转载自:Here are 17 ways of making PyTorch training faster-what did I miss?
按加速程度从大到小的大致排序为:
- 使用不同学习率的schedule;
- 在DataLoader中:使用多个worker&使用pin memory;
- 最大化batch size;
- 使用自动混合精度(AMP);
- 使用不同的优化器optimizer;
- 打开cudnn benchmark;
- 避免CPU和GPU之间频繁传输数据;
- 使用梯度/激活checkpointing;
- 使用累计梯度;
- 使用DistributedDataParallel进行多GPU训练;
- 设置梯度为None(而不是0);
- 使用 .as_tensor()(而不是.tensor());
- 关掉不必要的debugging API;
- 使用gradient clipping;
- BatchNorm前设置:bias=False;
- 在验证阶段关闭梯度计算;
- 输入归一化&批量标准化;
1 使用不同学习率的schedule
学习率会影响模型的收敛速度&&泛化性能。这里推荐两种:
(1)Cyclical learning rate
torch.optim.lr_scheduler.CyclicLR()
参考:Cyclical Learning Rates for Training Neural Networks
(2)1Cycle learning rate
torch.optim.lr_scheduler.OneCycleLR()
其schedule如下图:
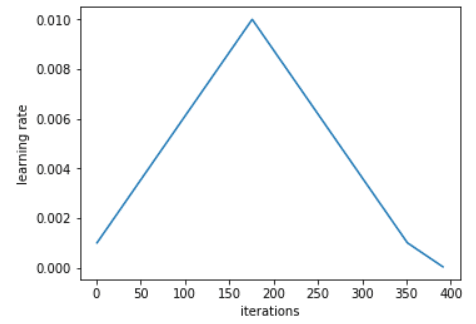
- 1Cycle包含两个等长的步骤:①从一个较小的学习率增加到一个较大的学习率(1-175 epoch);②从较大的学习率回到小的学习率(175-350 epoch);
- 学习率的较大值是由Learning Rate Finder选取;
- 较大值 = 10*较小值;
- 两个等长步骤加起来的迭代次数略小于总的epoch数,且在最后几个epoch中,学习率可比较小值还小几个数量级。
参考:Super-Convergence:Very Fast Training of Neural Networks Using Large Learning Rates
缺点
上述scheduler的缺点是:引入了额外的超参数。关于这些超参数的选取可以参考:Hyper-parameter Tuning Techniques in Deep Learning和Pytorch LR finder。
至于为什么上述scheduler可以加速训练,有一种可能的解释是:定期提高学习率有助于更快地遍历loss的鞍点。
2 在DataLoader中:使用多个worker&使用pin memory
当使用torch.utils.data.DataLoader时,设置num_workers > 0以及pin_memory=True。
num_workers的选取
经验法则:可用GPU数量的4倍。
过多或过少的worker都会导致速度变慢。
缺点
增加worker的数量会增加CPU内存消耗(worker加载数据到RAM的进程是CPU复制)。
3 最大化batch size
这是一个比较有争议的做法。参考:An Empirical Model of Large-Batch Training和How to get 4× speedup and better generalization using the right batch size
注意
当修改batch size时,需要对其他超参数(譬如学习率)进行调整。
经验法则:当batch size翻倍时,学习率也翻倍。
缺点
降低泛化性能。
4 使用自动混合精度(AMP)
与单精度相比,某些运算在半精度下运行更快,而不会损失准确率。AMP 会自动决定应该以哪种精度执行哪种运算,这样既可以加快训练速度,又可以减少内存占用。
import torch
# Creates once at the beginning of training
scaler = torch.cuda.amp.GradScaler()
for data, label in data_iter:
optimizer.zero_grad()
# Casts operations to mixed precision
with torch.cuda.amp.autocast():
loss = model(data)
# Scales the loss, and calls backward()
# to create scaled gradients
scaler.scale(loss).backward()
# Unscales gradients and calls
# or skips optimizer.step()
scaler.step(optimizer)
# Updates the scale for next iteration
scaler.update()
关于其作用原理可以参考Tensor Layouts In Memory:NCHW vs NHWC。
注意
使用AMP有某些限制,例如其现在仅限于CUDA操作,具体参考:Autocast Op Reference。
5 使用不同的优化器optimizer
用torch.optim.AdamW代替torch.optim.Adam:前者使用weight decay而非L2正则化,其在误差和训练时间方面都优于后者。
参考:AdamW and Super-convergence is now the fastest way to train neural nets
其他的非本地优化器(not-yet-native optimizer)还有:LARS、LAMB。
6 打开cudnn benchmark
如果模型架构是固定的&&输入大小不变,则可以设置torch.backends.cudnn.benchmark = True。
其启用了 cudNN autotuner,对 cudNN 中计算卷积的多种不同方法进行基准测试,然后使用最快的方法。
参考:pytorch docs: torch.backends.cudnn
注意
如果batch size过大,则这种自动调整可能会变得很慢。
7 避免CPU和GPU之间频繁传输数据
- 避免频繁地使用
tensor.cpu()将张量从 GPU 转到 CPU或者使用tensor.cuda()将张量从 CPU 转到 GPU; - 用
detach()代替.item()和.numpy(); - 创建新张量时,可以使用
device=torch.device('cuda:0')将其直接分配给 GPU; - 若需要传输数据,而且传输之后没有同步点,则可以使用.
to(non_blocking=True)。
8 使用梯度/激活checkpointing
checkpointing牺牲计算,换取内存:不使用checkpointing时,计算机会存储整个计算图中的所有中间激活用于反向计算;而checkpointed part不保存中间激活,而是在反向传播中重新计算它们。checkpointing可以应用于模型的任何部分。
在前向传播中,checkpointing将以torch.no_gard()方式运行,即不存储中间节点,而是保存输入元组和函数参数。在反向传播中,检索保存的输入和函数,再次在函数上计算前向传播,此时追踪中间激活,然后再使用这些激活值计算梯度。
综上,checkpointing可能会稍微增加运行时间,但是因为减少了内存占用,batch size有了增大空间,从而提高GPU的利用率。
用torch.utils.checkpoint可以实现checkpointing,但是正确使用它是不容易,参考:checkpointing for PyTorch models
9 使用累计梯度
其可以视作一种增加batch size的方式:在调用 optimizer.step() 之前累积多个. backward() 传播中的梯度。
model.zero_grad() # Reset gradients tensors
for i, (inputs, labels) in enumerate(training_set):
predictions = model(inputs) # Forward pass
loss = loss_function(predictions, labels) # Compute loss function
loss = loss / accumulation_steps # Normalize our loss (if averaged)
loss.backward() # Backward pass
if (i+1) % accumulation_steps == 0: # Wait for several backward steps
optimizer.step() # Now we can do an optimizer step
model.zero_grad() # Reset gradients tensors
if (i+1) % evaluation_steps == 0: # Evaluate the model when we...
evaluate_model() # ...have no gradients accumulate
注意
该方法主要是为了避免GPU内存受限,但它实际中可以加速训练。
10 使用DistributedDataParallel进行多GPU训练
加速分布式训练的方法:用torch.nn.DistributedDataParallel替代torch.nn.DataParallel,使得每个GPU由专用的CPU内核驱动,避免了后者的GIL问题。
参考:PYTORCH DISTRIBUTED OVERVIEW
GIL(global interpreter lock)问题
早期cpython(python最主要的解释器)为了实现多线程的功能,提高CPU利用率,“无脑”使用了GIL机制(全局锁)来解决线程之间数据同步问题(历史问题埋下的坑)。
在GIL的机制下,正常的CPU切换步骤中,在线程获得cpu时间片后,还需要获得GIL才能够执行。
在单核时代,这种机制是行得通的:因为只有在GIL释放之后才会触发OS的线程调度,那么这时候其它线程势必能够获取GIL,实现线程的切换执行。
但在多核情况下:因为只有一把大锁GIL,在多核架构下的线程调度,就会出现:虽然线程获得了cpu时间片,然而却没有得到GIL,只好白白浪费CPU时间片,然后等待切换进入等待,等待下一次被唤醒,如此恶性循环。那么在任何时候,只能有一个线程在执行,也就是说只有一个CPU核心真正执行代码。
11 设置梯度为None(而不是0)
用.zero_grad(set_to_none=True)替代.zero_grad:让内存分配器处理梯度,而不是主动将它们设置为0。
这可以小幅实现加速,但其也有副作用。具体参考:TORCH.OPTIM DOCS
12 使用 .as_tensor()(而不是.tensor())
将numpy array转化tensor时:torch.tensor()会复制数据,而torch.as_tensor()或者torch.from_numpy不会!
13 关掉不必要的debugging API
PyTorch 提供了许多有用的调试工具,例如 autograd.profiler、autograd.grad_check 和 autograd.anomaly_detection。
在需要时使用它们!但在不需要它们时要关闭它们,否则会减慢训练速度。
14 使用gradient clipping
gradient clipping可以大致理解为:gradient = min(gradient, threshold)。其最初是被用于避免 RNN 中的梯度爆炸的问题,但是有一些经验和理论表明其可以加速收敛:torch.nn.utils.clip_grad_norm_()。
参考:Why Gradient Clipping Accelerates Training: A Theoretical Justification for Adaptivity
gradient clipping对不同模型的加速效果不确定,但它似乎对 RNN、基于 Transformer 和 ResNets 架构以及一系列不同的优化器非常有用。
15 BatchNorm前设置:bias=False
在二维卷积中:torch.nn.Conv2d(..., bias=False, ...)。
其作用原理参考:Can not use both bias and batch normalization in convolution layers
该方法可以节约参数,但加速效果比较小。
16 在验证阶段关闭梯度计算
验证阶段设置torch.no_grad()。
17 输入归一化&批量标准化
二者都可以参考官方文档。
其解释可以参考:In Machine learning, how does normalization help in convergence of gradient descent?
18 补充:使用 JIT 融合point-wise操作
如果有相邻的逐点操作,可以使用 PyTorch JIT 将它们组合成一个 FusionGroup,然后可以在单个内核上启动,而不是像默认情况下那样在多个内核上启动。这样可以节省一些内存读取和写入。
其使用可以参考:PYTORCH PERFORMANCE TUNING GUIDE、Optimizing CUDA Recurrent Neural Networks with TorchScript
最后
以上就是火星上冬天最近收集整理的关于加速Pytorch训练的全部内容,更多相关加速Pytorch训练内容请搜索靠谱客的其他文章。








发表评论 取消回复