码准备2.数据处理3.训练部分 4.测试部分5.实验过程中内容请搜索靠谱客的其他文章。








发表评论 取消回复