2019独角兽企业重金招聘Python工程师标准>>> 
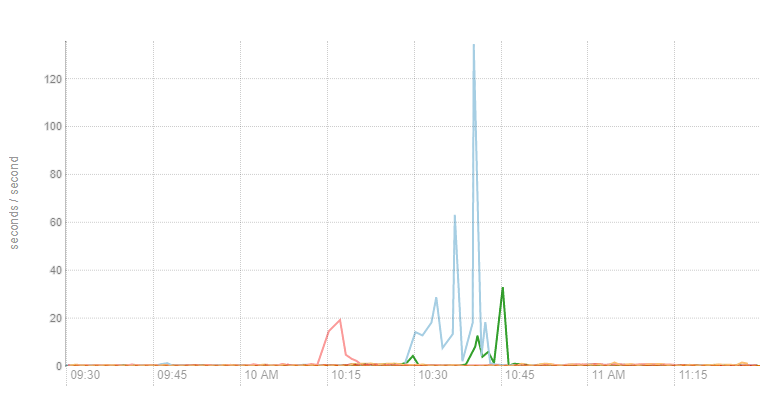
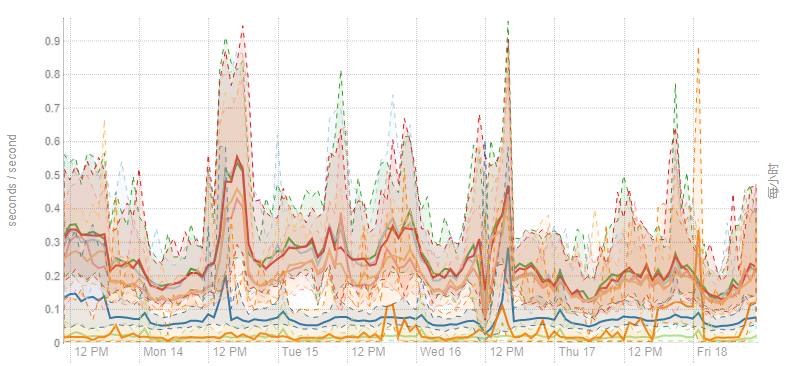
先观察了下集群系统资源的使用情况,发现网络、磁盘、内存等都没有什么迹象,唯独 CPU 负载就是居高不下,系统响应很慢,几乎不响应。几次使用 JVM 命令都无功而返。经过多次使用 Top 命令,才发现导致 CPU 负载过高(飙到200多)是 %sy 这项,表面现象是操作系统内核导致。之前无数次怀疑 Java 程序问题,GC 问题,看来方向错了,既然耗那么长时间才找到一丝线索,应该好好利用。下图是 %sy 监控情况:
尝试了一些命令后,发现和使用 JVM 命令一样,搞不定,比如用 ltrace 就导致 JVM 进程僵死。由于并非稳定重现,耗时好几天,才使用 strace -T -r -c -f -F -p 得到 futex、epoll_wait 占用资源。这不行,这些信息不足以说明或支撑如何解决负载问题,但 futex 这个是系统调用是互斥的信号,难道有锁方面问题,似乎应该从这个方面下手。
Linux 中有什么好的工具能在这种敲命令都没响应的情况下来获取一些信息呢?于是再找一些工具,gdb 尝试了下,直接卡死,搞不定。gstack、gcore 都不行,难道非得要 dump kernel core?
但即使得到了,我对 Linux 内核的分析还没多少经验,而且耗时,中间少不了服务器频繁重启,不到万不得已不走这一步。
找了一些工具:systemtap、stap、dtrace、perf 等,于是在非繁忙时候搞了一把,systemtap 的 On-CPU、Off-CPU 及火焰图不错,至少我能拿到内核系统调用到底是哪些,然后针对火焰图里耗时的系统调用信息再找具体的解决方案。systemtap 虽好,但那个 sample-bt 脚本总不如意,在负载高的时候被自己的资源限制,改了些参数也不如意。于是转向 perf,这玩意好,轻量级,就取个 60s 信息,多来几把,嘿嘿,还正搞出一些数据。
# perf record -F 99 -ag -o p1.data -- sleep 60
# perf script -i p1.data | ./stackcollapse-perf.pl > out.perf-folded
# cat out.perf-folded | ./flamegraph.pl > perf-kernel-1.svg
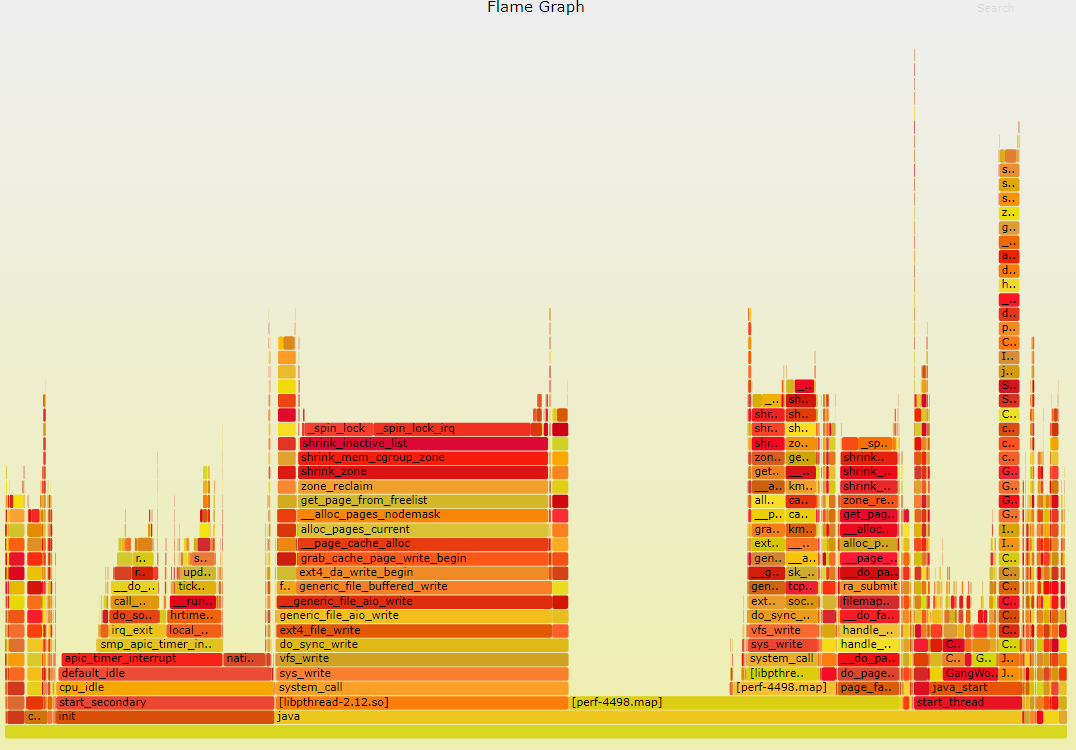
将分析的数据转换为火焰图,用火眼金睛照一照,还真能看出一些问题。
通过调用依赖关系分析,根据 _spin_lock_irq 初步推测问题由 kernel 的内存管理部分触发。
似乎 CentOS 6 相对于 CentOS 5 在 kernel 内存管理模块的一些改进点(如 transparent huge page, 基于 NUMA 的内存分配等),有没有可能是 CentOS 6 新增的 THP 特性导致 cpu sys 过高?搜索下相关函数名的关键字,确定猜测正确。通过以下内核参数优化关闭系统 THP 特性(临时生效):
# echo never > /sys/kernel/mm/redhat_transparent_hugepage/enabled
# echo never > /sys/kernel/mm/redhat_transparent_hugepage/defrag
从火焰图我们也可以看到,申请内存的线程在等待自旋锁,操作系统现在正回收 pagecache 到 freelist。于是 zone 里来申请内存的线程都得在这里等待着,于是 load 值就高了上来。外在的表现就是,系统反应好慢啊,ssh 都登不进去(因为 ssh 也会申请内存);即使登录进去了,敲命令也没有反应(因为这些命令也都是需要申请内存的)。
几个概念(来源于网络):
page cache
导致这个情况的原因是:线程在申请内存的时候,发现该 zone 的 freelist 上已经没有足够的内存可用,所以不得不去从该 zone 的 LRU 链表里回收 inactive 的 page,这种情况就是 direct reclaim(直接回收)。direct reclaim 会比较消耗时间的原因是,它在回收的时候不会区分 dirty page 和 clean page,
如果回收的是 dirty page,就会触发磁盘 IO 的操作,它会首先把 dirty page 里面的内容给刷写到磁盘,再去把该 page 给放到 freelist 里。
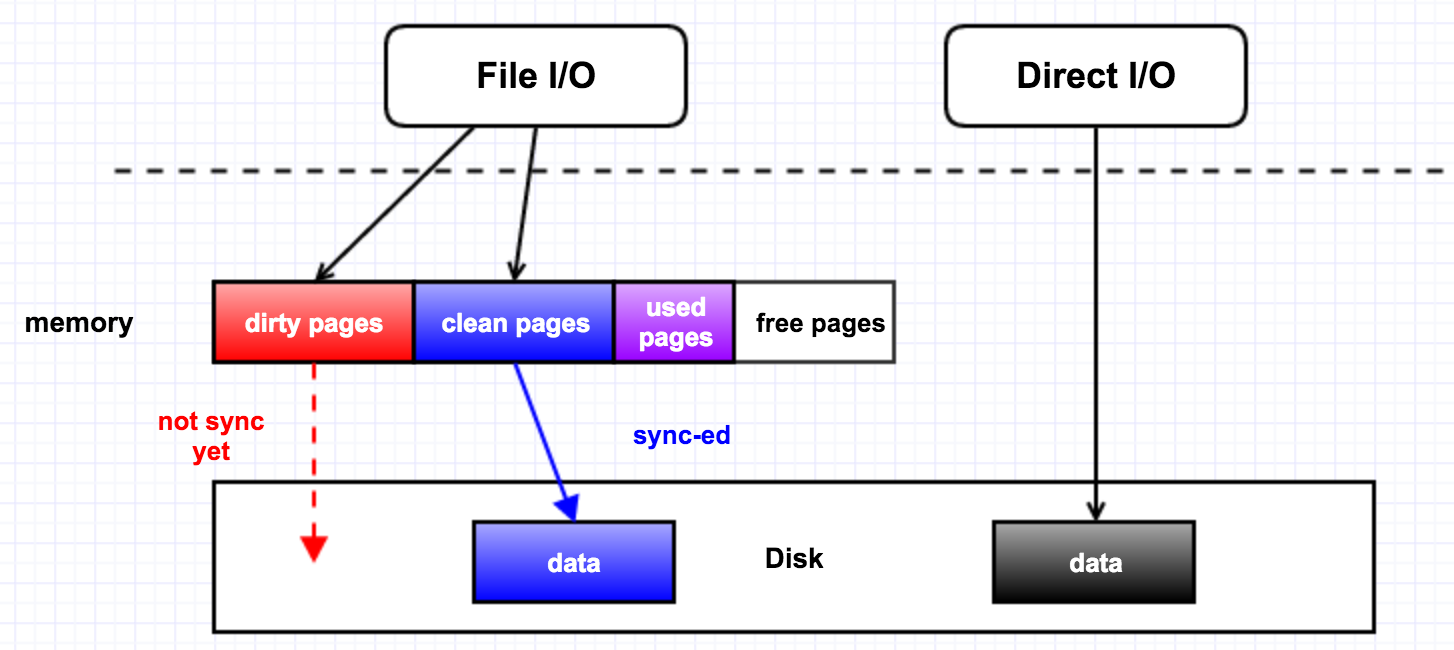
page reclaim
在直观上,我们有一个认知,当读了一个文件,它会被缓存到内存里面,如果接下来的一几天我们一直都不会再次访问它,而且这几天都不会关闭或者重启机器,那么在这几天之后该文件就不应该再在内存里头了。这就是内核对 page cache 的管理策略:LRU(最近最少使用)。即把最近最少使用的 page cache 给回收为 free pages。
内核的页回收机制有两种:后台回收和直接回收。
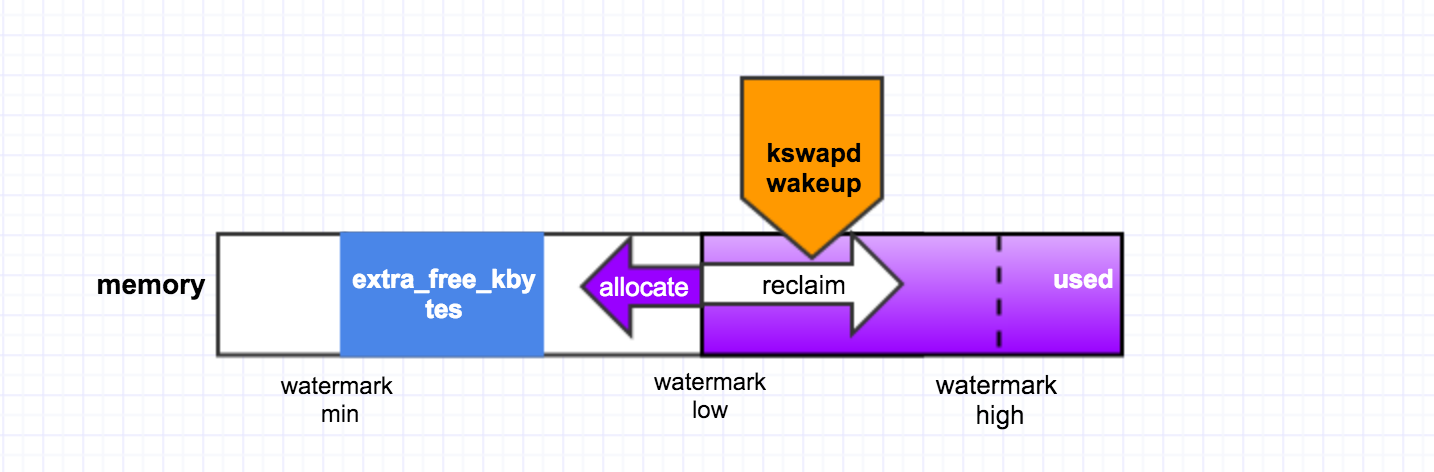
后台回收是有一个内核线程 kswapd 来做的,当内存里 free 的 pages 低于一个水位(page_low)时,就会唤醒该内核线程,然后它从 LRU 链表里回收 page cache 到内存的 free_list 里头,它会一直回收直至 free 的 pages 达到另外一个水位 page_high. 如下图所示:
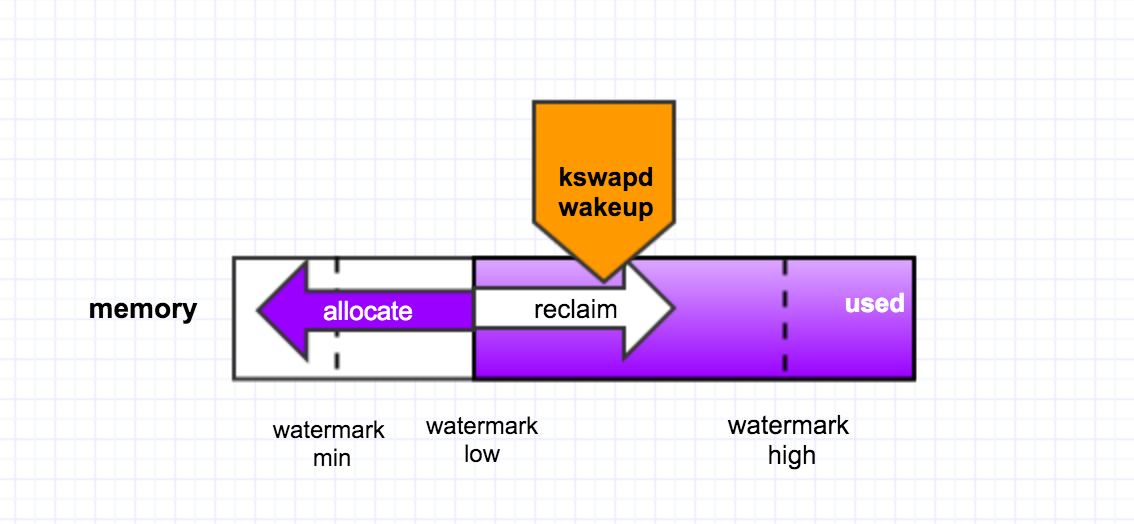
直接回收则是,在发生 page fault 时,没有足够可用的内存,于是线程就自己直接去回收内存,它一次性的会回收 32 个 pages。逻辑过程如下图所示
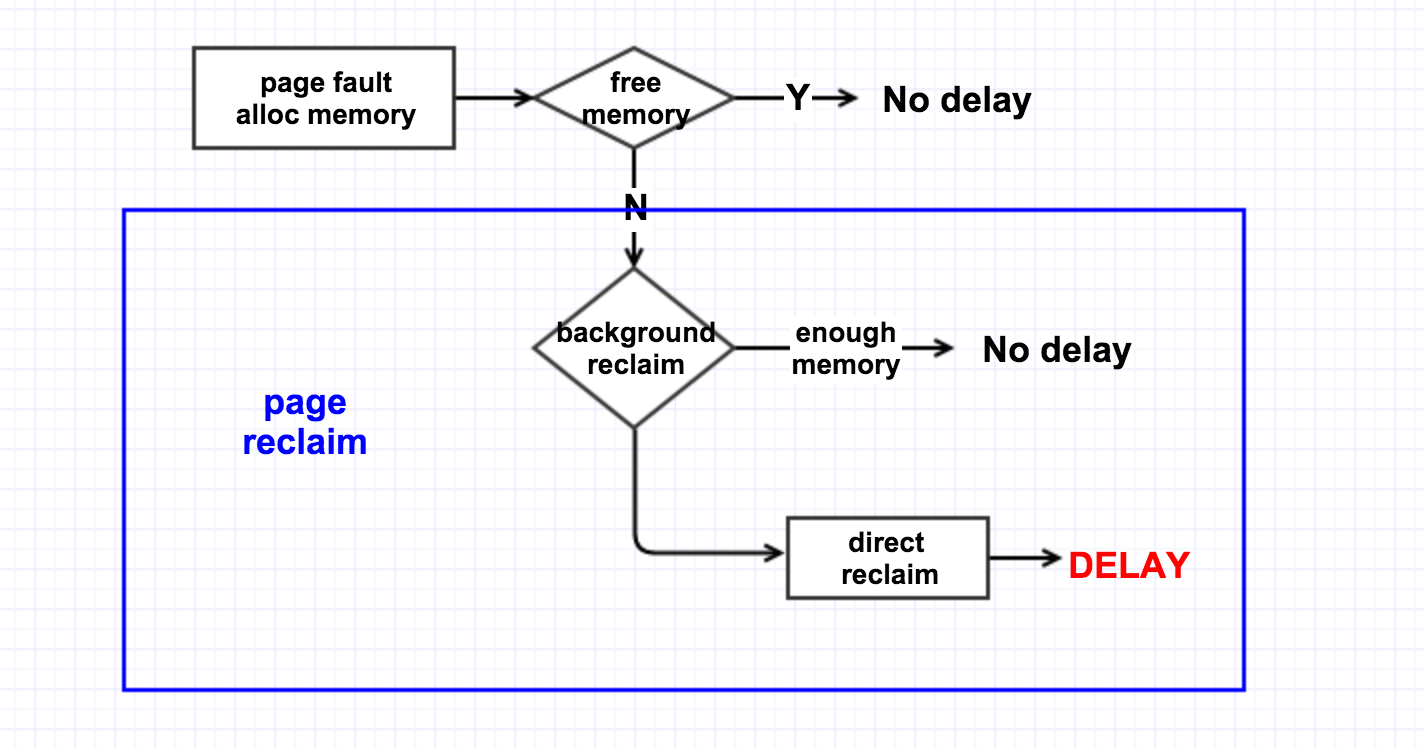
所以要避免做 direct reclaim。
memory zone
对于多核 NUMA 系统而言,内存是分节点的,不同的 CPU 对不同的内存节点的访问速度是不一样的,所以 CPU 会优先去访问靠近自己的内存节点(即速度相对快的内存区域)。
CPU 内部是依靠 MMU 来进行内存管理的,根据内存属性的不同,MMU 将一个内存节点内部又划分了不同的 zone。
对 64-bit 系统而言,一个内存节点包含三个 zone:Normal,DMA,DMA32.
对 32-bit 系统而言,一个内存节点则是包括 zone:Normal,Highmem,DMA。
Highmem 存在的目的是为了解决线性地址空间不够用的问题,在 64-bit 上由于有足够的线性地址空间所以就没了该 zone。不同 zone 存在的目的是基于数据的局部性原则,我们在写代码的时候也知道,把相关的数据给放在一起可以提高性能,memory zone 也是这个道理。于是 MMU 在分配内存时,也会尽量给同一个进程分配同一个 zone 的内存。凡事有利就有弊,这样有好处自然也可能会带来一些坏处。
为了避免 direct reclaim,我们得保证在进程申请内存时有足够可用的 free pages,从前面我们可以看出,提高 watermark low 可以尽早的唤醒 kswapd,然后 kswapd 来做 background reclaim。为此,内核专门提供了一个 sysctl 接口给用户来使用:vm.extra_free_kbytes。
# cat /etc/sysctl.conf | grep kbytes
vm.extra_free_kbytes = 4096000
vm.min_free_kbytes = 2097152
于是我们增大这个值(比如增大到 5G),确实也解决了问题。增大该值来提高 low 水位,这样在申请内存的时候,如果 free 的内存低于了该水位,就会唤醒 kswapd 去做页回收,同时又由于还有足够的 free 内存可用所以进程能够正常申请而不触发直接回收。
线程的回收跟 memory zone 相关。也就是说 normal zone 里面的 free pages 不够用了,于是触发了 direct reclaim。但是,假如此时 DMA zone 里还有足够的 free pages 呢?线程会不会从 DMA zone 里来申请内存呢?
free 的 pages 都在其它的 zone 里头,所以线程去回收自己 zone 的 page cache 而不去使用其它 zone 的 free pages。对于这个内核也提供了一个接口给用户使用:vm.zone_reclaim_mode. 这个值在该机器上本来是1(即宁肯回收自己 zone 的 page cache,也不去申请其它 zone 的 free pages),我把它更改为0(即只要其它 zone 有 free pages 就去其它 zone 里申请),就解决了该问题(一设置后系统就恢复了正常)
从这个问题也可以看出,Linux 内核提供了各种各样的机制,然后我们根据具体的使用场景来选择使用的策略。目的是为了在不影响稳定性的前提下,尽可能的提升系统性能。
Linux 机制的多种多样,也给上层的开发者带来了一些苦恼:由于对底层了解的不深入,就很难选择出一个很好的策略来使用这些内核机制。
然而对这些机制的使用,也不会有一个万能公式,还是要看具体的使用场景。由于搜索服务器存在很多批量文件操作,所以对 page cache 的使用很频繁,
所以我们才选择了尽早的能够触发 background reclaim 这个策略;而如果你的文件操作不频繁,显然就没有必要去尽早的唤醒后台回收线程。
另外一个,作为一个文件服务器,它对 page cache 的需求是很大的,越多的内存作为 page cache,系统的整体性能就会越好,所以我们就没有必要为了数据的局部性而预留 DMA 内存,
两相比较肯定是 page cache 对性能的提升大于数据的局部性对性能的提升;而如果你的文件操作不多的话,那还是打开 zone_reclaim 的。
# cat /etc/sysctl.conf | grep zone
vm.zone_reclaim_mode = 0
经过调整以上这几个参数后,再持续监控一段时间,问题得以解决。
下图是运行一段时间后的 %sy 监控情况:
在 redhat 官网和 cloudera 官网也搜到了相关的内容,附录下来,供参考。
在 redhat 的官网上,有对THP特性的细化说明:
https://access.redhat.com/site/documentation/en-US/Red_Hat_Enterprise_Linux/6/html/Performance_Tuning_Guide/s-memory-transhuge.html
在 cloudera 的 CDH4 部署说明中,也建议将系统的 THP 的 compaction 特性关闭:
http://www.cloudera.com/content/cloudera-content/cloudera-docs/CDH4/4.2.2/CDH4-Installation-Guide/cdh4ig_topic_11_6.html
转载于:https://my.oschina.net/wellben/blog/1509569
最后
以上就是殷勤人生最近收集整理的关于ES集群服务器CPU负载瞬间飚高分析的全部内容,更多相关ES集群服务器CPU负载瞬间飚高分析内容请搜索靠谱客的其他文章。








发表评论 取消回复