1. 问题背景
在我们日常的业务中,数据往往以库表的形式呈现,数据生产和数据消费则分别对应着库表的创建和查询。对于ClickHouse而言,数据的生成是上游库表的同步导入,数据的消费是用户通过诸如BI平台等服务对库表进行查询。理论上,按照业务的需求,每个ClickHouse的表都应该有一个相应的生命周期,假设所有的表都以天粒度为分区,则某些表往往只需要保留一周或一个月的数据,其它有一些表可能需要保留三个月或半年,可见不同的表生命周期应该是不一样的。但问题在于如何为每个表设定合适的生命周期?过长的生命周期会造成存储资源的浪费,占满ClickHouse集群的磁盘空间,而过短的生命周期可能不能满足业务方的需求,导致查不出需要的数据。
我们过往的做法是,在ClickHouse入库前,让用户填写生命周期。但这样的做法并未能从根本上解决问题,究其原因总结下来有以下几点:
随着业务发展,业务方对于同一张表的生命周期的需求也在不断地发生变化。一开始需要存储一年的数据,经过一段时间之后可能只需要一个月甚至已经逐渐废弃无人问津,但业务方可能并不会去修改这个生命周期。
业务方有时候自己也并不知道生命周期要设多久才合适,这种情况下用户一般会选择偏大的生命周期,但最终使用的时候其实只用了最近几天的数据,以致于造成ClickHouse集群磁盘空间的浪费。
最初建表的用户并不一定是查询数据的用户,通常某一张表建立之后,会有多个用户同时使用这一张表,真正使用该表的用户往往对生命周期是无感的,他们不一定有义务或者并不一定能意识到表生命周期的问题。最初填写生命周期的用户可能在一段时间之后也离职了。
综合上述的几个因素,我们需要一套自动探测ClickHouse库表生命周期的解决方案,降低生命周期的人工干预成本,做到更精确地评估库表生命周期,从而进一步提高ClickHouse集群磁盘空间利用率,降低查询响应时延(减少不必要的数据扫描时间)。
为了解决这一问题,我们从ClickHouse的审计日志中对历史SQL进行分析,得出一段时间内每个表在查询时所涉及到的最大分区范围(SQL所覆盖的分区字段的天数),进而根据分区范围作为表的生命周期。
2. 解决方案: 结合历史SQL解析的表生命周期管理方法
2.1 整体思路
整体思路可以拆解为以下几步:
从审计日志中筛选出近10天内接受过的所有SQL请求。
利用AST Parser对SQL进行解析,找出每个SQL所涉及到的表及其分区范围。
统计所有的表所涉及到的最大分区范围,将最大分区范围设置为该表的生命周期。
上述的几个步骤中,最为关键的是第二步,需要根据SQL解析出所涉及到的分区范围。
2.2 基于AST Parser解析SQL的分区范围
为了解析SQL的分区范围,在实现层面首先要将SQL解析成AST,随后再对AST进行遍历找到所涉及到的分区范围,如图1所示:
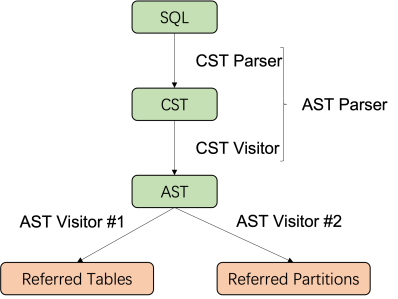
图1 解析SQL分区范围的过程
其中,遍历AST时有以下几个关键的步骤需要实现:
遍历AST,遍历过程中需要获取到ClickHouse的元数据信息(包括表的分区字段名等),最后在遍历AST的对比表达式节点时,解析出所有与分区字段名相关的过滤条件;
合并过滤条件得出最终的分区范围。
举例来说,下面的这一段SQL,在经过第二步之后会得出如图2所示左右两边的两个分区范围,进一步合并之后得到一个完整的分区范围。需要注意的是,合并的过程需要考虑到到底是要取并集还是交集。
SELECT
*
FROM t1
WHERE
(ftime >= '2021-09-01' AND ftime <= '2021-09-10')
OR ftime IN ('2021-08-01', '2021-08-02')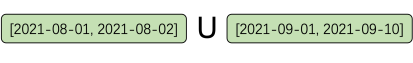
图2 分区范围合并
所涉及到的AST解析的代码已经抽取成ClickHouse AST Parser,有需要的同学可以参考使用 https://github.com/JiamingMai/clickhouse-ast-parser
2.3 ClickHouse AST Parser的使用
ClickHouse AST Parser不仅仅是一个SQL语法的解析器,而是一个提供了AST 相关搜索功能的工具,主要的应用场景在于将SQL语句转换为 AST,并进一步利用解析后的结果。
目前ClickHouse AST Parser实现了以下几种场景:
给定SQL语句,找出与该SQL相关的表名。基于它可以实现热点表分析、缓存机制等功能。
String sql = "SELECT t1.id, count(1) as total_count FROM my_db1.table1 t1 LEFT JOIN my_db2.table2 t2 ON t1.id = t2.id GROUP BY t1.id";
AstParser astParser = new AstParser();
INode ast = (INode) astParser.parse(sql);
ReferredTablesDetector referredTablesDetector = new ReferredTablesDetector();
// tables should be ["my_db1.table1", "my_db2.table2"] in this caseList<String> tables = referredTablesDetector.searchTables(ast);其中,AstParser可以解析SQL,得到对应的AST。ReferredTablesDetector用于检测SQL中所涉及到的所有表
给定SQL语句,找出该SQL所涉及到的分区范围。
// we need to implement MetadataService first
MetadataService metadataService = new MetadataService() {
@Override
public String getPartitionColName(String tableFullName) {
// TODO: implement this method
return null;
}
@Override
public List<String> getTables() {
// TODO: implement this method
return null;
}
};
String todayDate = "2022-01-01"; // for parsing UDF like today() and yesterday() in the SQL
String targetIP = "127.0.0.1"; // the node to get metadata
ReferredPartitionsDetector referredPartitionsDetector = new ReferredPartitionsDetector(todayDate, targetIp, metadataService);
List<String> partitionRangeList = referredPartitionsDetector.searchTablePartitions(ast);其中,ReferredPartitionsDetector用于检测SQL中所涉及到的所有表及其分区范围,使用时需要传入一个MetadataService的实现类,用于获取ClickHouse的元数据。
public interface MetadataService {
String getPartitionColName(String tableFullName);
List<String> getTables();
}抽取Distributed引擎表的参数信息。ClickHouse的Distributed引擎给予了我们灵活的数据组织方式,但有时我们确实需要提取Distributed引擎表里的相关信息,比如所涉及到的cluster、database和table。单纯使用正则表达式来提取很容易出错,尤其是当CREATE TABLE建表语句中有复杂的注释时,容易抽取出注释的内容。通过AST解析可以比较好地解决这个问题。
String sql = "CREATE TABLE my_db.my_tbl (date Date, name String) Engine = Distributed('my_cluster', 'my_db', 'my_tbl_local', rand())";
DistributedTableInfoDetector distributedTableInfoDetector = new DistributedTableInfoDetector();
// clusterName is "my_cluster"
String clusterName = distributedTableInfoDetector.searchCluster(sql);
// tableFullName is "my_db.my_tbl_local"
String tableFullName = distributedTableInfoDetector.searchLocalTableFullName(sql);改写SQL,优化效率。目前只实现了对JOIN操作增加GLOBAL关键字,更多的改写逻辑可以在日后更新,帮助提高SQL效率,在解析层屏蔽掉慢查询SQL。
String sql = "SELECT t1.id, count(1) as total_count FROM my_db1.table1 t1 LEFT JOIN my_db2.table2 t2 ON t1.id = t2.id GROUP BY t1.id";
AstParser astParser = new AstParser(false);
SelectUnionQuery ast = (SelectUnionQuery) astParser.parse(sql);
GlobalJoinAstRewriter globalJoinAstRewriter = new GlobalJoinAstRewriter();
String rewrittenSql = globalJoinAstRewriter.visit((INode) ast);
// the rewritten SQL should be:
// SELECT t1.id, count(1) as total_count FROM my_db1.table1 t1 GLOBAL LEFT JOIN my_db2.table2 t2 ON t1.id = t2.id GROUP BY t1.id各个使用的方法也可以测试用例中找到。
4. 效果表现及后续工作
通过本文方法对ClickHouse库表生命周期进行梳理后,我们发现了大量的表设置了过长的生命周期,最终集群内有大概1/3的冗余数据可以清理,大幅度减少了整体的磁盘空间占用率,降低了查询时延。目前对于较为复杂的SQL还没有办法解析出分区范围,还需要进一步完善,也欢迎各位同学一起参与完善。也可以基于本文方法将估算得出的生命周期推送给业务方,让业务方确认,询问生命周期是否合理。
作者介绍:麦嘉铭,前后就职于阿里云和BIGO,目前在腾讯音乐参与大数据分析平台建设,主要负责Clickhouse和Presto的运维和开发
最后
以上就是清新豌豆最近收集整理的关于如何结合SQL解析,设置ClickHouse表的最佳生命周期?1. 问题背景2. 解决方案: 结合历史SQL解析的表生命周期管理方法4. 效果表现及后续工作的全部内容,更多相关如何结合SQL解析,设置ClickHouse表的最佳生命周期?1.内容请搜索靠谱客的其他文章。








发表评论 取消回复