文章目录
- 1. 为什么需要使用GPU
- 2. GPU为什么性能高
- 3. 如何运用GPU进行编程
- 3.1 NVIDIA GPU Architecture
- 3.2 Thread Hierarchy
- 3.3 Execution Model
- 3.4 kernel function
- 4. An example: Matrix Multiplication
1. 为什么需要使用GPU
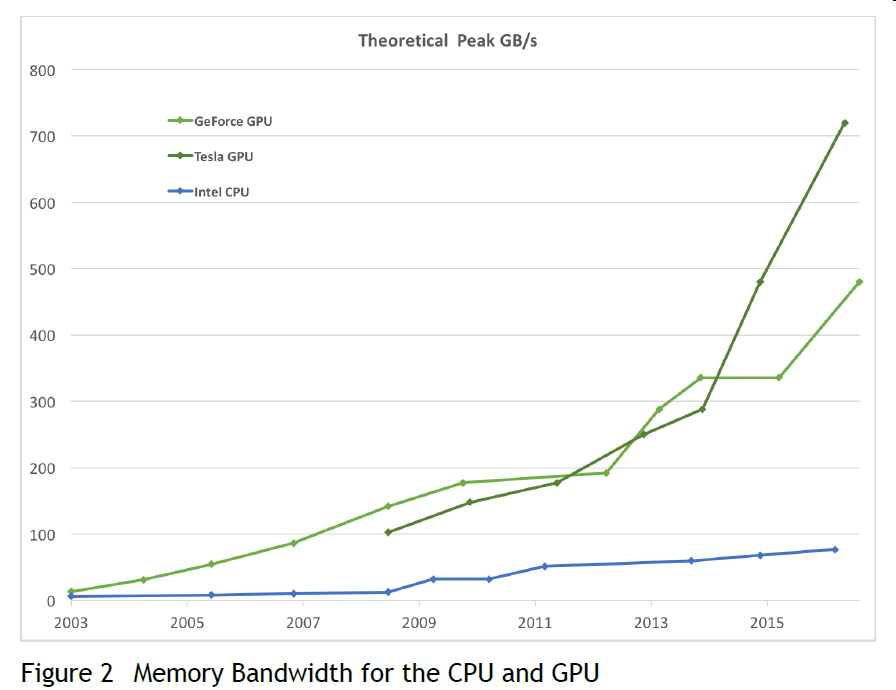
为什么GPU(Graphics Processing Unit)编程越来越流行,主要是因为GPU相对于CPU的运算速度,内存带宽均有较大的优势,下面是摘自《CUDA C PROGRAMMING GUIDE》中的图片:
浮点数运算速度:
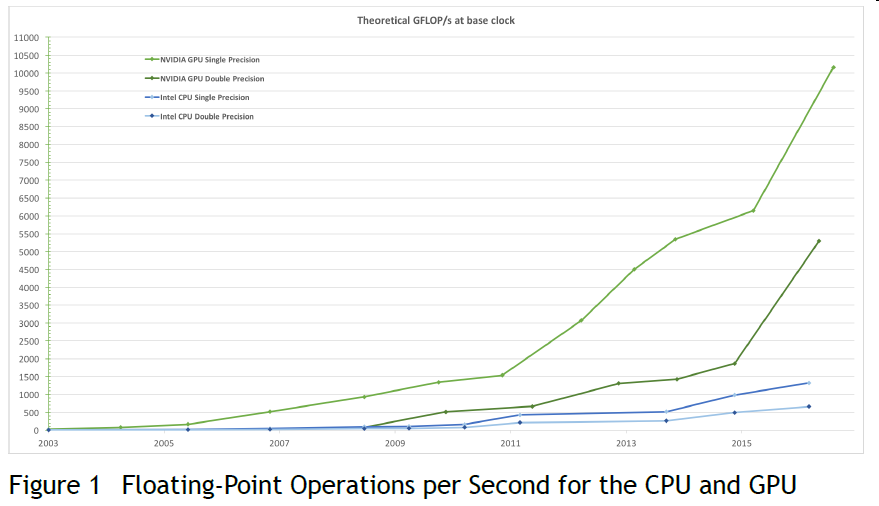
内存带宽:
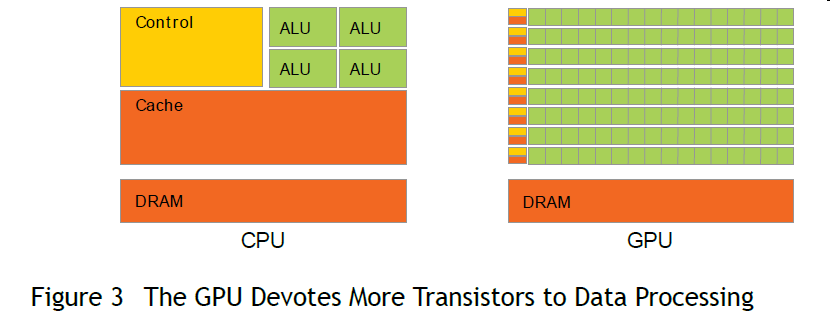
2. GPU为什么性能高
这是因为GPU中硬件更多的用于data processing而不是data caching 或 flow control
NVIDIA GPU 更是采用了SIMT (Single-Instruction, Multiple-Thread)和Hardware Multithreading 技术来进行计算加速:
-
SIMT 相对于SIMD(Single Instruction, Multiple Data),前者主要采用线程并行的方式,后者主要采用数据并行的方式。
下面是一个采用SIMD进行运算的例子:void add(uint32_t *a, uint32_t *b, uint32_t *c, int n) { for(int i=0; i<n; i+=4) { //compute c[i], c[i+1], c[i+2], c[i+3] uint32x4_t a4 = vld1q_u32(a+i); uint32x4_t b4 = vld1q_u32(b+i); uint32x4_t c4 = vaddq_u32(a4,b4); vst1q_u32(c+i,c4); } }下面是一个SIMT的例子:
__global__ void add(float *a, float *b, float *c) { int i = blockIdx.x * blockDim.x + threadIdx.x; a[i]=b[i]+c[i]; //no loop! } -
Hardware Multithreading技术主要是将进程的运行上下文一直保存在硬件上,因而不存在运行上下文切换带来开销的问题(传统的CPU多进程是将进程运行上下文保存在内存中,进程切换时涉及到内存的读取,因而开销较大)
3. 如何运用GPU进行编程
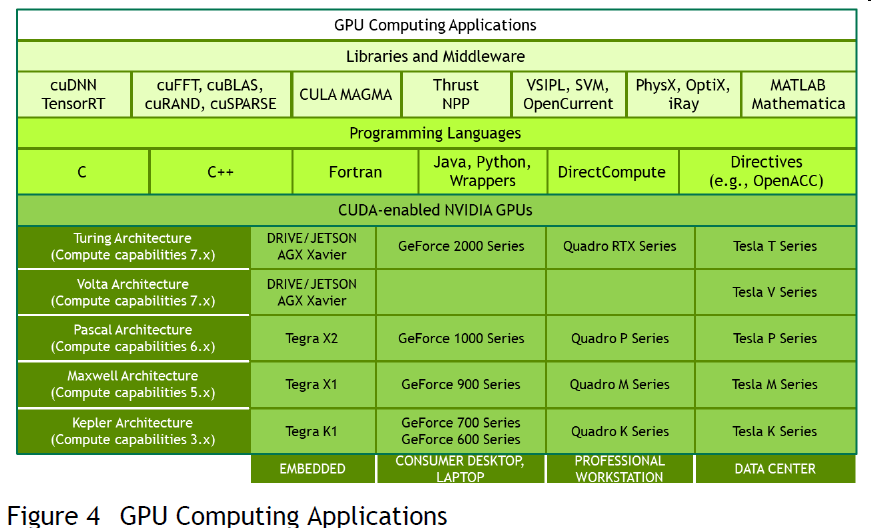
既然GPU有这么多的优势,那么如何使用GPU进行编程呢?由于GPU种类很多,不同的GPU都有不同的硬件实现以及相应的软件接口。目前比较流行的是NVIDIA GPU, 这主要是因为其提供了一套易用的软件接口CUDA, CUDA(Compute Unified Device Architecture)是NVIDIA公司基于其生产的图形处理器GPU开发的一个并行计算平台和编程模型。
3.1 NVIDIA GPU Architecture
NVIDIA GPU的硬件架构一般如下,以GeForce8600 为例:
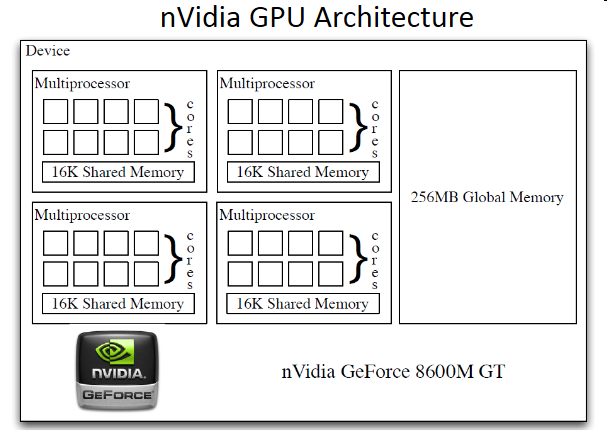
每个GPU中都有多个多流处理器Streaming Multiprocessors(简称SM,有时也直接叫做Multiprocessor), 每个Multiprocessors中有多个core,线程最终就是在这些core上运行的。
这些硬件信息可以通过CUDA Runtime API 获取,例如,我的Lenovo T440P上的GPU硬件信息如下:
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "GeForce GT 730M"
CUDA Driver Version / Runtime Version 10.0 / 10.0
CUDA Capability Major/Minor version number: 3.5
Total amount of global memory: 984 MBytes (1031405568 bytes)
( 2) Multiprocessors, (192) CUDA Cores/MP: 384 CUDA Cores
GPU Max Clock rate: 758 MHz (0.76 GHz)
Memory Clock rate: 1001 Mhz
Memory Bus Width: 64-bit
L2 Cache Size: 524288 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536, 65536), 3D=(4096, 4096, 4096)
Maximum Layered 1D Texture Size, (num) layers 1D=(16384), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(16384, 16384), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 1 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: No
Supports Cooperative Kernel Launch: No
Supports MultiDevice Co-op Kernel Launch: No
Device PCI Domain ID / Bus ID / location ID: 0 / 2 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 10.0, CUDA Runtime Version = 10.0, NumDevs = 1
Result = PASS
该GPU有2个Multiprocessor, 每个multiprocessor有192个core,总计384个core. 对于现在的Tesla型号的GPU,其core数为3584(56 * 64), 每个core都有其相对独立的寄存器等,这是GPU高性能的基础。
3.2 Thread Hierarchy
在NVIDIA GPU编程中,一个多线程的程序会采用分组的方式在GPU上运行,每个组称为一个block,每个block中含有若干个线程。每个thread block在一个Multiprocessor上运行;多个thread blocks可以在一个或多个Multiprocessor上运行。这样做的好处是当增加GPU中Multiprocessor的个数时,程序性能可以随之提高。
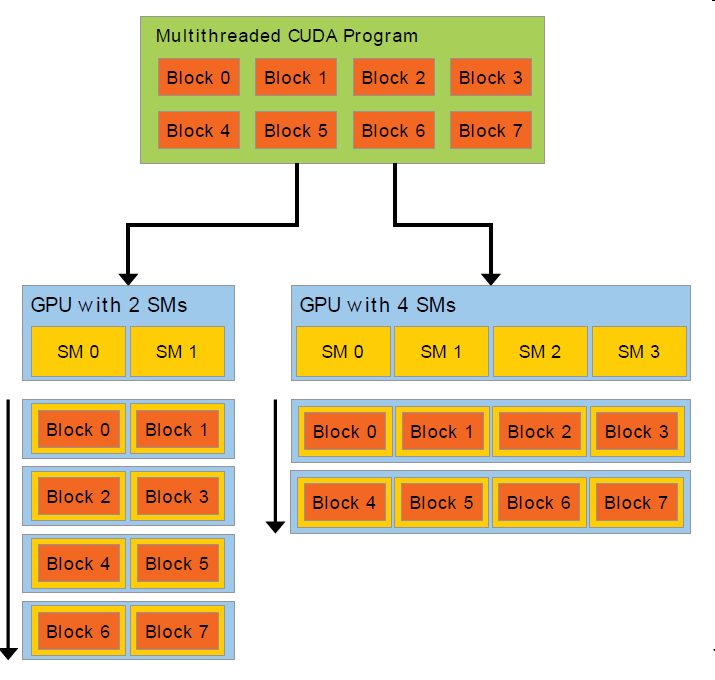
Block在Grid中的排列形式可以是1D或2D(没有3D的block),每个block中有若干线程,这些线程在block中的排列方式可以是1D/2D/3D,如下图:
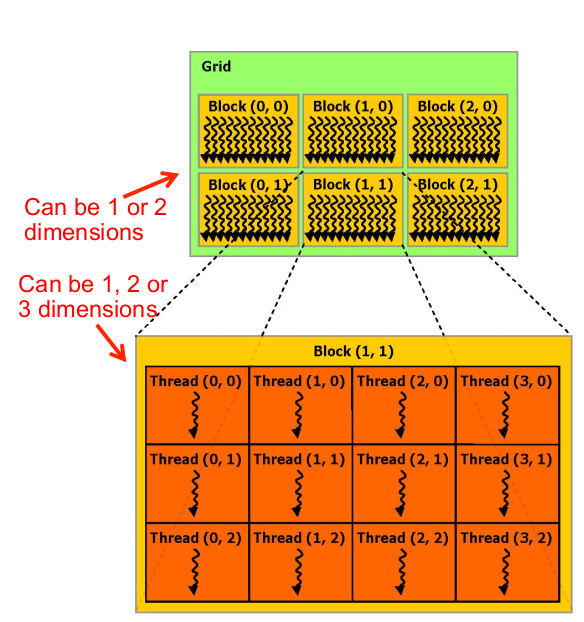
在GPU编程中,相应的概念均可以找到具体的物理实体:
- Grid 对应于GPU,一个GPU就是一个Grid,在多GPU的机器上,将会有多个Grid。
- Block对应(从属于)MultiProcessors这个物理实体
- Thread对应于MultiProcessors下面的core这个物理实体,thread 运行在core上
具体的,当一个block运行在multiprocessor时,multiprocessor是以wrap为单位来调度block中的线程的,一个wrap一般是32个线程,这也就是我们为什么说NVIDIA GPU采用SIMT的原因。wrap是来源于实际生活中的概念(织布中用的经,经纱),下图中所有的竖线即为一个wrap:

对应于上面硬件GeForce GT 730M,其线程相关参数如下:
- 每个Multiprocessor 最多可支持2048个线程;
- 每个thread block中最多可支持1024个线程;
- 每个thread block中维数方面x,y,z分别最多为1024,1024,64
- 每个grid中维数方面x,y,z分别最多为2147483647, 65535, 65535
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
注意这里grid size的z方向虽然最大可以是65535,但是在CUDA的实际编程接口中只能是1.
3.3 Execution Model
采用CUDA编程时,程序的运行步骤一般如下:
1.准备GPU计算数据: 将数据从host内存拷贝到GPU内存
2.在GPU中运行程序
3.将计算结果从GPU内存拷贝到CPU内存
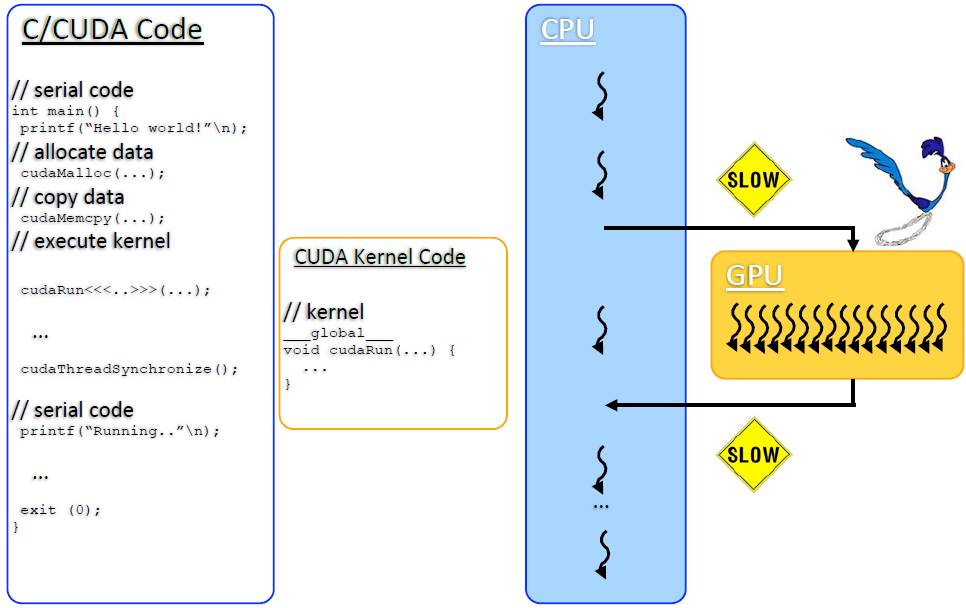 在GPU和CPU混合编程中,通常将GPU叫做device, 将CPU叫做host。如上步骤2中能够在Host端被调用,在device端执行的函数叫kernel function。
在GPU和CPU混合编程中,通常将GPU叫做device, 将CPU叫做host。如上步骤2中能够在Host端被调用,在device端执行的函数叫kernel function。
3.4 kernel function
对于运行在device端的函数,一般以__global__和以__device__ 作为标志。以__device__作为标志的函数只能在device上被调用;以__global__作为标志的函数可以在host端调用,也可以在device端调用,一般称为kernel function, 调用kernel function时我们需要提供两个参数:
- 以block为单位的,在grid内部block在x,y方向(不支持z方向)的维数B
- 以thread为单位的,在block内线程在x,y,z方向的维数T
kernel function调用的一般形式为:
myKernel<<< B, T >>>(arg1, … );
B,T在CUDA中采用如下类似的数据结构dim3:
struct dim3 {x; y; z;};
其提供了int到dim3的隐式类型转换:
myKernel<<< 2, 3 >>>(arg1, … );
上面的参数等价于dim3 b(2,1,1) T(3,1,1)。CUDA为所有在device内运行的function提供了如下两个内置变量gridDim和blockDim:
dim3 gridDim
dim3 blockDim
- 通过gridDim.x,gridDim.y,gridDim.z,获取grid在x,y,z方向的维数,也就是block在grid内部x,y,z方向的个数,gridDim.z始终为1
- 通过blockDim.x,blockDim.y,blockDim.z,获取block在x,y,z方向的维数,也就是线程在block内部x,y,z方向的个数
那么程序中使用到的block数和单个block内部线程总数将分别是:
gridDim.x * gridDim.y*gridDim.z // girdDim.z = 1
blockDim.x * blockDim.y * blockDim.z
对于kernel function的调用,采用的是SIMT的方式,也就是说同一个function的函数指令将会运行在多个线程中,而线程又属于某个block,我们怎么获取这些线程的索引(index)呢? CUDA 提供了两个可以在kernel function内部使用的变量:
uint3 blockIdx
uint3 threadIdx
- 通过blockIdx.x, blockIdx.y获取到当前block在grid内部x,y方向的索引
- 通过threadIdx.x, threadIdx.y, threadIdx.z获取thread在block内部x,y,z方向的索引
对于2D Grid和2D block,线程在x,y方向的全局唯一ID就可以通过如下计算得到:
- x = blockIdx.x * blockDim.x + threadIdx.x;
- y = blockIdx.y * blockDim.y + threadIdx.y;
下面是一个2D Grid和2D block的示意图,:
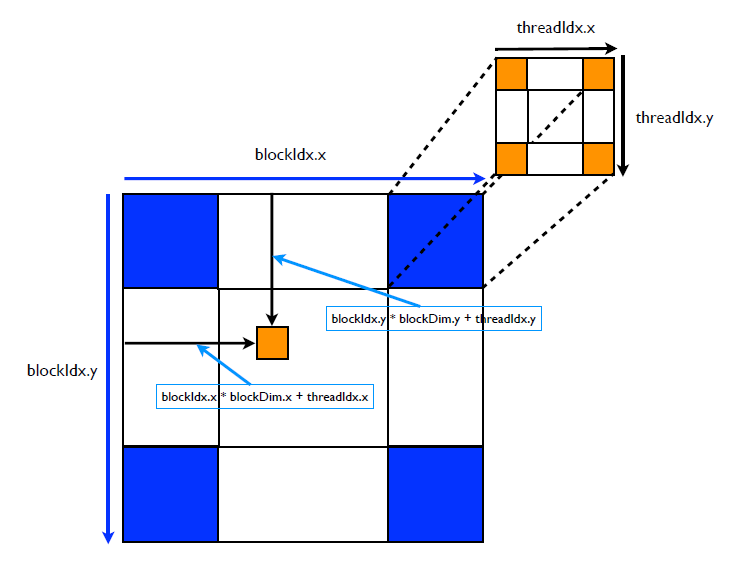
对于2D Grid和3D block的情形,有类似:
- x = blockIdx.x * blockDim.x + threadIdx.x;
- y = blockIdx.y * blockDim.y + threadIdx.y;
- z = blockIdx.z * blockDim.z + threadIdx.z;
注意前面提到过Grid的排列形式没有3D的,只有2D的,也就是说blockIdx.z = 0;
4. An example: Matrix Multiplication
下面通过矩阵相乘的例子来说明采用如何使用GPU进行编程,回忆一下,对于矩阵A,B,矩阵向乘的结果C中的元素是通过如下公式得到:
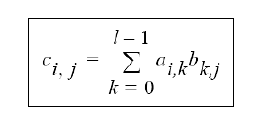
具体计算过程如下:
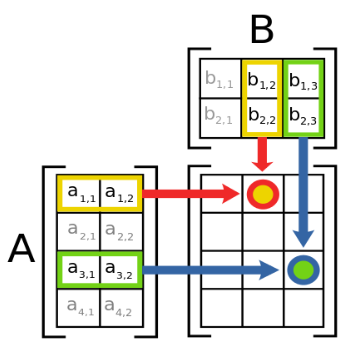
在C中,一般的实现如下:
void matrixMult (int a[N][N], int b[N][N], int c[N][N], int width)
{
for (int i = 0; i < width; i++) {
for (int j = 0; j < width; j++) {
int sum = 0;
for (int k = 0; k < width; k++) {
int m = a[i][k];
int n = b[k][j];
sum += m * n;
}
c[i][j] = sum;
}
}
}
其中,矩阵width是矩阵A的列数,显然,上面算法的复杂度是O(N^3)。采用GPU编程只需将上面的方法写成kernel function的形式:
__global__ void matrixMult (int *a, int *b, int *c, int width) {
int k, sum = 0;
int col = threadIdx.x + blockDim.x * blockIdx.x;
int row = threadIdx.y + blockDim.y * blockIdx.y;
if(col < width && row < width) {
for (k = 0; k < width; k++) {
sum += a[row * width + k] * b[k * width + col];
}
c[row * width + col] = sum;
}
}
对比一下C和GPU实现的线程数量和时间复杂度:
| 线程数量 | 时间复杂度 | |
|---|---|---|
| C | 1 | N^3 |
| GPU | N^2 | N |
较完整的GPU实现代码如下:
#define N 16
#include <stdio.h>
__global__ void matrixMult (int *a, int *b, int *c, int width) {
int col = threadIdx.x + blockDim.x * blockIdx.x;
int row = threadIdx.y + blockDim.y * blockIdx.y;
if(col < width && row < width) {
for (k = 0; k < width; k++) {
sum += a[row * width + k] * b[k * width + col];
}
c[row * width + col] = sum;
}
int main() {
int a[N][N], b[N][N], c[N][N];
int *dev_a, *dev_b, *dev_c;
// initialize matrices a and b with appropriate values
int size = N * N * sizeof(int);
cudaMalloc((void **) &dev_a, size);
cudaMalloc((void **) &dev_b, size);
cudaMalloc((void **) &dev_c, size);
cudaMemcpy(dev_a, a, size, cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, size, cudaMemcpyHostToDevice);
dim3 dimGrid(1, 1);
dim3 dimBlock(N, N);
matrixMult<<<dimGrid, dimBlock>>>(dev_a, dev_b, dev_c, N);
cudaMemcpy(c, dev_c, size, cudaMemcpyDeviceToHost);
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
}
最后
以上就是鲜艳鱼最近收集整理的关于NVIDIA CUDA原理和基础知识1. 为什么需要使用GPU2. GPU为什么性能高3. 如何运用GPU进行编程4. An example: Matrix Multiplication的全部内容,更多相关NVIDIA内容请搜索靠谱客的其他文章。








发表评论 取消回复