该文章来自吴恩达深度学习课程一 week3的作业
任务:
1.利用含一个隐藏层的神经网络 实现一个二分类器
2.使用非线性激活函数,如tanh relu
3.计算交叉熵误差
4.实现前向与后向传播
#导入所需要的模块
# Package imports
import numpy as np
import matplotlib.pyplot as plt
from testCases import *
import sklearn
import sklearn.datasets
import sklearn.linear_model
from planar_utils import plot_decision_boundary, sigmoid, load_planar_dataset, load_extra_datasets
%matplotlib inline
np.random.seed(1) # set a seed so that the results are consistent
#导入数据,并将其可视化
X, Y = load_planar_dataset() # Visualize the data:
plt.scatter(X[0, :], X[1, :], c=Y.reshape(X[0,:].shape), s=40, cmap=plt.cm.Spectral);
求出其输入特征个数与样本数
### START CODE HERE ### (≈ 3 lines of code)
shape_X = X.shape
shape_Y = Y.shape
m = shape_X[1] # training set size
### END CODE HERE ###
print ('The shape of X is: ' + str(shape_X))
print ('The shape of Y is: ' + str(shape_Y))
print ('I have m = %d training examples!' % (m))The shape of X is: (2, 200)
The shape of Y is: (1, 200)
I have m = 200 training examples!
在仅仅使用逻辑回归的情况下对图像进行分类
# Plot the decision boundary for logistic regression
plot_decision_boundary(lambda x: clf.predict(x), X, Y.reshape(X[0,:].shape))#The part of red was Y
plt.title("Logistic Regression")
# Print accuracy
LR_predictions = clf.predict(X.T)
print ('Accuracy of logistic regression: %d ' % float((np.dot(Y,LR_predictions) + np.dot(1-Y,1-LR_predictions))/float(Y.size)*100) +
'% ' + "(percentage of correctly labelled datapoints)")Y.reshape(X[0,:].shape))#The part of red was Y
plt.title("Logistic Regression")
# Print accuracy
LR_predictions = clf.predict(X.T)
print ('Accuracy of logistic regression: %d ' % float((np.dot(Y,LR_predictions) + np.dot(1-Y,1-LR_predictions))/float(Y.size)*100) +
'% ' + "(percentage of correctly labelled datapoints)")注意加红的部分原本为Y,会导致维度不匹配。需要修改成Y.reshape(X[0,:].shape) 或者np.squeeze(Y)都可。
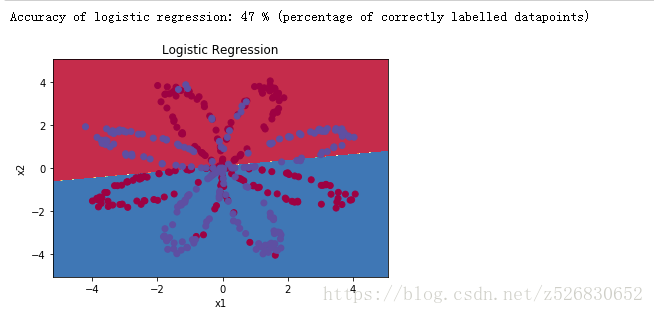
可以看出仅使用逻辑回归的分类情况很糟糕,因为数据并不是线性分布的。我们希望能使用神经网络改善预测的表现
#搭建神经网络
神经网络架构如下图所示
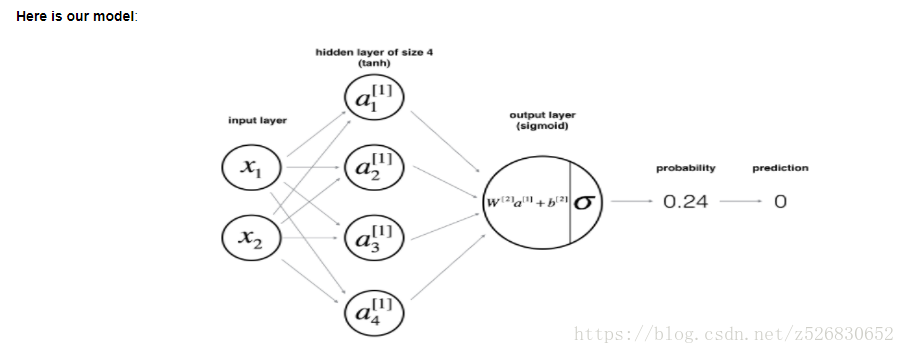
前向传播与cost function 的定义
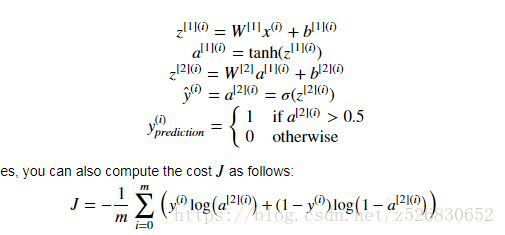
#构建一个神经网络的基本思路
1.定义好自己的神经网络结构
2.初始化自己的各项参数
3. loop 循环
1.前向传播计算出预测值
2.利用预测值计算出loss
3.利用预测值进行后向传播计算出各个参数的梯度
4.根据更新规则不断更新自己的参数
#开始搭建!
首先我们找出:
n_x 输入层的单元数
n_h 隐藏层的单元数
n_y 输出层的单元数
def layer_sizes(X, Y):
"""
Arguments:
X -- input dataset of shape (input size, number of examples)
Y -- labels of shape (output size, number of examples)
Returns:
n_x -- the size of the input layer
n_h -- the size of the hidden layer
n_y -- the size of the output layer
"""
### START CODE HERE ### (≈ 3 lines of code)
n_x = X.shape[0] # size of input layer
n_h = 4
n_y = Y.shape[0] # size of output layer
### END CODE HERE ###
return (n_x, n_h, n_y)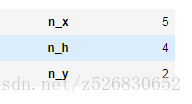
2.对参数进行初始化
使用np.random.randn(a,b)* X 对W进行初始化
使用np.zeros((a,b)) 对b进行初始化
输入的n_x , n_h ,n_y 决定了矩阵W和向量B的维度
def initialize_parameters(n_x, n_h, n_y):
"""
Argument:
n_x -- size of the input layer
n_h -- size of the hidden layer
n_y -- size of the output layer
Returns:
params -- python dictionary containing your parameters:
W1 -- weight matrix of shape (n_h, n_x)
b1 -- bias vector of shape (n_h, 1)
W2 -- weight matrix of shape (n_y, n_h)
b2 -- bias vector of shape (n_y, 1)
"""
np.random.seed(2) # we set up a seed so that your output matches ours although the initialization is random.
### START CODE HERE ### (≈ 4 lines of code)
W1 = np.random.randn(n_h,n_x)*0.01
b1 = np.zeros((n_h,1))
W2 = np.random.randn(n_y,n_h)*0.01
b2 = np.zeros((n_y,1))
### END CODE HERE ###
assert (W1.shape == (n_h, n_x))
assert (b1.shape == (n_h, 1))
assert (W2.shape == (n_y, n_h))
assert (b2.shape == (n_y, 1))
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2}
return parameters得到的矩阵保存在parameters里面
3.前向传播函数
对隐藏层使用 tanh激活,最后一层输出层使用sigmoid分类
def forward_propagation(X, parameters):
"""
Argument:
X -- input data of size (n_x, m)
parameters -- python dictionary containing your parameters (output of initialization function)
Returns:
A2 -- The sigmoid output of the second activation
cache -- a dictionary containing "Z1", "A1", "Z2" and "A2"
"""
# Retrieve each parameter from the dictionary "parameters"
### START CODE HERE ### (≈ 4 lines of code)
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
### END CODE HERE ###
# Implement Forward Propagation to calculate A2 (probabilities)
### START CODE HERE ### (≈ 4 lines of code)
Z1 = np.dot(W1,X)+b1
A1 = np.tanh(Z1) #隐藏层使用tanh激活
Z2 = np.dot(W2,A1)+b2
A2 = 1/(1+np.exp(-Z2)) #输出层用sigmoid函数判断
### END CODE HERE ###
assert(A2.shape == (1, X.shape[1]))
cache = {"Z1": Z1,
"A1": A1,
"Z2": Z2,
"A2": A2}
return A2, cachecache中保存了Z1,A1,Z2,A2 用于后向传播的梯度计算
4.计算loss

作业中给出的向量化提示
def compute_cost(A2, Y, parameters):
"""
Computes the cross-entropy cost given in equation (13)
Arguments:
A2 -- The sigmoid output of the second activation, of shape (1, number of examples)
Y -- "true" labels vector of shape (1, number of examples)
parameters -- python dictionary containing your parameters W1, b1, W2 and b2
Returns:
cost -- cross-entropy cost given equation (13)
"""
m = Y.shape[1] # number of example
# Compute the cross-entropy cost
### START CODE HERE ### (≈ 2 lines of code)
logprobs = np.multiply(np.log(A2),Y)+np.multiply(np.log(1-A2),1-Y)
cost = - np.sum(logprobs)/m
### END CODE HERE ###
cost = np.squeeze(cost) # makes sure cost is the dimension we expect.
# E.g., turns [[17]] into 17
assert(isinstance(cost, float))
return cost
5.后向传播
后向传播的部分比较复杂,在我们这个架构中的定义如下


注意计算dZ1的方法,其中g` Z = 1-a^2.上式的*号代表element-wise的乘法
def backward_propagation(parameters, cache, X, Y):
"""
Implement the backward propagation using the instructions above.
Arguments:
parameters -- python dictionary containing our parameters
cache -- a dictionary containing "Z1", "A1", "Z2" and "A2".
X -- input data of shape (2, number of examples)
Y -- "true" labels vector of shape (1, number of examples)
Returns:
grads -- python dictionary containing your gradients with respect to different parameters
"""
m = X.shape[1]
# First, retrieve W1 and W2 from the dictionary "parameters".
### START CODE HERE ### (≈ 2 lines of code)
W1 = parameters["W1"]
W2 = parameters["W2"]
### END CODE HERE ###
# Retrieve also A1 and A2 from dictionary "cache".
### START CODE HERE ### (≈ 2 lines of code)
A1 = cache["A1"]
A2 = cache["A2"]
### END CODE HERE ###
# Backward propagation: calculate dW1, db1, dW2, db2.
### START CODE HERE ### (≈ 6 lines of code, corresponding to 6 equations on slide above)
dZ2 = A2-Y
dW2 = np.dot(dZ2,A1.T)/m
db2 = np.sum(dZ2,axis = 1,keepdims = True)/m
dZ1 = np.dot(W2.T,dZ2)*(1-np.power(A1,2))
dW1 = np.dot(dZ1,X.T)/m
db1 = np.sum(dZ1,axis=1,keepdims = True )/m
### END CODE HERE ###
grads = {"dW1": dW1,
"db1": db1,
"dW2": dW2,
"db2": db2}
return grads
6.更新参数
θ=θ-α*dθ
def update_parameters(parameters, grads, learning_rate = 1.2):
"""
Updates parameters using the gradient descent update rule given above
Arguments:
parameters -- python dictionary containing your parameters
grads -- python dictionary containing your gradients
Returns:
parameters -- python dictionary containing your updated parameters
"""
# Retrieve each parameter from the dictionary "parameters"
### START CODE HERE ### (≈ 4 lines of code)
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
### END CODE HERE ###
# Retrieve each gradient from the dictionary "grads"
### START CODE HERE ### (≈ 4 lines of code)
dW1 = grads["dW1"]
db1 = grads["db1"]
dW2 = grads["dW2"]
db2 = grads["db2"]
## END CODE HERE ###
# Update rule for each parameter
### START CODE HERE ### (≈ 4 lines of code)
W1 = W1-learning_rate*dW1
b1 = b1-learning_rate*db1
W2 = W2-learning_rate*dW2
b2 = b2-learning_rate*db2
### END CODE HERE ###
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2}
return parameters
6.对上述函数进行整个组合成一个模型
def nn_model(X, Y, n_h, num_iterations = 10000, print_cost=False):
"""
Arguments:
X -- dataset of shape (2, number of examples)
Y -- labels of shape (1, number of examples)
n_h -- size of the hidden layer
num_iterations -- Number of iterations in gradient descent loop
print_cost -- if True, print the cost every 1000 iterations
Returns:
parameters -- parameters learnt by the model. They can then be used to predict.
"""
np.random.seed(3)
n_x = layer_sizes(X, Y)[0]
n_y = layer_sizes(X, Y)[2]
# Initialize parameters, then retrieve W1, b1, W2, b2. Inputs: "n_x, n_h, n_y". Outputs = "W1, b1, W2, b2, parameters".
### START CODE HERE ### (≈ 5 lines of code)
parameters = initialize_parameters(n_x,n_h,n_y)
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
### END CODE HERE ###
# Loop (gradient descent)
for i in range(0, num_iterations):
### START CODE HERE ### (≈ 4 lines of code)
# Forward propagation. Inputs: "X, parameters". Outputs: "A2, cache".
A2, cache = forward_propagation(X, parameters)
# Cost function. Inputs: "A2, Y, parameters". Outputs: "cost".
cost = compute_cost(A2, Y, parameters)
# Backpropagation. Inputs: "parameters, cache, X, Y". Outputs: "grads".
grads = backward_propagation(parameters, cache, X, Y)
# Gradient descent parameter update. Inputs: "parameters, grads". Outputs: "parameters".
parameters = update_parameters(parameters, grads)
### END CODE HERE ###
# Print the cost every 1000 iterations
if print_cost and i % 1000 == 0:
print ("Cost after iteration %i: %f" %(i, cost))
return parametersparameters中就含有这个网络所有的训练参数
7.进行预测
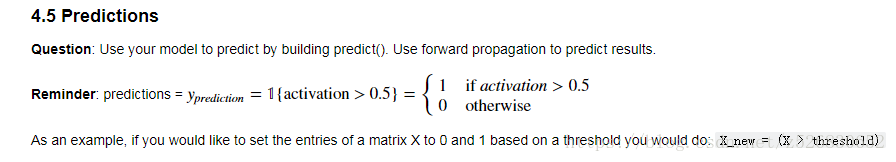
X_new = (X>threshold) 即可构建出一个根据预测阈值的标签向量
对新输入的X进行一次前向传播即是进行预测
def predict(parameters, X):
"""
Using the learned parameters, predicts a class for each example in X
Arguments:
parameters -- python dictionary containing your parameters
X -- input data of size (n_x, m)
Returns
predictions -- vector of predictions of our model (red: 0 / blue: 1)
"""
# Computes probabilities using forward propagation, and classifies to 0/1 using 0.5 as the threshold.
### START CODE HERE ### (≈ 2 lines of code)
A2, cache = forward_propagation(X, parameters)
predictions = (A2>0.5)
### END CODE HERE ###
return predictions
#选择不同的隐藏层的单元数会发生什么?
最后
以上就是爱撒娇大神最近收集整理的关于【Deep learning AI】用一个隐藏层构建平面数据分类器的全部内容,更多相关【Deep内容请搜索靠谱客的其他文章。








发表评论 取消回复