系列文章目录
命名实体识别NER探索(1) https://duanzhihua.blog.csdn.net/article/details/108338970 命名实体识别NER探索(2) https://duanzhihua.blog.csdn.net/article/details/108391645 命名实体识别NER探索(3)-Bi-LSTM+CRF模型 https://duanzhihua.blog.csdn.net/article/details/108392532 Viterbi算法实战案例(天气变化、词性预测) https://duanzhihua.blog.csdn.net/article/details/104992597文章目录
- 系列文章目录
- 本文内容
- 数据集
- CRF与HMM的区别
- 环境部署
本文内容
通过scikit-learn、pytorch实现不同的模型(包括HMM,CRF)来解决中文命名实体识别问题。
- 使用CRF实现中文命名实体识别功能
- 使用HMM实现中文命名实体识别功能
- 模型评估
数据集
数据集用的是论文ACL 2018Chinese NER using Lattice LSTM中从新浪财经收集的简历数据,数据的格式如下,它的每一行由一个字及其对应的标注组成,标注集采用BIOES(B表示实体开头,E表示实体结尾,I表示在实体内部,O表示非实体),句子之间用一个空行隔开。
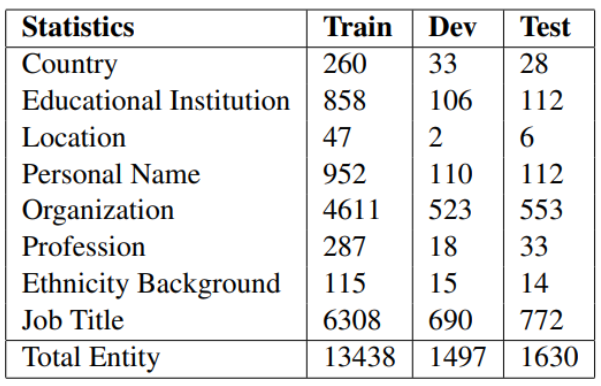
识别实体的名称和分布情况
train.char.bmes的格式
1 O
9 O
9 O
2 O
年 O
毕 O
业 O
于 O
中 B-ORG
国 M-ORG
人 M-ORG
民 M-ORG
大 M-ORG
学 M-ORG
会 M-ORG
计 M-ORG
系 E-ORG
, O
获 O
学 B-EDU
士 M-EDU
学 M-EDU
位 E-EDU
; O
1 O
9 O
9 O
0 O
年 O
至 O
1 O
9 O
9 O
5 O
年 O
于 O
外 B-ORG
交 M-ORG
部 E-ORG
财 B-TITLE
务 M-TITLE
司 M-TITLE
一 M-TITLE
处 E-TITLE
工 O
作 O
; O
test.char.bmes格式如下
男 O
, O
大 B-EDU
学 M-EDU
学 M-EDU
历 E-EDU
, O
中 B-TITLE
国 M-TITLE
注 M-TITLE
册 M-TITLE
会 M-TITLE
计 M-TITLE
师 E-TITLE
、 O
会 B-TITLE
计 M-TITLE
师 E-TITLE
。 O
......
https://github.com/zyxdSTU/NER-CRF-HMM/blob/master/data/
...
CRF与HMM的区别
HMM是生成模型,CRF是判别模型
HMM是概率有向图,CRF是概率无向图
HMM求解过程可能是局部最优,CRF可以全局最优
CRF概率归一化较合理,HMM则会导致label bias 问题 (https://blog.csdn.net/lskyne/article/details/8669301)
HMM模型做了两个很重要的假设如下:
1) 齐次马尔科夫链假设。即任意时刻的隐藏状态只依赖于它前一个隐藏状态。当然这样假设有点极端,因为很多时候我们的某一个隐藏状态不仅仅只依赖于前一个隐藏状态,可能是前两个或者是前三个。但是这样假设的好处就是模型简单,便于求解。
2) 观测独立性假设。即任意时刻的观察状态只仅仅依赖于当前时刻的隐藏状态,这也是一个为了简化模型的假设。
和HMM不同的是,CRF并没有做出上述的假设,CRF使用feature function来更抽象地表达特征,使得他不再局限于HMM的两类特征。一个特征函数可以表示为 f(X,i,y[i], y[i-1]) 其中 X 表示 input sequence, n 为当前的位置, y[n] 是当前state,y[n-1] 表示前一个state。但是只有在linear CRF中 y[n-1] 表示前一个state,事实上它可以有更丰富的表达。例如特征函数可以表示当前的state与任意一个observation或者 state甚至future state的关系。也就是说,特征方程的存在允许CRF有十分自由的特征表达, y[i-1] 可以是y[i±1,…n] 。这也就是条件随机场中场所代表的意义为了简化,我们使用 y[i-1]来表示CRF的概率分布函数
环境部署
安装crfsuite & pytorch
- 使用scikit-learn实现CRF模型。
- 使用python实现的HMM的库很少,使用pytorch实现HMM模型。
- 在python中导入pycrfsuite、sklearn-crfsuite、torch包
(1)pip install python-crfsuite
(2)pip install sklearn-crfsuite
(3)conda install pytorch torchvision cpuonly -c pytorch
pytorch官网
pip使用清华镜像源: pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple matplotlib
代码如下:
import os
import sys
import random
import numpy as np
import pandas as pd
from collections import Counter
from sklearn.metrics import precision_score, recall_score, f1_score, accuracy_score, classification_report
from sklearn_crfsuite import CRF # CRF的具体实现太过复杂,这里我们借助一个外部的库
import torch
get_ipython().run_line_magic('matplotlib', 'inline')
random.seed(123)
### 数据准备
# In[2]:
train_path= "../data/task1/train.char.bmes"
test_path = "../data/task1/test.char.bmes"
# ### 读取数据
# In[3]:
def read_data(path):
sents_list = []
tags_list = []
with open(path, 'r', encoding="utf-8") as f:
data = f.read()
examples = data.split("nn")
for e in examples:
lines = e.split("n")
sents = []
tags = []
for line in lines:
line = line.strip()
if line == "":
continue
char, tag = line.split(" ")
sents.append(char)
tags.append(tag)
if len(sents) == 0:
continue
sents_list.append(sents)
tags_list.append(tags)
return (sents_list, tags_list)
# In[4]:
train_data = read_data(train_path)
test_data = read_data(test_path)
# ### 打印数据的信息
# In[5]:
choice = random.randint(0,len(train_data[0]))
sent = train_data[0][choice]
tags = train_data[1][choice]
for c, t in zip(sent, tags):
print(c + " " + t)
# ### 数据训练集与测试集的分布情况
# In[6]:
train_size = len(train_data[0])
print("训练集的大小: ",train_size)
# In[7]:
test_size = len(test_data[0])
print("测试集的大小: ",test_size)
# ### 数据集的长度分布情况
# In[8]:
lengths = []
for sent in train_data[0]:
lengths.append(len(sent))
df = pd.DataFrame(np.array(lengths))
df.describe()
# ### 标签的分布情况
#
# In[9]:
tag_count = Counter()
for tags in train_data[1]:
#for tag in tags:
tag_count.update(tags)
tag_count
# ### 条件随机场实现NER识别
# In[10]:
def word2features(sent, i):
"""抽取单个字的特征"""
word = sent[i]
prev_word = "<s>" if i == 0 else sent[i-1]
next_word = "</s>" if i == (len(sent)-1) else sent[i+1]
# 因为每个词相邻的词会影响这个词的标记
# 所以我们使用:
# 前一个词,当前词,后一个词,
# 前一个词+当前词, 当前词+后一个词
# 作为特征
features = {
'w': word,
'w-1': prev_word,
'w+1': next_word,
'w-1:w': prev_word+word,
'w:w+1': word+next_word,
'bias': 1
}
return features
# In[11]:
def sent2features(sent):
"""抽取序列特征"""
return [word2features(sent, i) for i in range(len(sent))]
# In[12]:
class CRFModel(object):
def __init__(self,
algorithm='lbfgs',
c1=0.1,
c2=0.1,
max_iterations=100,
all_possible_transitions=False
):
self.model = CRF(algorithm=algorithm,
c1=c1,
c2=c2,
max_iterations=max_iterations,
all_possible_transitions=all_possible_transitions)
#https://sklearn-crfsuite.readthedocs.io/en/latest/api.html#module-sklearn_crfsuite
def train(self, sentences, tag_lists):
"""训练模型"""
features = [sent2features(s) for s in sentences]
self.model.fit(features, tag_lists)
def test(self, sentences):
"""解码,对给定句子预测其标注"""
features = [sent2features(s) for s in sentences]
pred_tag_lists = self.model.predict(features)
return pred_tag_lists
# In[13]:
crf = CRFModel()
# In[14]:
crf.train(train_data[0], train_data[1])
# In[15]:
pred_tag_lists = crf.test(test_data[0])
# In[16]:
test_data[0][0]
# In[17]:
pred_tag_lists[0]
# In[18]:
ref_tags_full = []
pred_tags_full = []
for ref_tags, pred_tags in zip(test_data[1], pred_tag_lists):
ref_tags_full.extend(ref_tags)
pred_tags_full.extend(pred_tags)
assert len(ref_tags_full) == len(pred_tags_full)
# In[19]:
res = classification_report(ref_tags_full, pred_tags_full, digits=4)
print(res)
#F1=2PR/(P+R)
#https://www.cnblogs.com/178mz/p/8558435.html
#https://en.wikipedia.org/wiki/Precision_and_recall#F-measure
# In[ ]:
# ### 隐马尔科夫模型实现NER实体识别
# In[20]:
class HMM(object):
def __init__(self, N, M):
"""Args:
N: 状态数,这里对应存在的标注的种类
M: 观测数,这里对应有多少不同的字
"""
self.N = N
self.M = M
# 状态转移概率矩阵 A[i][j]表示从i状态转移到j状态的概率
self.A = torch.zeros(N, N)
# 观测概率矩阵, B[i][j]表示i状态下生成j观测的概率
self.B = torch.zeros(N, M)
# 初始状态概率 Pi[i]表示初始时刻为状态i的概率
self.Pi = torch.zeros(N)
def train(self, word_lists, tag_lists, word2id, tag2id):
"""HMM的训练,即根据训练语料对模型参数进行估计,
因为我们有观测序列以及其对应的状态序列,所以我们
可以使用极大似然估计的方法来估计隐马尔可夫模型的参数
参数:
word_lists: 列表,其中每个元素由字组成的列表,如 ['担','任','科','员']
tag_lists: 列表,其中每个元素是由对应的标注组成的列表,如 ['O','O','B-TITLE', 'E-TITLE']
word2id: 将字映射为ID
tag2id: 字典,将标注映射为ID
"""
assert len(tag_lists) == len(word_lists)
# 估计转移概率矩阵
for tag_list in tag_lists:
seq_len = len(tag_list)
for i in range(seq_len - 1):
current_tagid = tag2id[tag_list[i]]
next_tagid = tag2id[tag_list[i+1]]
self.A[current_tagid][next_tagid] += 1
# 问题:如果某元素没有出现过,该位置为0,这在后续的计算中是不允许的
# 解决方法:我们将等于0的概率加上很小的数
self.A[self.A == 0.] = 1e-10
self.A = self.A / self.A.sum(dim=1, keepdim=True)
# 估计观测概率矩阵
for tag_list, word_list in zip(tag_lists, word_lists):
assert len(tag_list) == len(word_list)
for tag, word in zip(tag_list, word_list):
tag_id = tag2id[tag]
word_id = word2id[word]
self.B[tag_id][word_id] += 1
self.B[self.B == 0.] = 1e-10
self.B = self.B / self.B.sum(dim=1, keepdim=True)
# 估计初始状态概率
for tag_list in tag_lists:
init_tagid = tag2id[tag_list[0]]
self.Pi[init_tagid] += 1
self.Pi[self.Pi == 0.] = 1e-10
self.Pi = self.Pi / self.Pi.sum()
def test(self, word_lists, word2id, tag2id):
pred_tag_lists = []
for word_list in word_lists:
pred_tag_list = self.decoding(word_list, word2id, tag2id)
pred_tag_lists.append(pred_tag_list)
return pred_tag_lists
def decoding(self, word_list, word2id, tag2id):
"""
使用维特比算法对给定观测序列求状态序列, 这里就是对字组成的序列,求其对应的标注。
维特比算法实际是用动态规划解隐马尔可夫模型预测问题,即用动态规划求概率最大路径(最优路径)
这时一条路径对应着一个状态序列
"""
# 问题:整条链很长的情况下,十分多的小概率相乘,最后可能造成下溢
# 解决办法:采用对数概率,这样源空间中的很小概率,就被映射到对数空间的大的负数
# 同时相乘操作也变成简单的相加操作
A = torch.log(self.A)
B = torch.log(self.B)
Pi = torch.log(self.Pi)
# 初始化 维比特矩阵viterbi 它的维度为[状态数, 序列长度]
# 其中viterbi[i, j]表示标注序列的第j个标注为i的所有单个序列(i_1, i_2, ..i_j)出现的概率最大值
seq_len = len(word_list)
viterbi = torch.zeros(self.N, seq_len)
# backpointer是跟viterbi一样大小的矩阵
# backpointer[i, j]存储的是 标注序列的第j个标注为i时,第j-1个标注的id
# 等解码的时候,我们用backpointer进行回溯,以求出最优路径
backpointer = torch.zeros(self.N, seq_len).long()
# self.Pi[i] 表示第一个字的标记为i的概率
# Bt[word_id]表示字为word_id的时候,对应各个标记的概率
# self.A.t()[tag_id]表示各个状态转移到tag_id对应的概率
# 所以第一步为
start_wordid = word2id.get(word_list[0], None)
Bt = B.t()
if start_wordid is None:
# 如果字不再字典里,则假设状态的概率分布是均匀的
bt = torch.log(torch.ones(self.N) / self.N)
else:
bt = Bt[start_wordid]
viterbi[:, 0] = Pi + bt
backpointer[:, 0] = -1
# 递推公式:
# viterbi[tag_id, step] = max(viterbi[:, step-1]* self.A.t()[tag_id] * Bt[word])
# 其中word是step时刻对应的字
# 由上述递推公式求后续各步
for step in range(1, seq_len):
wordid = word2id.get(word_list[step], None)
# 处理字不在字典中的情况
# bt是在t时刻字为wordid时,状态的概率分布
if wordid is None:
# 如果字不再字典里,则假设状态的概率分布是均匀的
bt = torch.log(torch.ones(self.N) / self.N)
else:
bt = Bt[wordid] # 否则从观测概率矩阵中取bt
for tag_id in range(len(tag2id)):
max_prob, max_id = torch.max(
viterbi[:, step-1] + A[:, tag_id],
dim=0
)
viterbi[tag_id, step] = max_prob + bt[tag_id]
backpointer[tag_id, step] = max_id
# 终止, t=seq_len 即 viterbi[:, seq_len]中的最大概率,就是最优路径的概率
best_path_prob, best_path_pointer = torch.max(
viterbi[:, seq_len-1], dim=0
)
# 回溯,求最优路径
best_path_pointer = best_path_pointer.item()
best_path = [best_path_pointer]
for back_step in range(seq_len-1, 0, -1):
best_path_pointer = backpointer[best_path_pointer, back_step]
best_path_pointer = best_path_pointer.item()
best_path.append(best_path_pointer)
# 将tag_id组成的序列转化为tag
assert len(best_path) == len(word_list)
id2tag = dict((id_, tag) for tag, id_ in tag2id.items())
tag_list = [id2tag[id_] for id_ in reversed(best_path)]
return tag_list
# In[21]:
tag2id = {}
word2id = {}
#===练习1.1===
#根据训练数据train_data 构建tag->id,word->id的映射,映射关系为递增计数,示例如下:
# word2id = {"高":0,"勇":1,":":2 , ...}
# tag2id ={'B-NAME': 0, 'E-NAME': 1,...}
# In[22]:
list(word2id.keys())[0:10]
# In[23]:
list(word2id.values())[0:10]
# In[24]:
tag2id
# In[25]:
hmm = HMM(len(tag2id), len(word2id))
# In[26]:
hmm.train(train_data[0], train_data[1], word2id, tag2id)
# In[ ]:
pred_tag_lists = hmm.test(test_data[0], word2id, tag2id)
# In[ ]:
test_data[0][0]
# In[ ]:
pred_tag_lists[0]
# In[ ]:
ref_tags_full = []
pred_tags_full = []
for ref_tags, pred_tags in zip(test_data[1], pred_tag_lists):
ref_tags_full.extend(ref_tags)
pred_tags_full.extend(pred_tags)
assert len(ref_tags_full) == len(pred_tags_full)
# In[ ]:
res = classification_report(ref_tags_full, pred_tags_full, digits=4)
print(res)
最后
以上就是帅气美女最近收集整理的关于命名实体识别NER探索(4) 通过scikit-learn、pytorch实现HMM 及CRF模型系列文章目录本文内容数据集CRF与HMM的区别环境部署的全部内容,更多相关命名实体识别NER探索(4)内容请搜索靠谱客的其他文章。








发表评论 取消回复