用Xpath方法提取网页内容保存为json格式
今天分享一下爬取知名技术网站的内容。网站地址:http://top.jobbole.com/38569/
用xpath提取网页内容,最后将爬取的内容保存为json格式。
- 用Xpath方法提取网页内容保存为json格式
- 打开虚拟环境在 Scrapy shell 中调试
- 提取标题文字
- 按照上述方法对文章作者评论数点赞数等进行提取
- items的编写
- Spider的编写
- pipelines 的设置
- settings 的编写
- 编写 main 函数
看到这个网页,首先分析需要爬取的内容:标题、点赞数、图片……
打开虚拟环境,在 Scrapy shell 中调试
提取标题文字
打开虚拟环境,输入 scrapy shell http://top.jobbole.com/38569/

在火狐浏览器中,F12调试,复制 xpath 路径
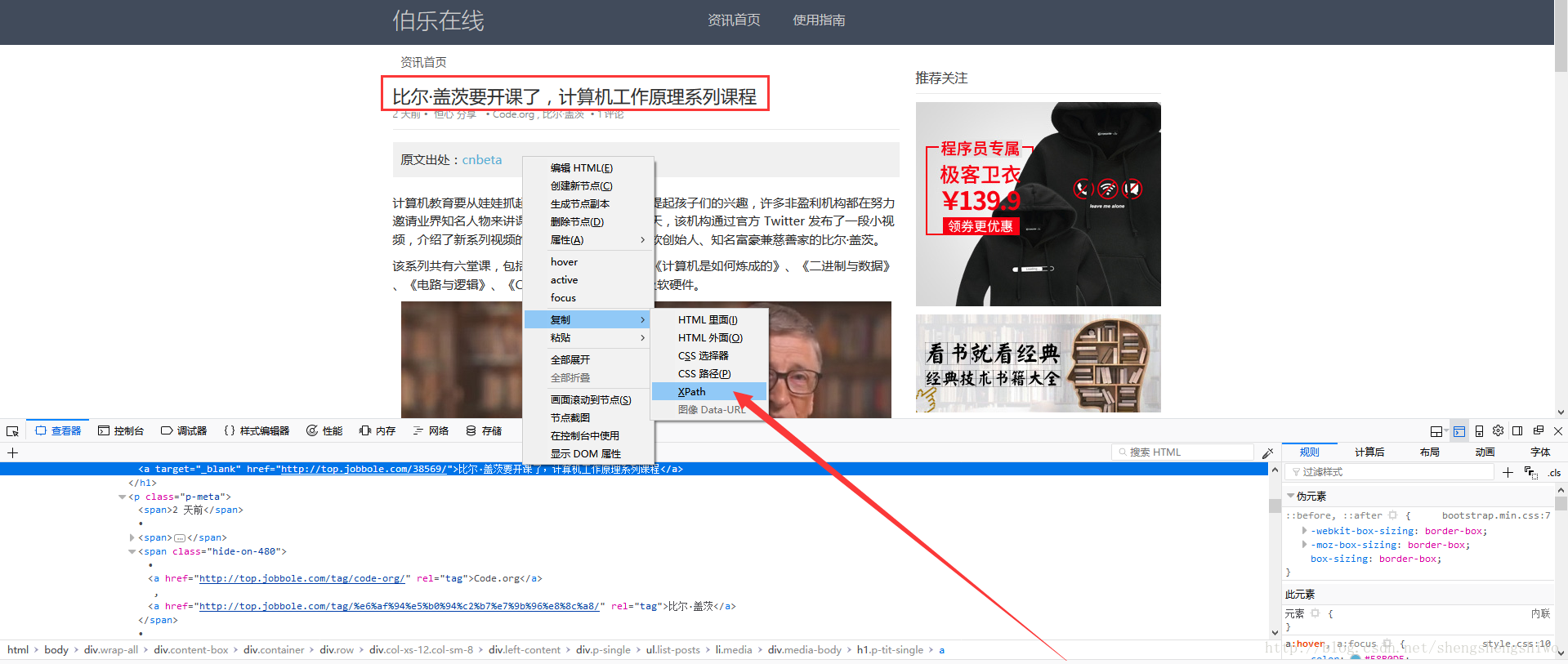
在 Scrapy shell 中输入复制的 xpath 路径

发现返回的值竟然为空。这是什么原因呢?
因为通过网页展示的页面,是通过JavaScript渲染过的页面,所以复制过的xpath路径,也就是有部分是JavaScript加上去的。通过右击,查看网页源代码,修改一下xpath路径。
通过把代码复制过来,查找修改为 /html/body/div/div/div/div/div/div/div/ul/li/div/h1/a'
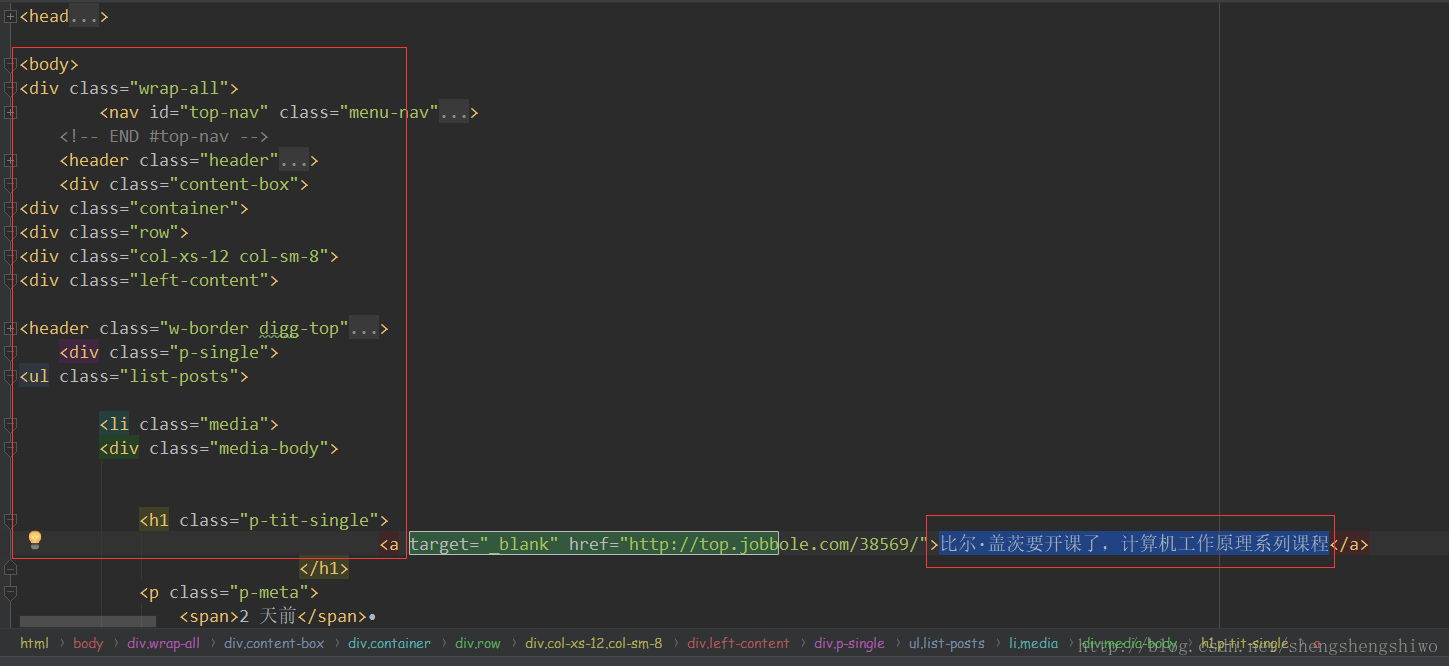
输入之后得到:

大家看到这个相信和我的心情一样,这种查找,会非常的恶心。有没有别的方法呢?答案当然是:有的!
再看一下源代码,发现所提取文字是在 <div class="media-body"> 之下的。所以可以用下面这种写法:response.xpath('//div[@class="media-body"]/h1/a/text()')

标题文字提取完了,把代码放到PyCharm中就OK了。

按照上述方法,对文章作者、评论数、点赞数等进行提取。
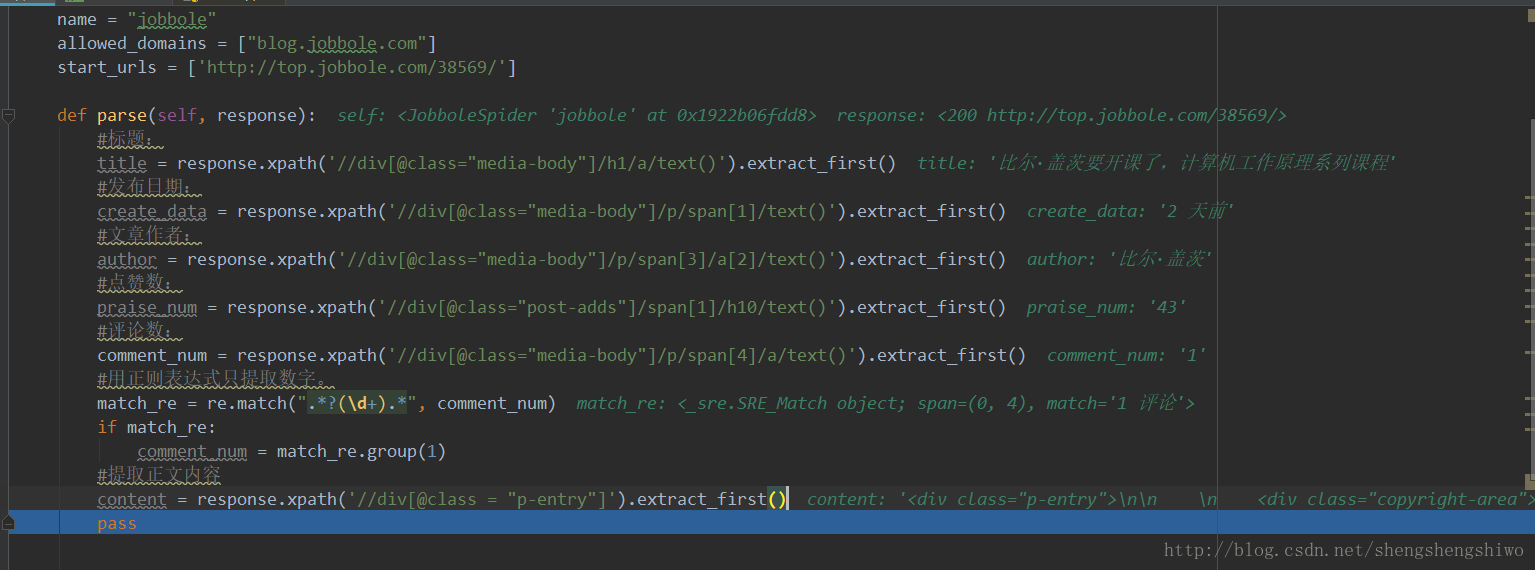
debug一下,发现要抓取的内容都可以实现。
下面把文件配置一下,抓取下来并保存为json格式。
items的编写
文件中有 items.py ,这个里面是用来封装爬虫所爬取的字段,如:标题、作者、时间等
import scrapy
class ArticleSpiderItem(scrapy.Item):
title = scrapy.Field()
create_data = scrapy.Field()
author = scrapy.Field()
praise_num = scrapy.Field()
comment_num = scrapy.Field()
content = scrapy.Field()
Spider的编写
Spider是用户编写从网站爬取数据的类。其中包含了用于下载的初始化URL,网页中的链接及分析网页中的内容,提取生成 item的方法。
# -*- coding: utf-8 -*-
import re
import scrapy
from ArticleSpider.items import ArticleSpiderItem
class JobboleSpider(scrapy.Spider):
name = "jobbole"
allowed_domains = ["blog.jobbole.com"]
start_urls = ['http://top.jobbole.com/38569/']
def parse(self, response):
article_item = ArticleSpiderItem()
#标题:
title = response.xpath('//div[@class="media-body"]/h1/a/text()').extract_first()
#发布日期:
create_data = response.xpath('//div[@class="media-body"]/p/span[1]/text()').extract_first()
#文章作者:
author = response.xpath('//div[@class="media-body"]/p/span[3]/a[2]/text()').extract_first()
#点赞数:
praise_num = response.xpath('//div[@class="post-adds"]/span[1]/h10/text()').extract_first()
#评论数:
comment_num = response.xpath('//div[@class="media-body"]/p/span[4]/a/text()').extract_first()
#用正则表达式只提取数字。
match_re = re.match(".*?(d+).*", comment_num)
if match_re:
comment_num = match_re.group(1)
#提取正文内容
content = response.xpath('//div[@class = "p-entry"]').extract_first()
article_item["title"] = title
article_item["create_data"] = create_data
article_item["author"] = author
article_item["praise_num"] = praise_num
article_item["comment_num"] = comment_num
article_item["content"] = content
yield article_item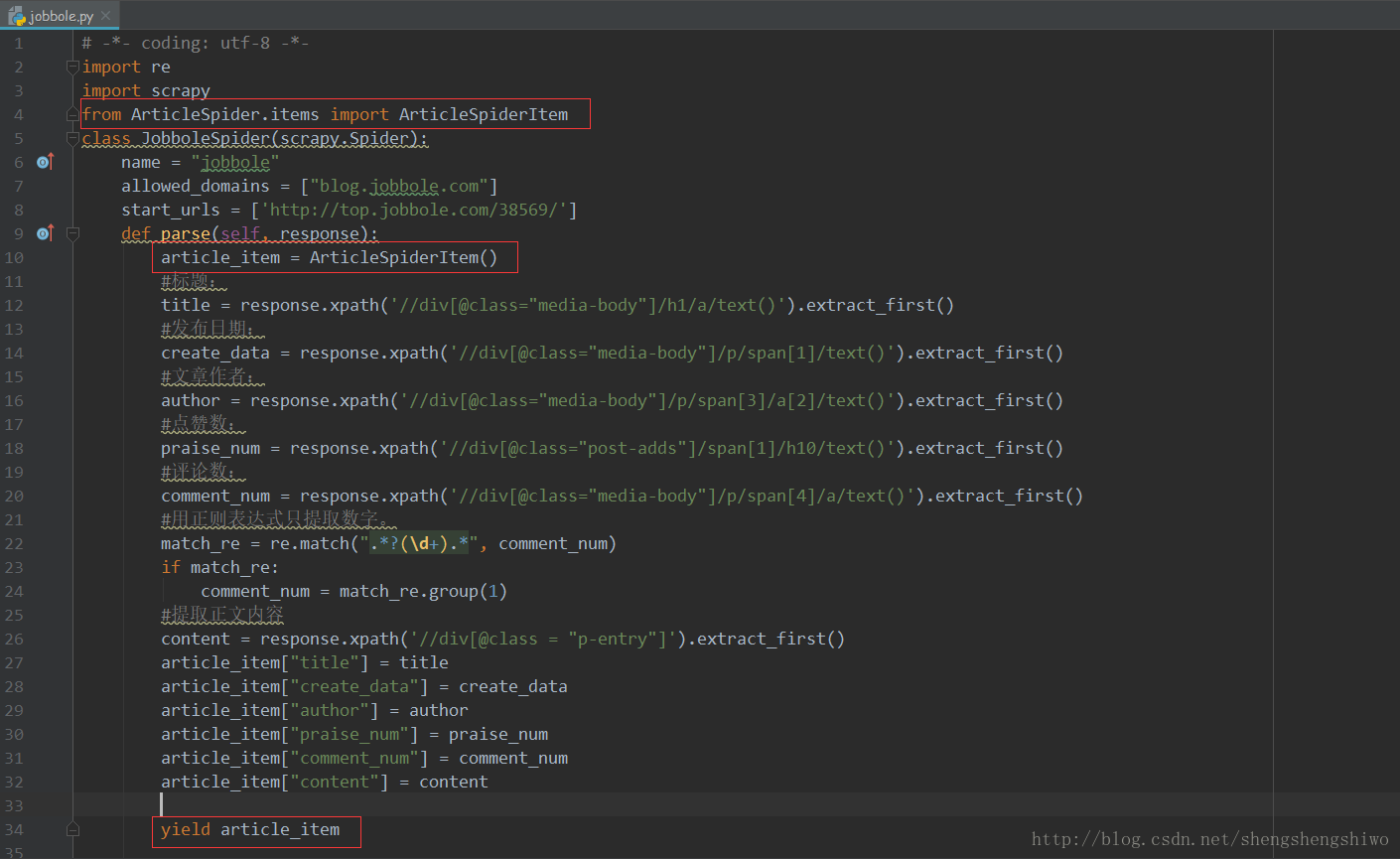
pipelines 的设置
对所抓取的内容进行 json 格式保存。
import json
import codecs
class JsonWithEncodingPipeline(object):
#自定义json文件的导出
def __init__(self):
self.file = codecs.open('Article.json', 'w', encoding="utf-8")
def process_item(self, item, spider):
lines = json.dumps(dict(item), ensure_ascii=False) + "n"
self.file.write(lines)
return item
def spider_closed(self, spider):
self.file.close()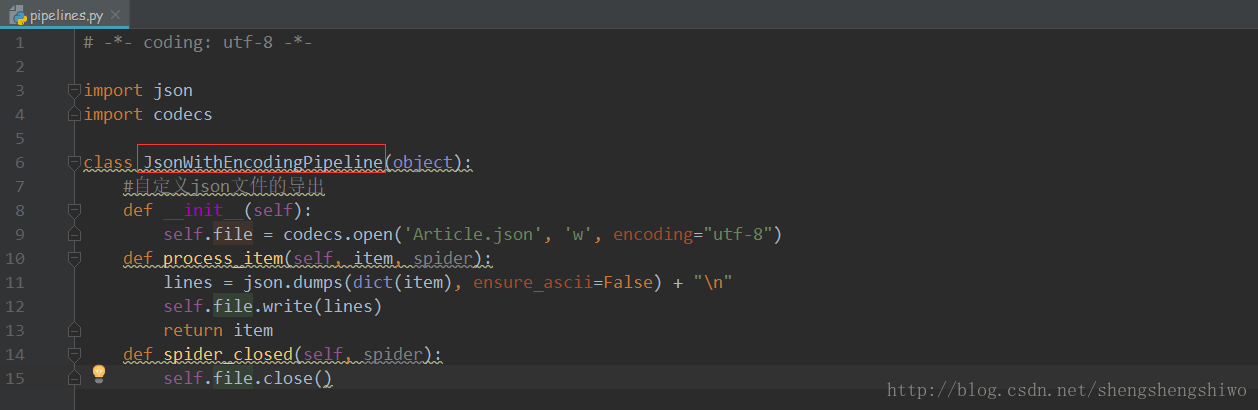
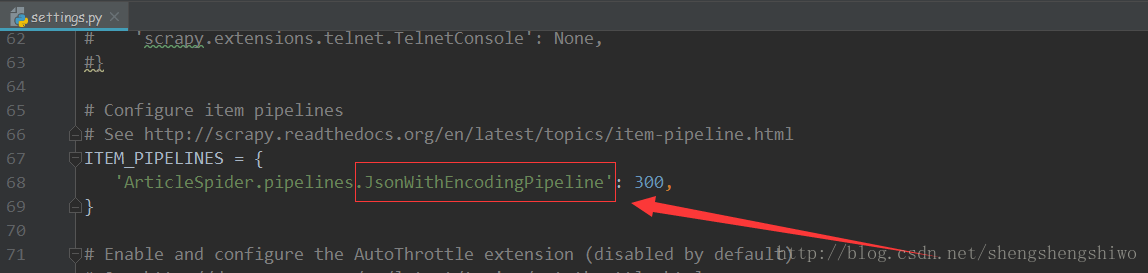
settings 的编写
主要是配置文件。
ITEM_PIPELINES = {
'ArticleSpider.pipelines.JsonWithEncodingPipeline': 300,
}
编写 main 函数
在PyCharm中运行爬虫
from scrapy.cmdline import execute
import sys
import os
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
execute(["scrapy", "crawl", "jobbole"])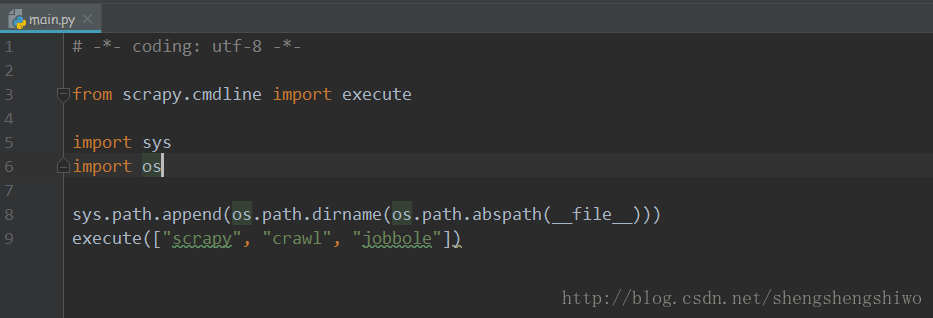
运行爬虫,文件生成。

编写代码已托管到Gitee上。
https://gitee.com/shengshengshiwo/YongXpathFangFaTiQuWangYeNaRongBaoCunWeijsonGeShi.git
最后
以上就是敏感芹菜最近收集整理的关于用xpath方法提取网页内容保存为json格式用Xpath方法提取网页内容保存为json格式打开虚拟环境,在 Scrapy shell 中调试items的编写Spider的编写pipelines 的设置settings 的编写编写 main 函数的全部内容,更多相关用xpath方法提取网页内容保存为json格式用Xpath方法提取网页内容保存为json格式打开虚拟环境,在内容请搜索靠谱客的其他文章。








发表评论 取消回复