实践内容:
编写MapReduce程序分析气象数据集(ftp://ftp.ncdc.noaa.gov/pub/data/noaa
上2018年中国地区监测站的数据),分析出2018年每个月出现最高温度的监测站的温度、湿度、纬度、经度、大气压力等信息。要求:
1、输出格式
201801 320,330,52130,122520,10264
201802 350,360,12330,543270,10463
2、温度、湿度、纬度、经度、大气压力等信息用一个自定义类来封装。
3、shuffle阶段使用合并(Combine)操作。
4、将结果分别输出到2-4个文件(Partitioner分区)。
气象数据格式说明:
1-4 0169
5-10 501360 # USAF weather station identifier
11-15 99999 # WBAN weather station identifier
16-23 20170101 # 记录日期
24-27 0000 # 记录时间
28 4
29-34 +52130 # 纬度(1000倍)
35-41 +122520 # 经度(1000倍)
42-46 FM-12
47-51 +0433 # 海拔(米)
52-56 99999
57-60 V020
61-63 220 # 风向
64 1 # 质量代码
65 N
66-69 0010
70 1
71-75 02600 # 云高(米)
76 1
77 9
78 9
79-84 003700 # 能见距离(米)
85 1
86 9
87 9
88-92 -0327 # 空气温度(摄氏度10)
93 1
94-98 -0363 # 露点温度(摄氏度10)
99 1
100-104 10264 # 大气压力
105 1
思路:
从一大串文本中提取出需要的数据(温度,湿度,经纬度等)可以使用字符串的子字符串来做到,这一部分交给map来做。将map处理后,可以得到一系列的<时间,Bean>这样的键值对,例如<“20190101”,MyBean1>。这写数据将交由reduce进行处理,reduce对这些来自map的数据再处理,在处理之前,首先定义partioner将这些数据按月份划分为两个区(1月 ~ 6月,7月 ~ 12月,划分的区的大小要根据实际的reducer来设定)。之后,reduce会对这这些被划分好的数据(也就是每一个月份的数据),找出这里面这个月的温度最大值,将它写出去。
项目结构:
实际操作:
MyDriver.java
这里需要注意的地方是
要设置task任务数,这里的任务数和待会分区的个数是一致的
package com.jxufe.xzy.hadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapred.TestMiniMRClientCluster;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class MyDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://Master:9000");
conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem");
Job job = Job.getInstance(conf); job.setJarByClass(MyDriver.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setCombinerClass(MyReducer.class);
job.setPartitionerClass(MyPartioner.class);
job.setNumReduceTasks(2);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(MyBean.class); FileInputFormat.setInputPaths(job, new Path("/input/cndcdata.txt"));
FileOutputFormat.setOutputPath(job, new Path("/output"));
System.exit(job.waitForCompletion(true)?0:1);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
Mapper类:MyMapper.java
package com.jxufe.xzy.hadoop;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;
import java.text.DateFormat;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
public class MyMapper extends Mapper<LongWritable, Text,Text,MyBean> {
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 提取信息
String strValue = value.toString();
String dateStr = strValue.substring(15,23);
Text text = new Text();
//初始化mybean
String temprature = strValue.substring(87,92).substring(2,5);
String humidity = strValue.substring(93,98).substring(2,5);
String latitude = strValue.substring(28,34).substring(1,6);
String longtitude = strValue.substring(34,41).s
MyBean mb = new MyBean(temprature,humidity,latitude,longtitude,presture);
text.set(dateStr);
context.write(text,mb);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
自定义实体类:MyBean.java
这里值得注意的一点是,序列化与反序列化的顺序要一致,一一对应
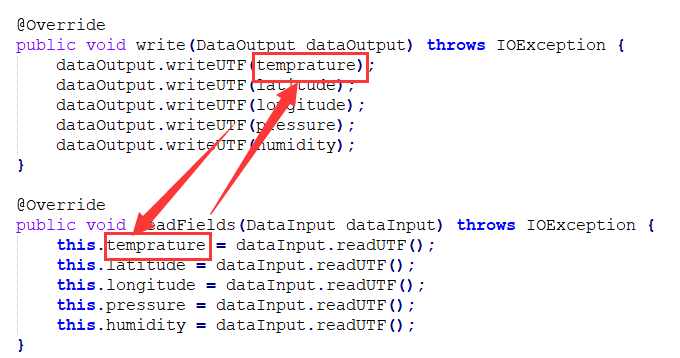
package com.jxufe.xzy.hadoop;import org.apache.hadoop.io.Writable;import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;public class MyBean implements Writable{
private String temprature;
private String humidity;
private String latitude;
private String longitude;
private String pressure; public MyBean(){ } public MyBean( String temprature, String humidity, String latitude, String longitude, String pressure) {
this.temprature = temprature;
this.humidity = humidity;
this.latitude = latitude;
this.longitude = longitude;
this.pressure = pressure;
} public String getTemprature() {
return temprature;
} public void setTemprature(String temprature) {
this.temprature = temprature;
} public String getHumidity() {
return humidity;
} public void setHumidity(String humidity) {
this.humidity = humidity;
} public String getLatitude() {
return latitude;
} public void setLatitude(String latitude) {
this.latitude = latitude;
} public String getLongitude() {
return longitude;
} public void setLongitude(String longitude) {
this.longitude = longitude;
} public String getPressure() {
return pressure;
} public void setPressure(String pressure) {
this.pressure = pressure;
}
@Override
public String toString() {
return temprature + "," + humidity +
"," + latitude + "," + longitude + "," + pressure;
} @Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(temprature);
dataOutput.writeUTF(latitude);
dataOutput.writeUTF(longitude);
dataOutput.writeUTF(pressure);
dataOutput.writeUTF(humidity);
} @Override
public void readFields(DataInput dataInput) throws IOException {
this.temprature = dataInput.readUTF();
this.latitude = dataInput.readUTF();
this.longitude = dataInput.readUTF();
this.pressure = dataInput.readUTF();
this.humidity = dataInput.readUTF();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
自定义分区:MyPartioner.java
package com.jxufe.xzy.hadoop;import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;import java.text.DateFormat;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;public class MyPartioner extends Partitioner<Text, MyBean> {
@Override
public int getPartition(Text key, MyBean value, int reducerNum) {
Date date = parseDate(key.toString());
//设置两个分区(1,6)月为一个分区,(7,12)月为一个分区
if(date.getMonth() < 6){
return 0;
}else {
return 1;
}
} public static Date parseDate(String dateStr) { DateFormat f1 = new SimpleDateFormat("yyyyMMdd");
Date date = null;
try {
date = f1.parse(dateStr);
} catch (ParseException e) {
e.printStackTrace();
}
return date;
}// @Override
// public int getPartition(Object o, Object o2, int i) {
// return 0;
// }
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
Reduce类:MyReduce.java
package com.jxufe.xzy.hadoop;import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class MyReducer extends Reducer<Text,MyBean,Text,MyBean> {
public void reduce(Text key, Iterable<MyBean> values, Context context) throws IOException, InterruptedException {
// 找最大值
int max = 0;
String dateStr = key.toString().substring(0,6);
Text keyOut = new Text();
keyOut.set(dateStr);
MyBean mb = new MyBean();
for (MyBean value : values){
if (Integer.parseInt(value.getTemprature()) > max){
max = Integer.parseInt(value.getTemprature());
mb = value;
}
}
context.write(keyOut,mb);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
运行效果:
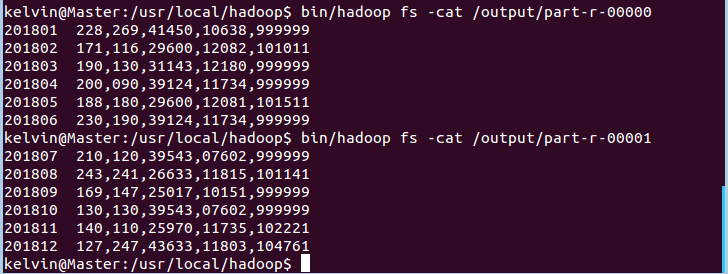
最后
以上就是重要早晨最近收集整理的关于MapReduce实践之气象温度的全部内容,更多相关MapReduce实践之气象温度内容请搜索靠谱客的其他文章。








发表评论 取消回复