这次是搬来的JD的哦~~新开源的计算机视觉模块,京东AI研究院提出的一种新的注意力结构。将CoT Block代替了ResNet结构中的3x3卷积,在分类检测分割等任务效果都出类拔萃
论文地址:https://arxiv.org/pdf/2107.12292.pdf
源代码地址:https://github.com/JDAI-CV/CoTNet
具有自注意力的Transformer引发了自然语言处理领域的革命,最近还激发了Transformer式架构设计的出现,并在众多计算机视觉任务中取得了具有竞争力的结果。
如下是之前我们分享的基于Transformer的目标检测新技术!
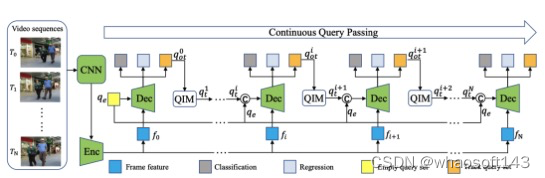
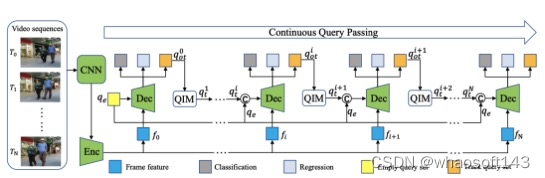
尽管如此,大多数现有设计直接在2D特征图上使用自注意力来获得基于每个空间位置的独立查询和键对的注意力矩阵,但未充分利用相邻键之间的丰富上下文。在今天分享的工作中,研究者设计了一个新颖的Transformer风格的模块,即Contextual Transformer (CoT)块,用于视觉识别。这种设计充分利用输入键之间的上下文信息来指导动态注意力矩阵的学习,从而增强视觉表示能力。从技术上讲,CoT块首先通过3×3卷积对输入键进行上下文编码,从而产生输入的静态上下文表示。
上图是传统的self-attention仅利用孤立的查询-键对来测量注意力矩阵,但未充分利用键之间的丰富上下文。
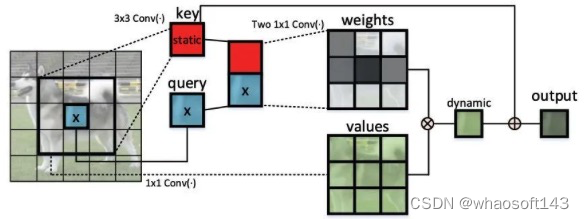
上图(b)就是CoT块
研究者进一步将编码的键与输入查询连接起来,通过两个连续的1×1卷积来学习动态多头注意力矩阵。学习到的注意力矩阵乘以输入值以实现输入的动态上下文表示。静态和动态上下文表示的融合最终作为输出。CoT块很吸引人,因为它可以轻松替换ResNet架构中的每个3 × 3卷积,产生一个名为Contextual Transformer Networks (CoTNet)的Transformer式主干。通过对广泛应用(例如图像识别、对象检测和实例分割)的大量实验,验证了CoTNet作为更强大的主干的优越性。
Attention注意力机制与self-attention自注意力机制
-
为什么要注意力机制?
在Attention诞生之前,已经有CNN和RNN及其变体模型了,那为什么还要引入attention机制?主要有两个方面的原因,如下:
(1)计算能力的限制:当要记住很多“信息“,模型就要变得更复杂,然而目前计算能力依然是限制神经网络发展的瓶颈。
(2)优化算法的限制:LSTM只能在一定程度上缓解RNN中的长距离依赖问题,且信息“记忆”能力并不高。
-
什么是注意力机制
在介绍什么是注意力机制之前,先让大家看一张图片。当大家看到下面图片,会首先看到什么内容?当过载信息映入眼帘时,我们的大脑会把注意力放在主要的信息上,这就是大脑的注意力机制。

同样,当我们读一句话时,大脑也会首先记住重要的词汇,这样就可以把注意力机制应用到自然语言处理任务中,于是人们就通过借助人脑处理信息过载的方式,提出了Attention机制。
self attention是注意力机制中的一种,也是transformer中的重要组成部分。自注意力机制是注意力机制的变体,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。自注意力机制在文本中的应用,主要是通过计算单词间的互相影响,来解决长距离依赖问题。
新框架
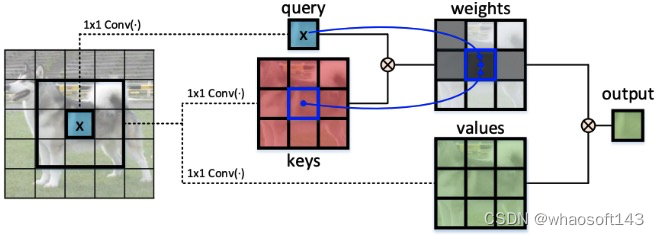
1、Multi-head Self-attention in Vision Backbones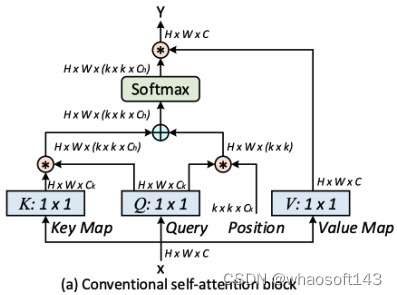
在这里,研究者提出了视觉主干中可扩展的局部多头自注意力的一般公式,如上图(a)所示。形式上,给定大小为H ×W ×C(H:高度,W:宽度,C:通道数)的输入2D特征图X,将X转换为查询Q = XWq,键K=XWk,值V = XWv,分别通过嵌入矩阵 (Wq, Wk, Wv)。 值得注意的是,每个嵌入矩阵在空间中实现为1×1卷积。
![]()
局部关系矩阵R进一步丰富了每个k × k网格的位置信息
![]()
接下来,注意力矩阵A是通过对每个头部的通道维度上的Softmax操作对增强的空间感知局部关系矩阵Rˆ进行归一化来实现的:A = Softmax(Rˆ)。将A的每个空间位置的特征向量重塑为Ch局部注意力后矩阵(大小:k × k),最终输出特征图计算为每个k × k网格内所有值与学习到的局部注意力矩阵的聚合:
![]()
2、Contextual Transformer Block
传统的自注意力很好地触发了不同空间位置的特征交互,具体取决于输入本身。然而,在传统的自注意力机制中,所有成对的查询键关系都是通过孤立的查询键对独立学习的,而无需探索其间的丰富上下文。这严重限制了自注意力学习在2D特征图上进行视觉表示学习的能力。
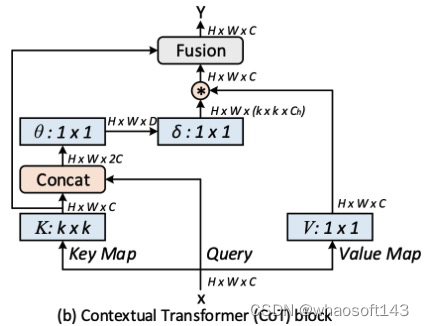
为了缓解这个问题,研究者构建了一个新的Transformer风格的构建块,即上图 (b)中的 Contextual Transformer (CoT) 块,它将上下文信息挖掘和自注意力学习集成到一个统一的架构中。
3、Contextual Transformer Networks
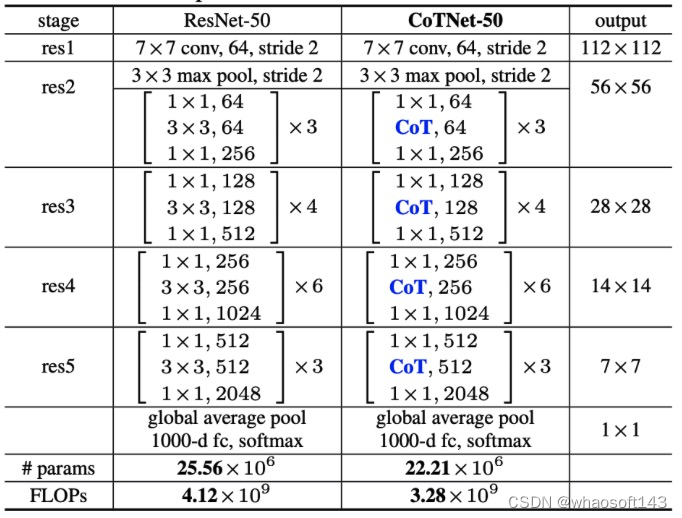
ResNet-50 (left) and CoTNet50 (right)
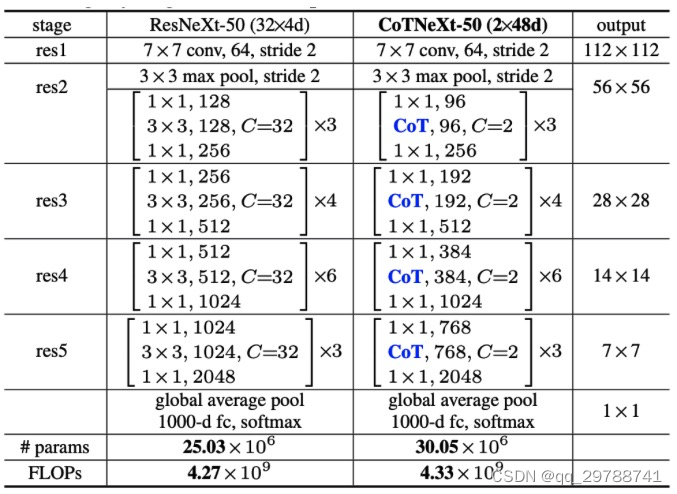
ResNeXt-50 with a 32×4d template (left) and CoTNeXt-50 with a 2×48d template (right).
实验及可视化
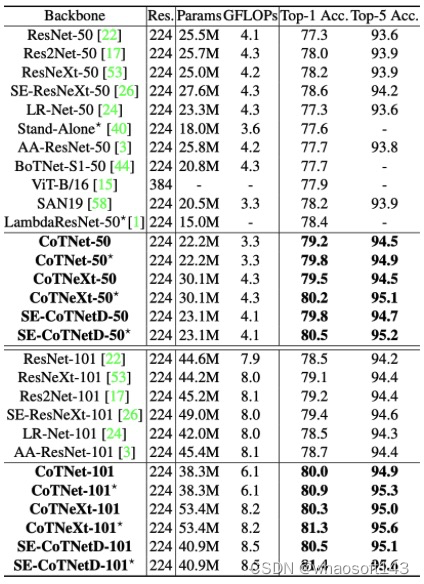
探索上下文信息的不同方式的性能比较,即仅使用静态上下文(Static Context),只使用动态上下文(Dynamic Context),线性融合静态和动态上下文(Linear Fusion),以及完整版的CoT块。 主干是CoTNet-50和采用默认设置在ImageNet上进行训练
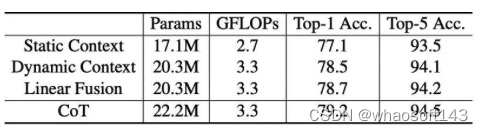
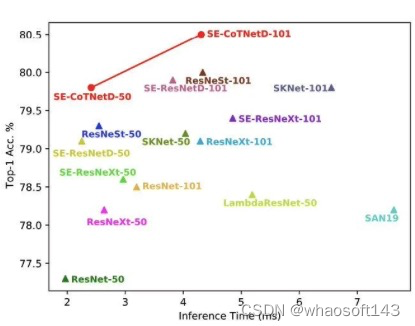
在ImageNet数据集上的Inference Time vs. Accuracy Curve
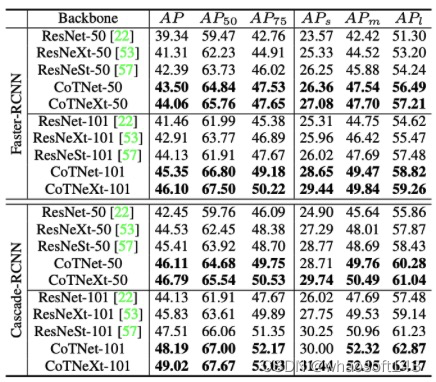
上表总结了在COCO数据集上使用Faster-RCNN和Cascade-RCNN在不同的预训练主干中进行目标检测的性能比较。 将具有相同网络深度(50层/101层)的视觉主干分组。 从观察,预训练的CoTNet模型(CoTNet50/101和CoTNeXt-50/101)表现出明显的性能,对ConvNets 主干(ResNet-50/101和ResNeSt-50/101) 适用于所有IoU的每个网络深度阈值和目标大小。 结果基本证明了集成self-attention学习的优势使用CoTNet中的上下文信息挖掘,即使转移到目标检测的下游任务。
不同主干的检测结果demo:

CoTNeXt-50

CoTNet50

CoTNet50

CoTNeXt-50
最后
以上就是震动小白菜最近收集整理的关于CoTNet的全部内容,更多相关CoTNet内容请搜索靠谱客的其他文章。








发表评论 取消回复