一.什么是Ftech
“Fetch API提供了一个JavaScript接口,用于访问和操纵HTTP管道的部分,例如请求和响应。它还提供了一个全局 fetch()方法,该方法提供了一种简单,合理的方式来跨网络异步获取资源。”
简单来说,在前一阶段,我们通常是使用ajax之类的基于XMLHttpRequest来进行发送各种http网络请求,但是由于XHR其自身的局限性,导致在其基础上封装的原生ajax,或是jquery ajax在碰到回调地狱时都会有心无力。为了解决这一问题,也是为了更好拥抱ES6,W3C发布了fetch这一更底层的API(此处有争议,官方认为fetch更底层,更开放,但部分人却认为fetch和HTML5的拖拽API一样浮于表面)。
请注意,fetch规范与jQuery.ajax()主要有两种方式的不同,牢记:
- 当接收到一个代表错误的 HTTP 状态码时,从 fetch()返回的 Promise 不会被标记为 reject, 即使该 HTTP 响应的状态码是 404 或 500。相反,它会将 Promise 状态标记为 resolve (但是会将resolve的返回值的ok属性设置为false),仅当网络故障时或请求被阻止时,才会标记为 reject。
- 默认情况下,fetch 不会从服务端发送或接收任何 cookies, 如果站点依赖于用户 session,则会导致未经认证的请求(要发送 cookies,必须设置 credentials 选项)。
二.开启Fetch漫游之旅
事先说明一下,本文中服务器由node express提供,如果想运行的话大家可以先把node引擎和npm装起来,该install的依赖install就行了。代码先贴出来把:
const express = require('express');
const bodyParser = require('body-parser');
const static = require('express-static');
const consolidate = require('consolidate');
const path = require('path');
const multer = require('multer');
const fs = require('fs');
var app = express();
//配置模板引擎
app.set("view engine", "html");
app.set("views", path.join(__dirname, "views"));
app.engine("html", consolidate.ejs);
//转发静态资源
app.use("/static", static(path.join(__dirname, "public")));
//解析 request payload数据
app.use(bodyParser.json());
//解析post数据 from-data数据
app.use(
bodyParser.urlencoded({
extended: false
})
);
//解析post文件
var objMulter = multer({dest:'./public/upload'})
app.use(objMulter.any());
app.get('/', (req, res) => {
res.render('fetch.ejs');
})
app.get('/get', (req, res) => {
res.send('get success');
})
app.post('/post', (req, res) => {
//console.log(req)
res.send(req.body);
})
app.post('/ajax/post', (req, res) => {
res.send(req.body);
})
app.use('/file', (req, res) => {
var file = req.files[0];
var old_name = file.path;
var ext_name = path.parse(file.originalname).ext;
var new_name = old_name + ext_name;
fs.rename(old_name, new_name, (err) => {
if(err){
res.status(500).send("error");
}else{
res.status(200).send("success");
}
})
})
var server = app.listen('7008', (req, res) => {
console.log('run success in port:' + server.address().port)
})
我们先来看一个最简单的fetch get实例:
fetch('/get', {
method: 'get'
}).then(res => res.text())
.then(res => {
console.log(res); // get success
})
get实例很简单对吧?我们可以再来看看POST实例,从这开始,就会有趣了:
var data = { 'name': 'waw', 'password': 19 }
fetch('/post', {
method: 'post',
headers: new Headers({
'Content-Type': 'application/json'
}),
body: JSON.stringify(data)
}).then(res => res.text())
.then(res => {
console.log(res); // {}
})
可以看到,打印出来是个空的。诶,我发过去的json数据呢??
我们看下图:
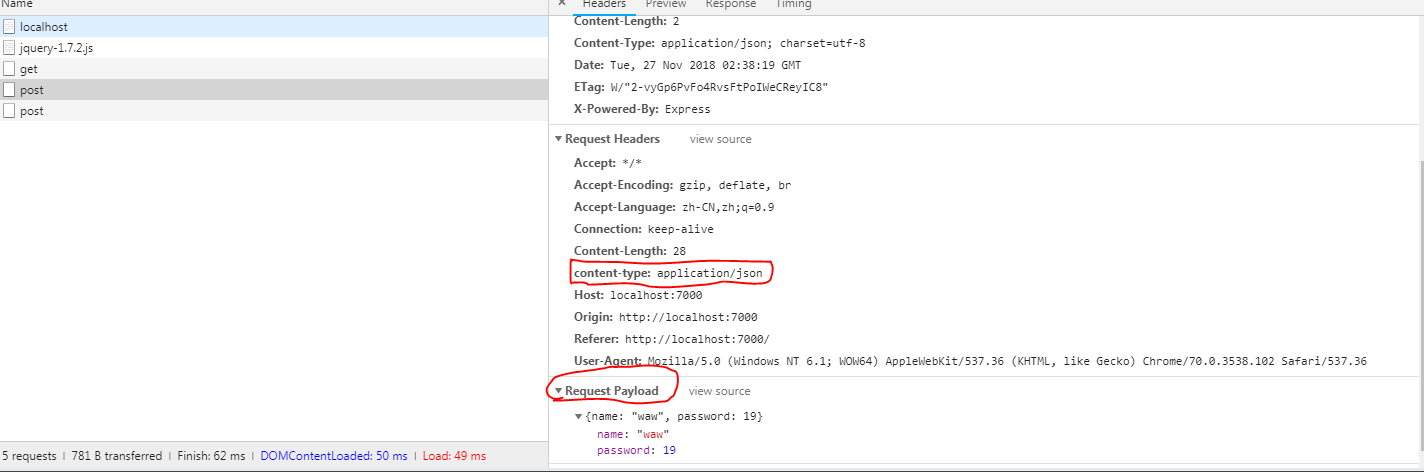
光看这个图,json参数是发过去了,但是后台拿不到啊,所以导致后台返回的也是个空对象。光看这个例子,可能大家还没什么感觉,我再来一个常规的:
var post_data = { 'name': 'waw2', 'password': 16 };
$.ajax({
url: '/ajax/post',
type: 'post',
dataType: 'json',
data: {
'data': JSON.stringify(post_data)
},
success: json => {
console.log(json.staus); //{ 'name': 'waw2', 'password': 16 }
}
})
(PS:以上代码中使用的是jquery ajax,想跑的情自行引用文件,伸手党请自重)
可以看到,这时我们拿到了后台返回的,也就是我们发过去的json参数,这是为什么?我们再看一张截图:
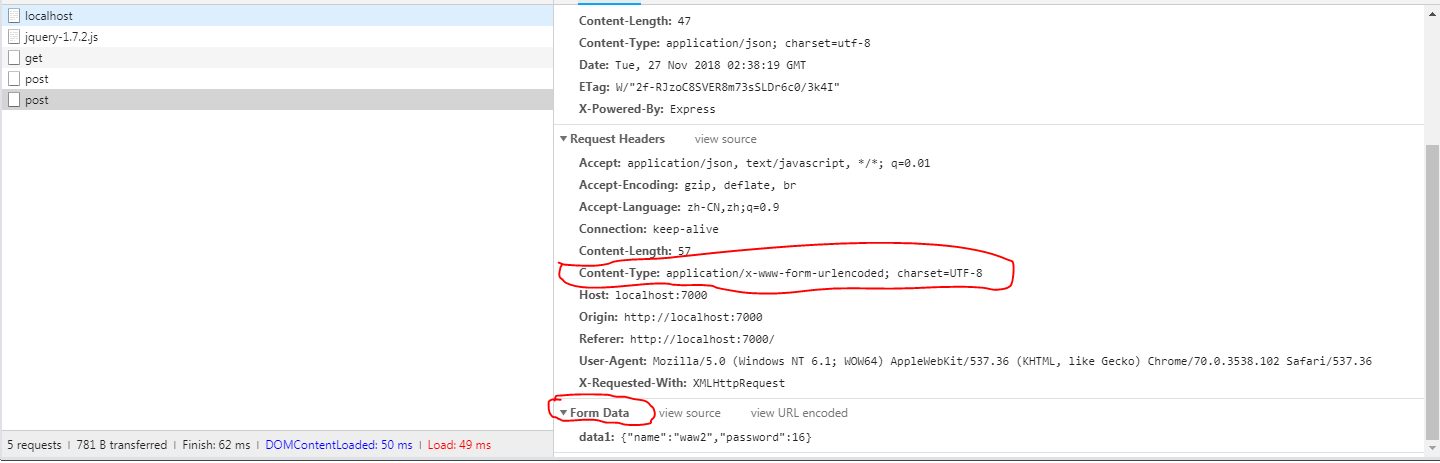
和上面的图做对比,我们能很明显的看出两个请求的请求头的不同:
content-type的不同。- 发送参数出现在的项不同(一个是
Form Data,一个是Request Payload)
很显然,问题就出在这。后台对Request Payload格式的post数据去解析的方式是不同的,解决方案也很简单,就是加上app.use(bodyParser.json());这一句代码就行,在本文中我为了方便,事先屏蔽了。
那么Form Data和Request Payload是什么?它们由什么来决定?大家可以看看我的这篇文章:关于HTTP中formData和Request Payload的区别。好,我们言归正传,接着来看fetch的实例。接下来我们看看文件提交:
HTML Dom部分:
<!DOCTYPE html>
<html lang="zh-cn">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Fetch</title>
</head>
<body>
<input type="file" id="File">
<button id="subBtn">提交表单数据</button>
</body>
</html>
JS部分:
$("#subBtn").on('click', function () {
var fomData = new FormData();
var file = document.getElementById('File');
fomData.append('file', file.files[0]);
fetch("/file", {
method: 'put',
body: fomData,
}).then(res => res.json())
.then(res => {
console.log('file', res)
})
})
后台对应的文件上传部分,在上面贴出来的代码中有,我就不赘述了。
fetch里的文件上传相对于传统的文件上传有一个特点,首先可以看到并不需要<form></form>标签来包裹,自然也不需要设置enctype。更简洁,也更符合“尽量让js控制js事件操作”的原则。
三.Fetch的特性
1.Headers接口
一般来说,我们使用 Headers() 构造函数来创建一个 headers 对象。也就是说,我们可以提前创建好一个 headers 对象,然后往里面塞入我们想要添加的属性规则,由于它是一个变量,所以方便我们自由的借助此特性封装基于fetch的ajax库。
我偷个懒,就不自己敲了,给大家放上MDN上的demo,很详细。
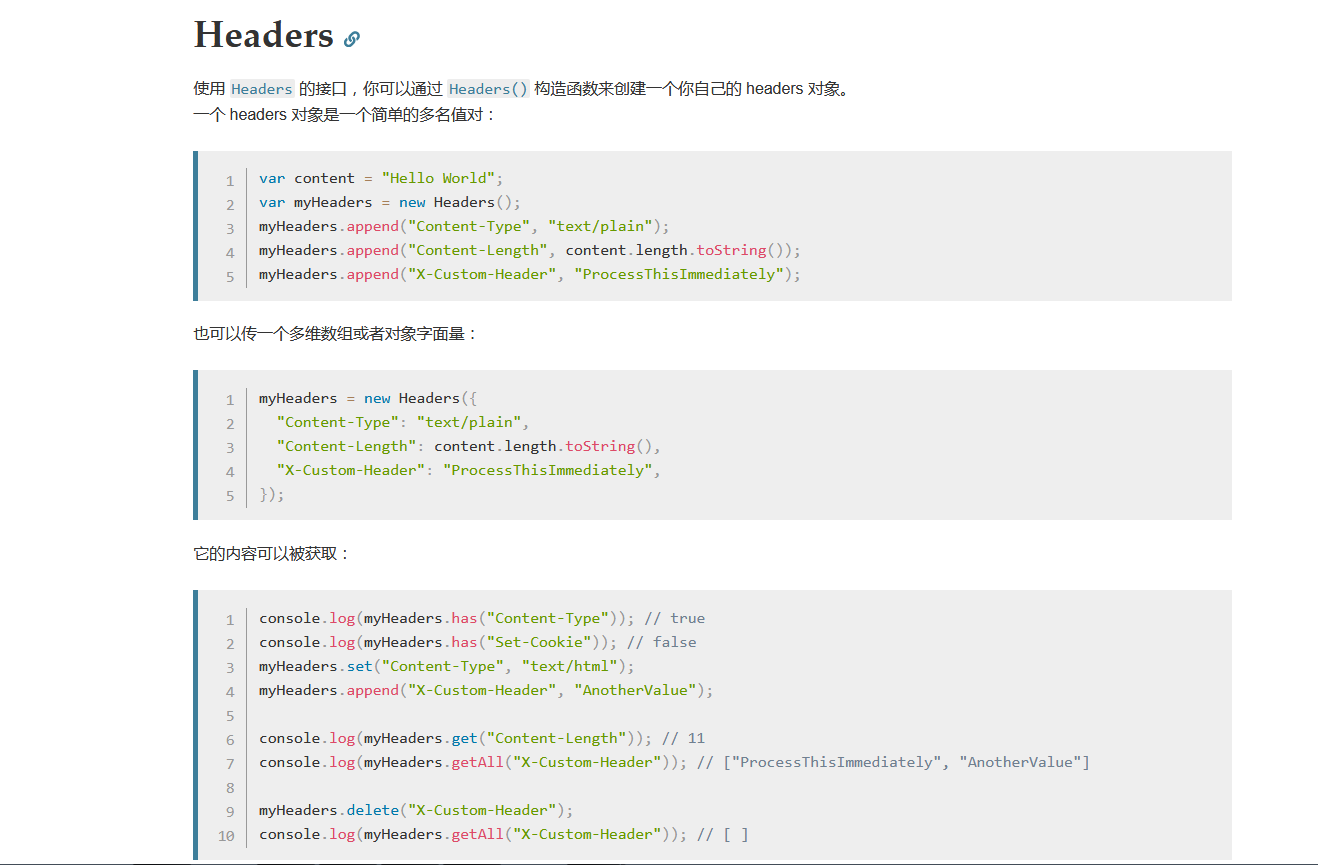
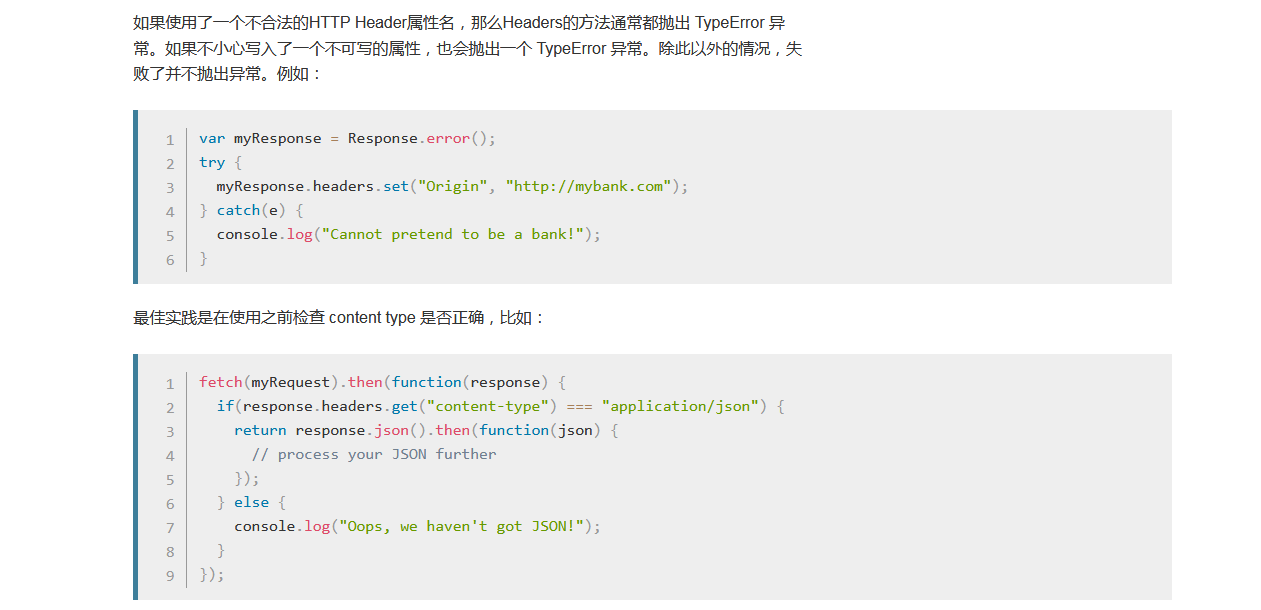
2.Body对象
fetch-body对象中提供了5个方法供转化数据格式使用,分别是:
- arrayBuffer()
- blob()
- json()
- text()
- formData()
下面我来简单介绍一下这几个方法的作用:
1.arrayBuffer()
arrayBuffer() 接受一个 Response 流, 并等待其读取完成. 它返回一个 promise 实例, 并 resolve 一个 ArrayBuffer 对象.
以上是MDN给出的解释,简单来说呢,arrayBuffer()方法是用来处理后台发过来的二进制文件流的,语法如下:
response.arrayBuffer().then(function(buffer) {
// do something with buffer
)};
关于arrayBuffer()方法,就不得不提ArrayBuffer对象:
ArrayBuffer 对象用来表示通用的、固定长度的原始二进制数据缓冲区。ArrayBuffer 不能直接操作,而是要通过类型数组对象或DataView对象来操作,它们会将缓冲区中的数据表示为特定的格式,并通过这些格式来读写缓冲区的内容。
简单来说,ES6提供了一个新的数据类型ArrayBuffer,让我们可以操作二进制流的数据;这个接口主要的目的是为WebGL服务,通过ArrayBuffer来开启浏览器与显卡之间的通信,并加快计算的速度。
ArrayBuffer对象并不能直接来操作,而是需要类型数组对象或DataView对象这两个东西。类型数组对象是什么呢?
1.1 类型数组对象
一个 TypedArray 对象描述一个底层的二进制数据缓存区的一个类似数组(array-like)视图。事实上,没有名为TypedArray的全局对象,也没有一个名为的 TypedArray构造函数。
MDN上的解释有些晦涩,我们称类型数组对象为TypedArray对象,但是事实上又没有这个对象,出现这个情况的原因就是它并不是一个实际的接口或者函数,而是一个类或一类方法的泛指,实际上来说,TypedArray对象是指以下这些方法中的一个:
Int8Array();Uint8Array();Uint8ClampedArray();Int16Array();Uint16Array();Int32Array();Uint32Array();Float32Array();Float64Array();
用法的话,就类似下面这个例子:
const typedArray1 = new Int8Array(8);
typedArray1[0] = 32;
console.log(typedArray1) //Int8Array [32, 0, 0, 0, 0, 0, 0, 0]
1.2 DataView对象
DataView 视图是一个可以从 ArrayBuffer 对象中读写多种数值类型的底层接口,在读写时不用考虑平台字节序问题¹。
注1:平台字节序问题是由于不同平台的字节顺序不同产生的;这是计算机领域由来已久的问题之一,在各种计算机体系结构中,由于对于字,字节等存储机制有所不同,通信双方交流的信息单元(比特、字节、字、双字等)应该以什么样的顺序进行传送就成了一个问题,所以需要一个统一的规则。
使用语法如下:
new DataView(buffer [, byteOffset [, byteLength]])
参数说明:
- buffer:一个 ArrayBuffer 或 SharedArrayBuffer 对象,DataView 对象的数据源。
- byteOffset(可选):此DataView对象的第一个字节在buffer中的偏移。如果不指定则默认从第一个字节开始。
- byteLength(可选):此 DataView 对象的字节长度。如果不指定则默认与 buffer 的长度相同。
返回值:
一个由 buffer 生成的 DataView 对象。
异常:
RangeError:如果由偏移(byteOffset)和字节长度(byteLength)计算得到的结束位置超出了 buffer 的长度,抛出此异常。
示例如下:
var buffer = new ArrayBuffer(16);
// Create a couple of views
var view1 = new DataView(buffer);
var view2 = new DataView(buffer,12,4); //from byte 12 for the next 4 bytes
view1.setInt8(12, 42); // put 42 in slot 12
console.log(view2.getInt8(0)); //42
console.log(view1.getInt8(12)); //42
2.blog()
通常来说,如果你需要去请求一个图片来加载,你可以使用blog()函数来获取url,并赋值到你Dom层的img标签中。
Dom:
<body>
<img src="" alt="">
</body>
js:
var myImage = document.querySelector('img');
var myRequest = new Request('/static/image/test.jpg');
fetch(myRequest)
.then(function (response) {
return response.blob();
})
.then(function (myBlob) {
var objectURL = URL.createObjectURL(myBlob); //myBlob typeof object
myImage.src = objectURL;
myImage.onload = function () {
window.URL.revokeObjectURL(objectUrl);
};
});
我简单解释一下,blog()函数将后台发过来的文件流读取到,然后通过URL.createObjectURL()函数从这个blob对象中获取到对应的url,最后讲此url赋值给img的src,再img加载完成后,通过URL.revokeObjectURL()来回收之前那个url,以解除浏览器对它的引用。要注意的是,通常来说,不管你加载多少张图片,浏览器的机制是只会同时保持对一张图片的引用,这意味着任何一张图片的加载都会经历以下这5个过程:
- createObjectURL.
- 加载img.
- revokeObjectURL以释放引用 .
- 失去了img ref.
- 为下一个删除的图像重复所有步骤.
所以,最后那步的对象回收是很有必要的,它能保证浏览器的内存回收机制正常运行。
这里藏着一个特有意思的事儿,那就是通过fetch-blob()获取到的图片,和直接通过服务器资源路径获取到的图片有什么区别吗?
为了解决这个困惑,我加了一个普通demo,以和上面的请求方式区别开来:
这是普通img的加载模式:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Audio</title>
</head>
<body>
<img src="/static/image/test.jpg" alt="">
</body>
</html>
这是fetch-blob()下img的加载模式:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>fetch-blob()</title>
</head>
<body>
<img src="" alt="">
</body>
</html>
<script>
var myImage = document.querySelector('img');
var myRequest = new Request('/static/image/test.jpg');
fetch(myRequest)
.then(function (response) {
return response.blob();
})
.then(function (myBlob) {
var objectURL = URL.createObjectURL(myBlob);
myImage.src = objectURL;
myImage.onload = function () {
window.URL.revokeObjectURL(objectUrl);
};
});
</script>
以下是这两种模式下的请求图片的区别:
普通模式:
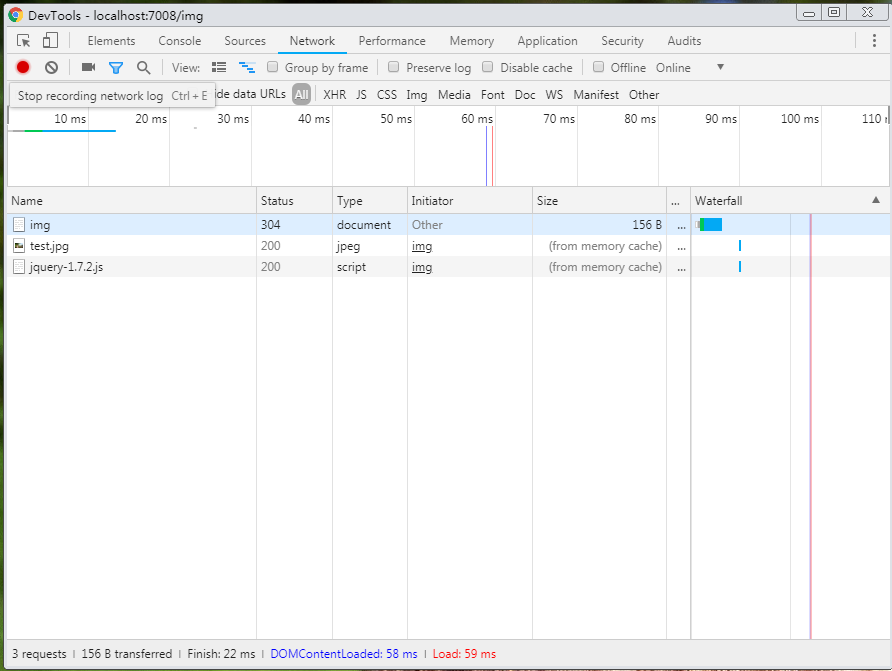
fetch-blob模式:
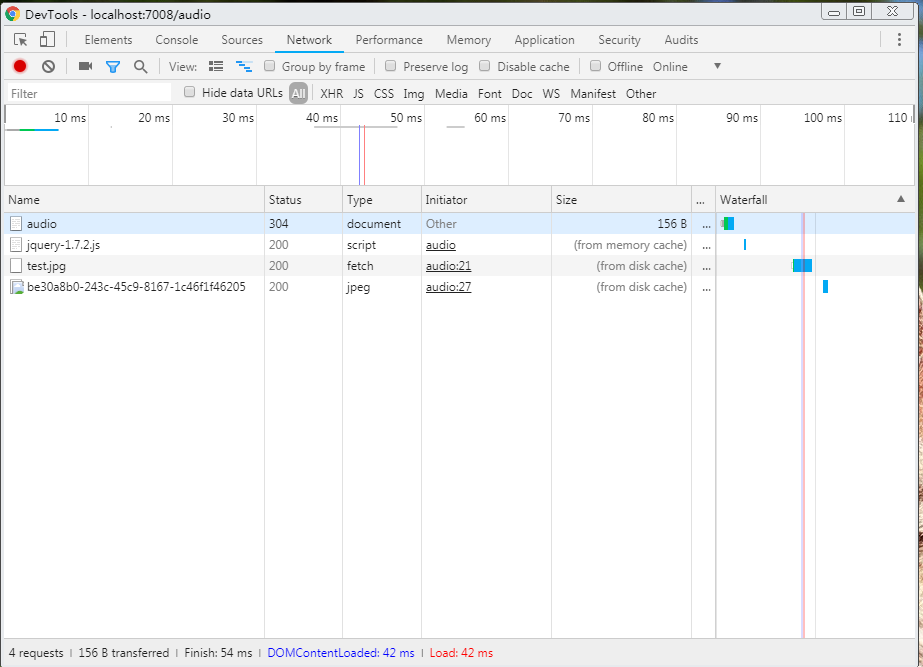
从图中我们可以看到,blob模式相比普通模式,多请求了一个本地文件,此文件的请求路径,其实也就是我们通过URL.createObjectURL()生成的url,如下图:

**还有一点区别需要注意:**普通模式下的img加载,如果你在不设置强强缓存机制的情况下多刷新几次,你就会发现这个图片的请求变成了304(from memory cache),也就是不再从服务端加载了。但是如果是fetch-blob模式的加载,将会一直200,也就是从始至终它都会从服务端加载。
两种模式的好坏我不做评价,毕竟能解决实际的业务场景的问题的技术就是好技术。
讲完了blob()函数,我又不得不讲讲blob对象了(无奈脸)。毕竟blob对象才是支撑fetch body.blob()函数的基建。
我们先来看看什么是blob对象:
Blob 对象表示一个不可变、原始数据的类文件对象。Blob表示的不一定是JavaScript原生格式的数据。File接口基于Blob,继承了blob的功能并将其扩展使其支持用户系统上的文件。
我们看一个示例:
var aFileParts = ['<a id="a"><b id="b">hey!</b></a>']; // 一个包含DOMString的数组
var oMyBlob = new Blob(aFileParts, {type : 'text/html'}); // 得到 blob
var reader = new FileReader();
reader.addEventListener("loadend", function(res) {
console.log(res)
});
reader.readAsArrayBuffer(oMyBlob);
注意:如果你在vscode下运行这段代码,时候报错的:ReferenceError: Blob is not defined,所以你只能把它运行在浏览器环境下。
blog格式的数据对象,一般通过FileReader来读取。
3.formData()
Body 对象中的formData()方法将Response对象中的所承载的数据流读取并封装成为一个对象,该方法将返回一个 Promise 对象,该对象将产生一个FormData 对象。
一般来说,我们使用formData()来格式化文件流数据。
我们看一个示例:
Dom层:
<body>
<input type="file" id="File">
<button id="subBtn">上传</button>
</body>
js层:
$("#subBtn").on('click', function () {
var fomData = new FormData();
var file = document.getElementById('File');
fomData.append('file', file.files[0]);
fetch("/file", {
method: 'put',
body: fomData,
}).then(res => res.json())
.then(res => {
console.log('file', res)
})
})
可以看到,和一般的上传模式不同,主要有两点:
- 不需要
<form></form>标签包裹。 - 不需要额外指定
content-type。
后台处理文件上传的代码在最开始已经贴出来了,有兴趣的同学可以去看看。
其他两个个json(), text()方法我在这就不给大家介绍了,因为比较简单,理解起来也没什么难度,大家可以自行去MDN上查看,在文章的结尾我会挂上MDN的参考链接。
在《Fetch漫游指南——篇1》这篇文章中我讲了大量延伸内容,为了文章的可读性,我觉得这篇文章讲到这里来作为篇一的收尾已经足够了,在 《Fetch漫游指南——篇2》中,我将会介绍以下内容:
- Fetch Response对象
- 自定义request对象
- Fetch的异常捕捉以及封装
- Fetch的兼容方案以及实操(可不是简单的把hack方案挂出来哦,博主会详细的把操作过程中碰到的问题一一讲解)
四.参考文章/文献
1.【MDN】 使用 Fetch
2.【MDN】 JavaScript 标准库
3.【MDN】 Web API 接口
最后
以上就是冷艳舞蹈最近收集整理的关于Fetch漫游指南--篇1的全部内容,更多相关Fetch漫游指南--篇1内容请搜索靠谱客的其他文章。








发表评论 取消回复