本博客记录作者在工作与研究中所经历的点滴,一方面给自己的工作与生活留下印记,另一方面若是能对大家有所帮助,则幸甚至哉矣!
简介
文本分类方法大部分使用基于模型的分类,基本上可以分为两大类:1)基于规则的分类方法,采用为类别集合的每个类别确定分类规则,然后根据类别模板统计待分类文本,确定该文本所属类别。基于规则的文本分类方法主要有:决策树、关联规则和粗糙集等;2)基于统计的分类方法,使用分类模型自动根据训练集中的信息自动学习,从而构造出文本特征和类别之间的对应关系模型,利用训练好的模型对待分类文本进行分类。基于统计的文本分类方法主要有:朴素贝叶斯、支持向量机、K均值等。
基于规则的分类方法采用特定的分类规则,比较理性,符合行为认知;基于统计的分类方法依赖机器学习的经验,根据概率统计方法确定分类,能取得较好的分类效果。从整体上看,基于规则和统计的分类方法各有千秋,目前的主要研究方向为采用两者的结合,提高分类的精确度。
需要指出,本文为贯通Web数据抓取和文本处理环节,采用基于规则的分类方法实现情感分析算法。
算法设计
情感分析架构图
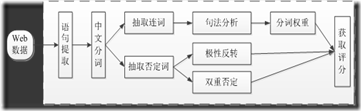
图1 情感分析框架图
鉴于目前文本处理多数集中于句子级分析,因此本文也采用句子级分析方式,其处理过程主要分为语句提取、特定词抽取、句法分析以及计算评分。简要描述如下:
1) 语句提取:根据中文文本的特点,以句号、问号以及感叹号对文本进行分割。
2) 特定词抽取:针对句子,抽取其中的连词以及否定词,从而辅助判断情感分析。
3) 句法分析:根据连词确定句子前后的分词权重,针对否定词确定极性反转或双重否定识别。
4) 计算评分:根据情感词汇库以及句法分析结构,综合计算该句子评分。
特定词提取
1) 连词
根据参考文献分析,在情感分析时,有指示特征的连词特征为:
并列连词:前后句子极性一致;
选择连词:前后句子极性一般一致;
递进连词:前后句子极性一般一致,后句稍加强烈;
转折连词:前后句子极性相反,后句更加强烈。
其它连词类型对情感倾向不敏感,目前暂不予考虑。若后期对算法优化,可以予以增加。
表1 连词及其关联权重
标识
关系类型
前句权重
后句权重
举例
1
并列关系
0.5
0.5
既,又
2
选择关系
0.5
0.5
,或者
3
递进关系
0.4
0.6
不但,而且
4
转折关系
0.2
0.8
虽然,但是
5
选择关系
0.4
0.6
与其,宁肯
6
选择关系
0.6
0.4
宁愿,绝不
如表1所示,为本文算法采用的连词及其关联权重,判断前句与后句的主要以第二个连词作为区分;若仅有一个连词,则以该唯一连词作为区分对象。
2) 否定词
否定词在文本中具有独特的语法意义和影响,一般情况下,被否定词修饰的词汇一般会改变情感极性。此外,由于中文中存在多重否定的现象,鉴于双重否定所占比例较大,本文算法仅考虑双重否定该情形。
本文暂时拟定的否定词为:不、无、非、莫、勿、未、不要、不必、没有等。若后期对算法进行优化,则视情形进行增加与删减。
评分计算
本文情感极性词汇库采用大连理工大学情感词汇本体,根据实际应用需求,对该词汇库进行补充与修正,同时引入连词规则以及否定词等进行辅助计算。
计算过程为:
1) 将Web文本进行分句,使其以句子为单位进行处理;
2) 从分句中抽取连词和否定词,并标记相应连词与否定词位置;
3) 访问情感词汇本体,确定词汇极性及其强度;
4) 针对连词(若有),通过连词连词位置,确定前句与后句所占比重,针对否定词(若有),根据否定词位置判断双重否定,以及临近词汇的极性反转;若不包含连词或者否定词,则略过该步骤;
5) 累加本句情感计算评分;
6) 循环访问步骤2)至步骤5)计算该Web文本的评分,若为正则为正面,若为负则为负面,否则为中性。
展望
本文算法目前采用基于规则的分类方法,通过引入关联规则(连词、否定词)对句子进行分析,计算出其情感倾向,进而引申至全文的情感倾向。从应用的角度,该方法能满足用户一般性需求。
另一方面,由于汉语语法复杂,而且涉及的规则呈现多样化、复杂化,若要获取精确的情感分类,采用基于统计的方法与基于规则的方法相结合,将是后期进行优化的研究方向。
参考文献
[1] 李亚珍,李晓戈,于根. 基于中文股票博客的情感分类[J]. 武汉大学学报(理学版): 2015, 61(2):163-168.
[2] 李实,叶强,李一军等. 挖掘中文网络客户评论的产品特征及情感倾向[J]. 计算机应用研究:2010, 27(8):3016 -3019.
[3] 乌达巴拉,汪增福. 一种扩展式CRFs的短语情感倾向性分析方法研究[J]. 中文信息学报:2015, 29(1):155-162.
作者:志青云集
出处:http://www.cnblogs.com/lyssym/p/4880896.html
如果,您认为阅读这篇博客让您有些收获,不妨点击一下右下角的【推荐】。
如果,您希望更容易地发现我的新博客,不妨点击一下左下角的【关注我】。
如果,您对我的博客所讲述的内容有兴趣,请继续关注我的后续博客,我是【志青云集】。
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。
最后
以上就是热情黄豆最近收集整理的关于mysql做文本挖掘_文本挖掘之文本情感分析的全部内容,更多相关mysql做文本挖掘_文本挖掘之文本情感分析内容请搜索靠谱客的其他文章。








发表评论 取消回复