xpath 功能强大,多快好省,但我们只用到很少一部,没必要学全,json数据格式方便快捷,但对python来讲,只用4个方法足矣!本节将对这两大功能模块做简略式介绍。
xpath总是返回一个列表。它要么用于找url地址,要么找结构中的文本,别的也用不着它,所以得有针对性去学习。
xpath对xml或html高效检索定位,所以检索对象应先转成xml或html,获取html的方式有两种,一种是从外部直接导入html文件,一种是在python中把生成的字符串直接转成html。etree模块对不同方式有专门转换函数。
从外部文件导入html=etree.parse(‘xxx.html’,etree.HTMLParser())
data = html.xpath(’…’)
此方法便能重构原xxx.html文件,并返回此文件,之后便可用xpath定位元素了。
etree模块能够重构原html文件,修复原文件中缺失的语句,调⽤ tostring() ⽅法即可输出修正后的 HTML 代码,但结果是 bytes 类型,可以⽤decode() ⽅法将其转化为 str 类型。
txt = etree.tostring(html).decode(‘utf-8’)
此txt为类似html形式的纯文本格式数据。
从python中转换
python中创建的类似html形式的字符串经过etree.HTML()方法重构成纯html格式数据,方便xpath定位,其实没有人在python中手写这种html形式的字符串,它就是python爬虫返回的response.text文本数据,xpath查询的数据也基本上都是这类数据来源。
response = requests.get(url).text
html = etree.HTML(response)
data = html.xpath(’…’)
定位查询
/ 子节点
直系子节点,只定位指定元素的直接子元素。
‘//div/ur/li’
// 孙节点(跳级)
跳级查询,与指定元素最少相隔两级。
‘/div//li’
. 当前节点
把之前查询过的当成根节点继续从此节点往下查。
li = ‘//div//li’
img = li ‘./a/img’
… 父节点
有些元素不好定位,可以用父节点来定位。
'//div/table//…/li
@ 属性查询 [@attr=‘属性值’]
‘//div[@class=‘no-asde’]//a/@href’
‘//div[’@id=‘faswe’]/ur//a[@class=‘ddff’]’
and 并列查询
[@attr=‘属性值’ and @attr=‘属性值’]
‘//div[@class=‘abc’ and @name=‘ggff’]’
text() 选取文本
‘//div//a/text()’
‘//div//[text()=‘ffgg’]’
extract() 提取内容
contains() 包含查询
[contains(text(),‘包含值’)]文本值模糊查询法,只要文本内包含指定值,就能找到。
[contains(@attr,‘包含值’)]属性值模糊查询法,只要属性值内包含指定值就能找到。
start_with() 以某某开头查询(支持文本或属性查询)
[start_with(text(),‘开头值’)]文本值查询法,只要文本以指定值开头就能查到。
[start_with(@attr,‘开头值’]属性查询法,只要属性值开头包含指定值,就能查到。
*匹配所有元素节点
@* 匹配所有属性
node() 匹配任何类型节点
/div/* div中所有元素
//* 选取文档所有内容
//title[@*] 选取所有属性为title的元素
svg元素查询,svg是一个特殊元素,常用xpath定位不了,得专用方法。[name()=‘svg’]
例子:
获取所有节点
result = html.xpath(’//*’)
所有孙节点li下的子节点
ahtml.xpath(’//li/a’)
所有指定a节点的父节点的class属性
html.xpath(’//a[@href=“link4.html”]/…/@class’) #一种方法
html.xpath(’//a[@href=“link4.html”]/parent:????/@class’) #二种方法
所有指定属性的
lihtml.xpath(’//li[@class=“item-inactive”]’)
获取指定属性li下a的文本
html.xpath(’//li[@class=“item-0”]/a/text()’)
#建议使用此法
html.xpath(’//li[@class=“item-0”]//text()’)
#会额外获得多余符号
属性多值匹配
html.xpath(’//li[contains(@class, “li”)]/a/text()’)
多属性匹配
html.xpath(’//li[contains(@class, “li”) and @name=“item”]/a/text()’)
json
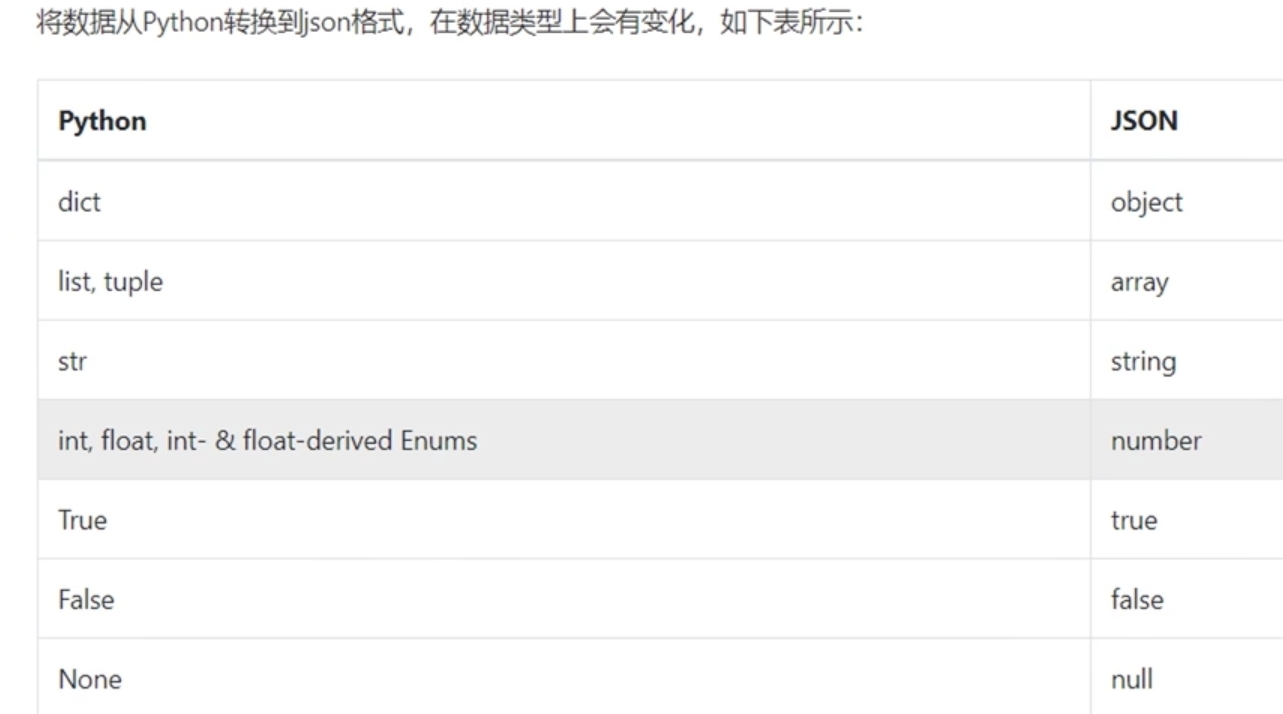
python中的json只做两件事,把json对象转成python格式,把python対象转成json。在python中出现的json数据都是字符串类型,尽管看上去与字典很像,但仍是字符串格式。
penser = {‘name’:‘sb’,‘age’:18,‘tel’:[123456,09876],‘sex’:‘man’}
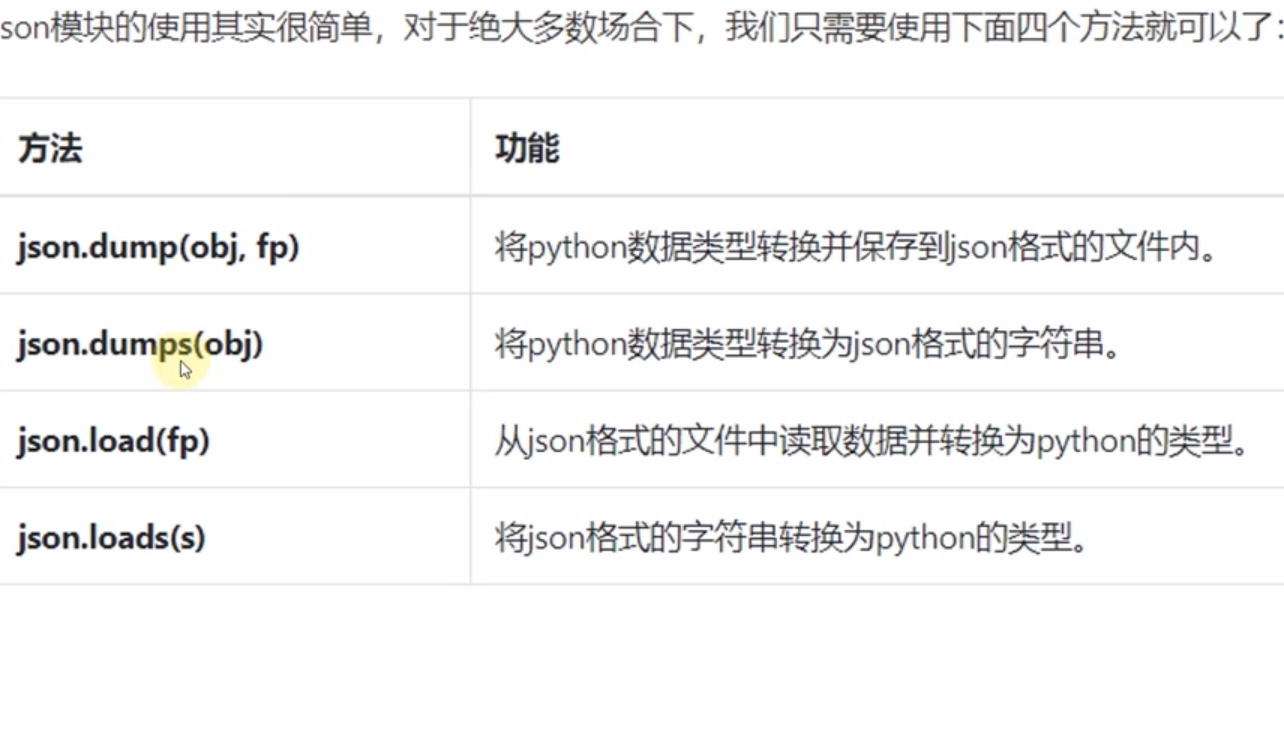
一,json转python用load
json.load(fp):
从json文件中导入数据为python格式。
json.loads(s):
将json格式的字符串转成python类型。
二,python转json用dump
json.dump(obj,fp,[indent=int,sort_keys=True])
把python数据转换并保存到json文件内。
json.dump(penser,with open(‘data.json’,'w)json.dumps(obj,[indent=int.sort_keys=True])
把python数据转换为json字符串。
indent可选,为格式化缩进数,一般为4个缩进。
sort_keys为是否排序,它会把键名按升序排序。

最后
以上就是虚拟诺言最近收集整理的关于python.xpath和json针对性诠释的全部内容,更多相关python内容请搜索靠谱客的其他文章。








发表评论 取消回复