OLAP数据库-ClickHouse,其中有个重要的概念就是分片(shard)。
分区是表的分区,具体的DDL操作关键词是 PARTITION BY,指的是一个表按照某一列数据(比如日期)进行分区,对应到最终的结果就是不同分区的数据会写入不同的文件中。
分片复用了数据库的分区,相当于在原有的分区下,作为第二层分区, 是在不同节点/机器上的体现。
具体关系如下:
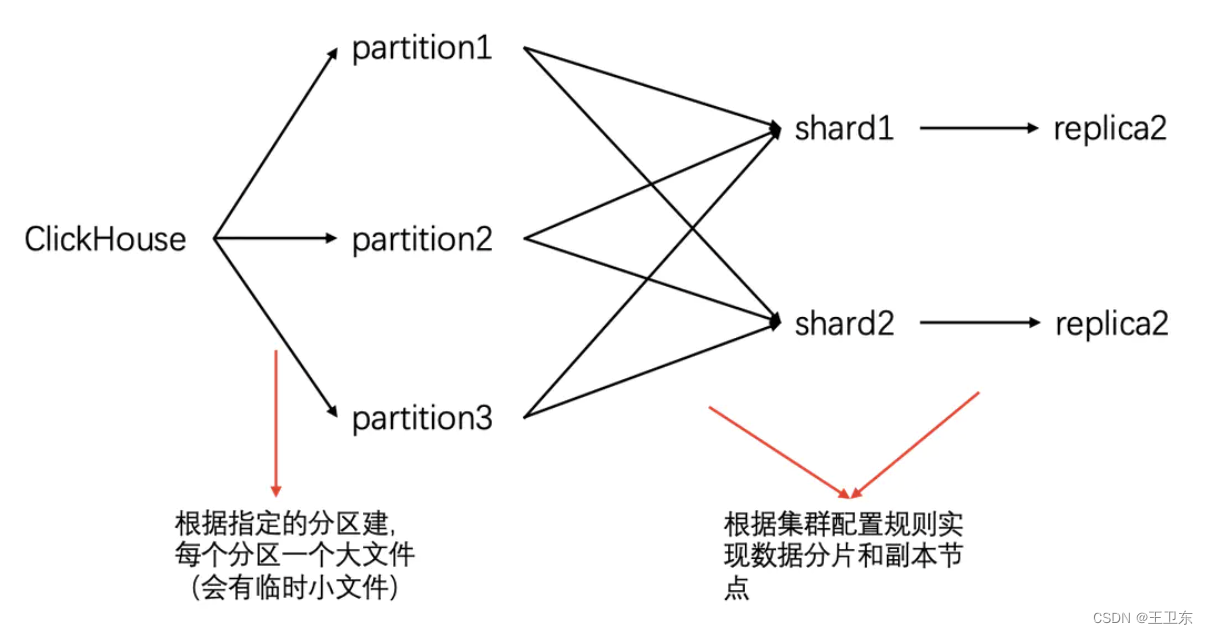
数据分区-允许查询在指定了分区键的条件下,尽可能的少读取数据
数据分片-允许多台机器/节点同并行执行查询,实现了分布式并行计算
数据Sharding
ClickHouse支持单机模式,也支持分布式集群模式。在分布式模式下,ClickHouse会将数据分为多个分片,并且分布到不同节点上。不同的分片策略在应对不同的SQL Pattern时,各有优势。ClickHouse提供了丰富的sharding策略,让业务可以根据实际需求选用。
1) random随机分片:写入数据会被随机分发到分布式集群中的某个节点上。
2) constant固定分片:写入数据会被分发到固定一个节点上。
3) column value分片:按照某一列的值进行hash分片。
4) 自定义表达式分片:指定任意合法表达式,根据表达式被计算后的值进行hash分片。
数据分片,让ClickHouse可以充分利用整个集群的大规模并行计算能力,快速返回查询结果。
更重要的是,多样化的分片功能,为业务优化打开了想象空间。比如在hash sharding的情况下,JOIN计算能够避免数据shuffle,直接在本地进行local join;支持自定义sharding,可以为不同业务和SQL Pattern定制最适合的分片策略;利用自定义sharding功能,通过设置合理的sharding expression可以解决分片间数据倾斜问题等。
另外,sharding机制使得ClickHouse可以横向线性拓展,构建大规模分布式集群,从而具备处理海量数据的能力。
不过ClickHouse的集群的水平拓展目前是一个瓶颈,因为历史数据的存在, 避免新增节点之后的数据倾斜是个难点。
数据Partitioning
ClickHouse支持PARTITION BY子句,在建表时可以指定按照任意合法表达式进行数据分区操作,比如通过toYYYYMM()将数据按月进行分区、toMonday()将数据按照周几进行分区、对Enum类型的列直接每种取值作为一个分区等。
数据Partition在ClickHouse中主要有两方面应用:
在partition key上进行分区裁剪,只查询必要的数据。灵活的partition expression设置,使得可以根据SQL Pattern进行分区设置,最大化的贴合业务特点
对partition进行TTL管理,淘汰过期的分区数据。
文章来源:https://www.jianshu.com/p/178a01e0ae6e
参考文章:自定义分区键 | ClickHouse Docs
最后
以上就是淡定金毛最近收集整理的关于ClickHouse分片和分区的理解的全部内容,更多相关ClickHouse分片和分区内容请搜索靠谱客的其他文章。








发表评论 取消回复