版本说明: paddlepaddle 1.8.4
可视化paddle学习率列表
- cosine_decay
- piecewise_decay
- exponential_decay
- natural_exp_decay
- inverse_time_decay
- polynomial_decay
- linear_lr_warmup
- noam_decay
- 附录:代码实现
- OneCycleLR复现
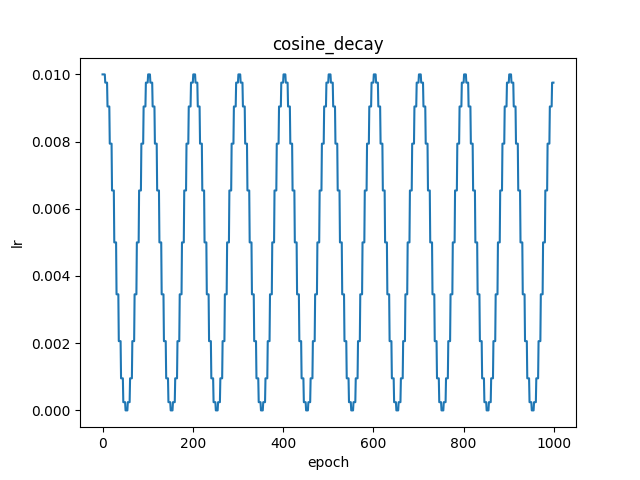
cosine_decay
paddlepaddle官网实现原理说明
fluid.layers.cosine_decay(learning_rate, step_each_epoch, epochs)
piecewise_decay
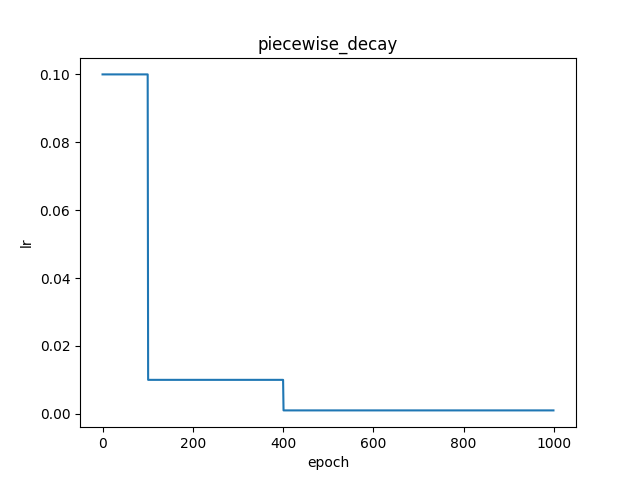
paddlepaddle官网实现原理说明
fluid.layers.piecewise_decay(boundaries, values)
exponential_decay
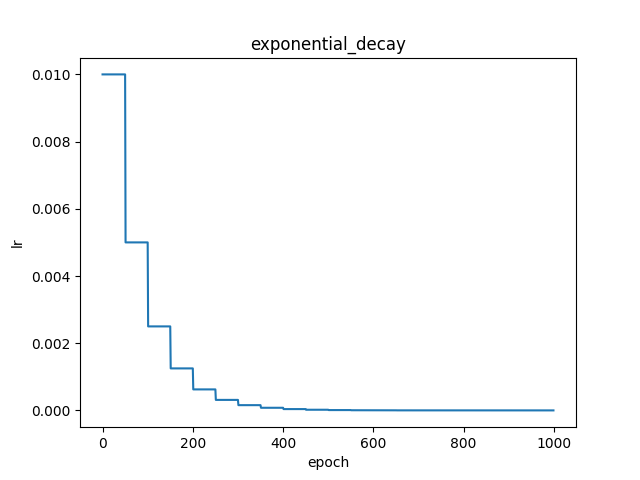
paddlepaddle官网实现原理说明
fluid.layers.exponential_decay(learning_rate, decay_steps, decay_rate, staircase=False)
natural_exp_decay
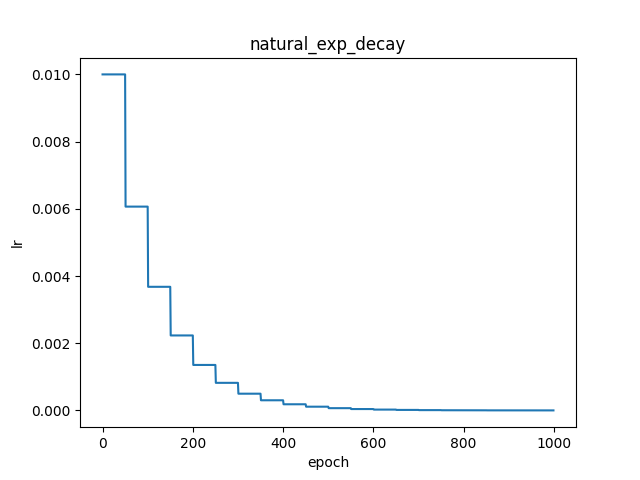
paddlepaddle官网实现原理说明
fluid.layers.natural_exp_decay(learning_rate, decay_steps, decay_rate, staircase=False)
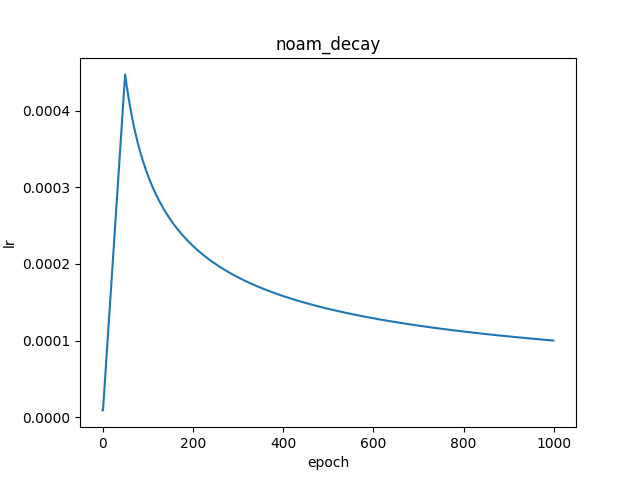
inverse_time_decay
paddlepaddle官网实现原理说明
fluid.layers.inverse_time_decay(learning_rate, decay_steps, decay_rate, staircase=False)
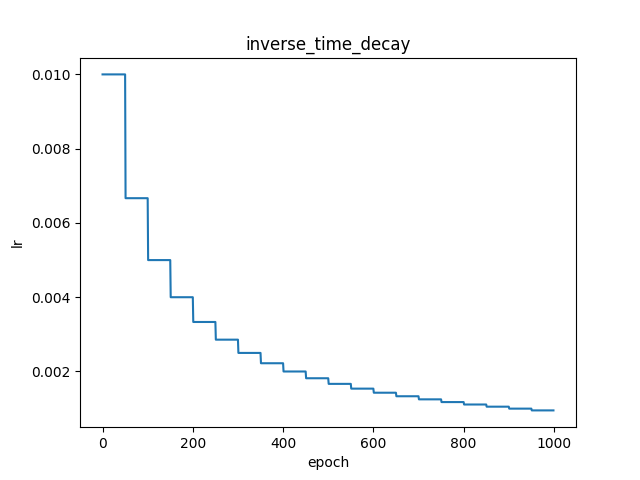
polynomial_decay
paddlepaddle官网实现原理说明
fluid.layers.polynomial_decay(learning_rate, decay_steps, end_learning_rate=0.0001, power=1.0, cycle=False)
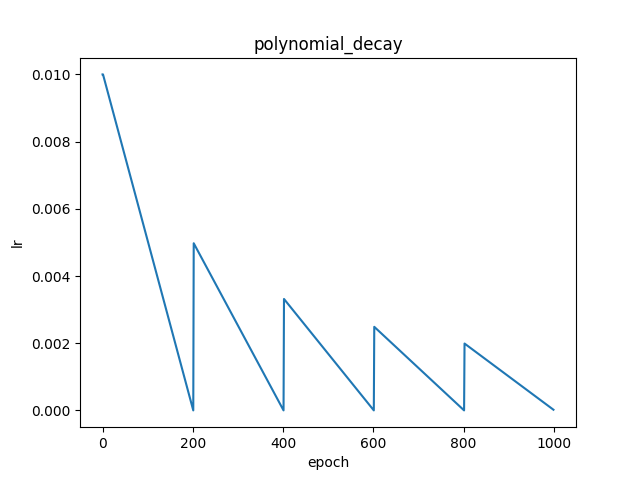
linear_lr_warmup
paddlepaddle官网实现原理说明
fluid.layers.linear_lr_warmup(learning_rate, warmup_steps, start_lr, end_lr)
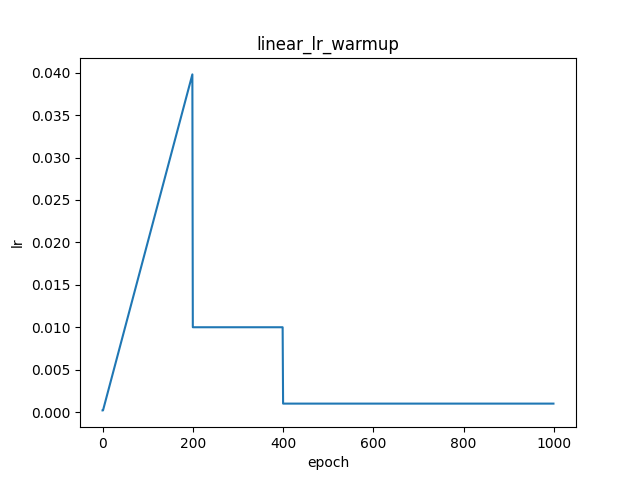
noam_decay
paddlepaddle官网实现原理说明
fluid.layers.noam_decay(d_model, warmup_steps)
附录:代码实现
import paddle.fluid as fluid
import numpy as np
import matplotlib.pyplot as plt
with fluid.dygraph.guard(fluid.CPUPlace()):
epochs = 1000
loss = fluid.layers.cast(fluid.dygraph.to_variable(np.array([0.18])), 'float32')
emb = fluid.dygraph.Embedding([10, 10])
# learning_rate = fluid.layers.noam_decay(10, 50, 0.01)
# learning_rate = fluid.layers.cosine_decay(
# learning_rate = 0.01, step_each_epoch=5, epochs=10)
# boundaries = [100, 400]
# lr_steps = [0.1, 0.01, 0.001]
# learning_rate = fluid.layers.piecewise_decay(boundaries, lr_steps)
# learning_rate = fluid.layers.exponential_decay(
# learning_rate=0.01,
# decay_steps=50,
# decay_rate=0.5,
# staircase=True)
# learning_rate = fluid.layers.natural_exp_decay(
# learning_rate=0.01,
# decay_steps=50,
# decay_rate=0.5,
# staircase=True)
# learning_rate = fluid.layers.inverse_time_decay(
# learning_rate=0.01,
# decay_steps=50,
# decay_rate=0.5,
# staircase=True)
# learning_rate = fluid.layers.polynomial_decay(
# 0.01, 200, 0.01 * 0.00001, power=1, cycle=True)
boundaries = [100, 400]
lr_steps = [0.1, 0.01, 0.001]
learning_rate = fluid.layers.piecewise_decay(boundaries, lr_steps)
learning_rate = fluid.layers.linear_lr_warmup(learning_rate,
200, 0.01, 0.05)
name = 'linear_lr_warmup'
optimizer = fluid.optimizer.SGDOptimizer( learning_rate = learning_rate,
parameter_list = emb.parameters())
lr_list = []
for i in range(epochs):
lr_list.append(optimizer.current_step_lr())
optimizer.minimize(loss)
# print(i, ': ', optimizer.current_step_lr())
# 画出lr的变化
plt.plot(list(range(epochs)), lr_list)
plt.xlabel("epoch")
plt.ylabel("lr")
plt.title(name)
plt.savefig(name + ".png")
plt.show()
OneCycleLR复现
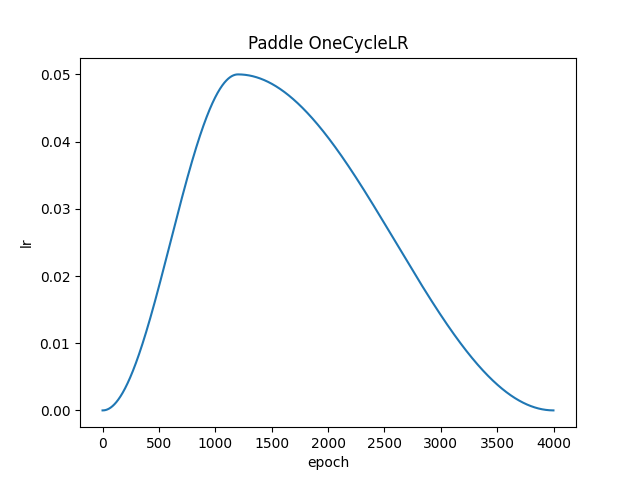
from paddle.fluid.dygraph.learning_rate_scheduler import LearningRateDecay
import math
class OneCycleLR(LearningRateDecay):
def __init__(self,
max_lr,
total_steps=None,
steps_per_epoch=1,
pct_start=0.3,
anneal_strategy='cos',
cycle_momentum=True,
base_momentum=0.85,
max_momentum=0.95,
div_factor=25.,
final_div_factor=1e4,
last_epoch=-1):
super(OneCycleLR, self).__init__(last_epoch)
self.total_steps = total_steps
self.step_size_up = float(pct_start * self.total_steps) - 1
self.step_size_down = float(self.total_steps - self.step_size_up) - 1
self.last_epoch = last_epoch
self.learning_rate = max_lr
def _annealing_cos(self, start, end, pct):
"Cosine anneal from `start` to `end` as pct goes from 0.0 to 1.0."
cos_out = math.cos(math.pi * pct) + 1
return end + (start - end) / 2.0 * cos_out
def step(self):
down_step_num = self.step_num - self.step_size_up
a = self._annealing_cos(self.learning_rate * 0.00001, self.learning_rate, self.step_num / self.step_size_up)
b = self._annealing_cos(self.learning_rate, self.learning_rate * 0.00001, down_step_num / self.step_size_down)
if self.step_num < self.step_size_up:
lr_value = a
else:
lr_value = b
return lr_value
最后
以上就是兴奋路灯最近收集整理的关于paddle复现pytorch踩坑(十二):可视化paddle各种学习率及OneCycleLR复现cosine_decaypiecewise_decayexponential_decaynatural_exp_decayinverse_time_decaypolynomial_decaylinear_lr_warmupnoam_decay附录:代码实现OneCycleLR复现的全部内容,更多相关paddle复现pytorch踩坑(十二)内容请搜索靠谱客的其他文章。








发表评论 取消回复