概述
MergeTree家族引擎是ClickHouse在生产中最常用,也是功能最强大的引擎,只有这种引擎才有主键索引(主键值不需要唯一),二级索引分区,副本和数据采样的特性.MergeTree引擎家族有:
MergeTree
ReplacingMergeTree
SummingMergeTree
AggregatingMergeTree
CollapsingMergeTree
VersionedCollapsingMergeTree
MergeTree引擎创建表语句:
CREATE TABLE [IF NOT EXISTS] [Database.] TABLENAME(
FIELDS1 Type [Default xx] [MATERIALIZED expr] [ALIAS expr] TTL xxx,
FIELDS1 Type[Default xx] [MATERIALIZED expr] [ALIAS expr] ,
......
)ENGINE = xxxMergeTree
ORDER BY (FIELD | expr)
[PARTITION BY (FIELD | expr) ]
[PRIMARY KEY(FIELD | expr) ]
[SAMPLE BY (FIELD | expr)]
TTL expr [+ INTERVAL XX SECOND/MINUTE/HOUR/DAY]
[SETTINGS XXX=XXX,XXXX=XXX]
ttl写法: name String TTL create_time + INTERVAL 1 DAY
order by:指定排序字段或者表达式(必填);
partition by 指定分区键或者分区表达式,通常情况下我们会指定日期格式分区键,如果是DateTime类型可以用toYYYYMM() toYYYYMMDD()来做月纬度日纬度分区,如果不指定,那就只有一个分区.
primary key:指定主键
sample by:抽样表达式,用于数据采样
TTL xxxx:设置数据的TTL过期时间(这里是行级TTL,字段级别TTL会以默认值填充)
settings:一些配置,最常用index_granularity =8192(默认),指定索引粒度
MergeTree中的order by是不能少的,也就是排序键,如果不指定primary key 那么order by自定的字段或表达式,就会成为主键,并且绝大部分情况是不需要额外指定一个primary key主键的,即使要指定,也只能指定为order by 的前缀字段,比如order by(id,name), primary key 只能指定id或者(id,name)
sample by必须包含在主键声明之中,并且必须是无符号Int类型,如sample by intHash64(id),使用时,表中数据量要大于一个粒度(8192)
select * from test sample 0.1 (取值0-1之间) 去0.1因子的数据
select * from test samle 100 至少取100行
select * from test sample 0.1 offset 0.5 从0.5因子开始取0.1因子的数据
MergeTree中的索引是稀疏索引,索引要想起到快速检索的效果就需要排序,而稀疏索引就是根据order by排序,并且指定一个粒度(index_granularity =8192),是将数据排好后,每隔8192行数据取一个主键值,这样做的好处是可以生成的索引会很小,一亿条数据生成索引个数也就10000多,常驻内存用于快速检索.
MergeTree在写入数据时总是以数据段的形式写入磁盘(一次insert语句中同分区的数据),后台线程会异步执行分区数据合并.数据存储在/var/lib/clickhouse/data/目录下.
数据目录由一个或多个分区组成

上方的19921012_1_3_1与19931011_2_4_1分别是按照yyyymmdd字段分区生成的19921012分区与19931011分区,至于分区后跟的三个数字就不解释了,只需要知道最后一个数字代表着当前分区的合并次数就好.另外,分区目录可能不止一个,比如还会有其他的19921012_x_x_0的目录,这种情况下是有新的19921012分区数据插入,但是后台还没有执行分区合并,或者分区合并后,还未删除新插入的数据目录.
采用列式存储,分区目录下的存储结构:
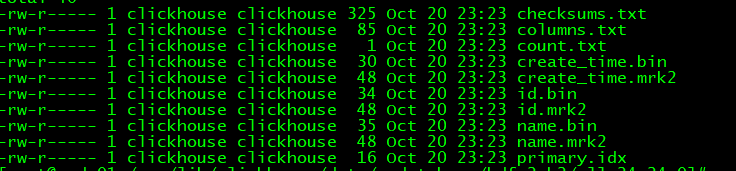
checksums.txt:保存了其他文件的大小
columns.txt:保存了字段的信息.
count.txt:保存了当前分区目录下数据的总行数
id.bin:保存了id列的实际数据压缩文件(默认LZ4)
id.mrk2列字段的标记文件保存了id.bin文件中数据的偏移量
primary.idx:一级索引文件
还有一些其他文件(不同条件下生成的)就不列举了,了解一下就好.
另外因为MergeTree引擎的合并策略,所以有很多时候在合并前查询结果是不准确的,有两种方式,第一种是调用optimize table tableName的方式强制合并之后再查询,第二种方式是查询时在sql语句最后加入final,如select * from test final
1 MergeTree引擎:
该引擎没有特殊功能,适合保存历史明细.
该引擎是MergeTree家族的最基础的表引擎.上面讲述了一部分原理,这里就省略了.
create table tableName(xxx)engine=MergeTree xxxx....
2 ReplacingMergeTree引擎
该引擎适合于经常要根据’主键’进行数据更新的数据(upsert),主键加引号是因为,其实是根据order by定义的字段而不是根据primary key的字段去重的.
create table rmTest(
id Int8,
name String,
date Date,
score Int8
)engine =ReplacingMergeTree
order by (id,name)
primary key id
partition by date;
插入数据
insert into rmTest values
(1,'zhangsan','2020-10-10',89),
(1,'zhangsan','2020-10-10',88),
(1,'lisi','2020-10-10',90),
(1,'zhangsan','2020-10-11',91);
查询数据
select * from rmTest;
┌─id─┬─name─────┬───────date─┬─score─┐
│ 1 │ zhangsan │ 2020-10-11 │ 91 │ 1
└────┴──────────┴────────────┴───────┘
┌─id─┬─name─────┬───────date─┬─score─┐
│ 1 │ lisi │ 2020-10-10 │ 90 │ 2
│ 1 │ zhangsan │ 2020-10-10 │ 89 │ 3
│ 1 │ zhangsan │ 2020-10-10 │ 88 │ 4
└────┴──────────┴────────────┴───────┘
上放数据还未合并,所以强制合并后查看结果
optimize table rmTest final;
select * from rmTest;
┌─id─┬─name─────┬───────date─┬─score─┐
│ 1 │ lisi │ 2020-10-10 │ 90 │
│ 1 │ zhangsan │ 2020-10-10 │ 88 │
└────┴──────────┴────────────┴───────┘
┌─id─┬─name─────┬───────date─┬─score─┐
│ 1 │ zhangsan │ 2020-10-11 │ 91 │
└────┴──────────┴────────────┴───────┘
我在上方未合并的查询结果中添加了数据行编号1234代表数据行
a 数据删除只有在合并时才会进行,手动调用optimize语句.
b 1跟其他行数据是不同分区数据,所以并未执行合并,也就是说如果数据在不同分区,那么他们永远不会合并.
c 3和4合并了,根据的是order by(id,name),如果是根据primary key id 那么合并的就应该是2 3 4 而不是3 4了.所以,合并是根据order by排序键进行合并的
d 3 4合并后保留的是4的score 88,合并时留下的最后一条记录.另外可以制定保留数的规则,如果指定engine =ReplacingMergeTree(score)这样的话合并时会保留最大score的数据89而不是88了,
3 SummingMergeTree引擎
此引擎适合于要查询聚合结果而不关心明细数据的场景,比如查询的是每个人月的销量综合,而不是每一单的实际销量.
create table smTest(
id Int8,
name String,
code String,
date Date,
score Int8,
score2 Int8
)engine =SummingMergeTree
order by (id,name)
primary key id
partition by date;
insert into smTest values
(1,'zhangsan','a','2020-10-10',89,1),
(1,'zhangsan','b','2020-10-10',88,2),
(1,'lisi','c','2020-10-10',90,3),
(1,'zhangsan','d','2020-10-11',91,4);
select * from smTest;
┌─id─┬─name─────┬─code─┬───────date─┬─score─┬─score2─┐
│ 1 │ zhangsan │ d │ 2020-10-11 │ 91 │ 4 │
└────┴──────────┴──────┴────────────┴───────┴────────┘
┌─id─┬─name─────┬─code─┬───────date─┬─score─┬─score2─┐
│ 1 │ lisi │ c │ 2020-10-10 │ 90 │ 3 │
│ 1 │ zhangsan │ a │ 2020-10-10 │ 89 │ 1 │
│ 1 │ zhangsan │ b │ 2020-10-10 │ 88 │ 2 │
└────┴──────────┴──────┴────────────┴───────┴────────┘
optimize table smTest final;
select * from smTest;
┌─id─┬─name─────┬─code─┬───────date─┬─score─┬─score2─┐
│ 1 │ zhangsan │ d │ 2020-10-11 │ 91 │ 4 │
└────┴──────────┴──────┴────────────┴───────┴────────┘
┌─id─┬─name─────┬─code─┬───────date─┬─score─┬─score2─┐
│ 1 │ lisi │ c │ 2020-10-10 │ 90 │ 3 │
│ 1 │ zhangsan │ a │ 2020-10-10 │ -79 │ 3 │
└────┴──────────┴──────┴────────────┴───────┴────────┘
上方先不要管-79的问题,
a 可以看到数据是根据进行了聚合.而一些逻辑跟Replacing是一样的,只能同一个分区,是根据order by(id,name)进行聚合的
b 默认情况下是根据主键去聚合其他列的数据(数字型的列),但是如果有其他的列为字符串类型code,code将会保留第一次插入的值.
c 可以制定聚合哪些列,通过engine =SummingMergeTree(score)这样只会聚合score列,score2列就不会聚合了.
d -79的问题是故意演示出来的,因为score的类型是Int8 大小范围为[-128,127],88+89超出了范围,所以才会出现错误的值,如果将score类型改为UInt(范围为0-255)就会显示出正常的结果如下
┌─id─┬─name─────┬─code─┬───────date─┬─score─┬─score2─┐
│ 1 │ zhangsan │ d │ 2020-10-11 │ 91 │ 4 │
└────┴──────────┴──────┴────────────┴───────┴────────┘
┌─id─┬─name─────┬─code─┬───────date─┬─score─┬─score2─┐
│ 1 │ lisi │ c │ 2020-10-10 │ 90 │ 3 │
│ 1 │ zhangsan │ a │ 2020-10-10 │ 177 │ 1 │
└────┴──────────┴──────┴────────────┴───────┴────────┘
所以设计表时要考虑到聚合后的结果是否会超出当前类型的范围.
4 AggregatingMergeTree引擎
AggregatingMergeTree是SummingMergeTree的加强版,但是比较复杂,其插入数据必须要以 insert into select 的方式不能是insert into values的形式
所以先准备一个MergeTree表并且插入数据
CREATE TABLE mydatabase.mTest
(
`id` Int8,
`name` String,
`code` String,
`date` Date,
`score` Int16,
`score2` Int16
)
ENGINE = MergeTree
PARTITION BY date
ORDER BY (id, name);
insert into mTest values
(1,'zhangsan','a','2020-10-10',89,1),
(1,'zhangsan','b','2020-10-10',88,2),
(1,'lisi','c','2020-10-10',90,3),
(1,'zhangsan','d','2020-10-11',91,4);
AggregatingMergeTree表:
CREATE TABLE mydatabase.amTest
(
`id` Int8,
`name` String,
`code` AggregateFunction(uniq, String),
`date` Date,
`score` AggregateFunction(sum, Int16),
`score2` AggregateFunction(avg, Int16)
)
ENGINE = AggregatingMergeTree
PARTITION BY date
ORDER BY (id, name);
其中可以看到code字段,score字段,score2字段加了一个函数AggregateFunction(var,type) var需要一个聚合类型,type指聚合后的数据类型.如code就是聚合后返回不同的值的个数,score就是聚合后的总值,score2就是聚合后的平均值.
数据插入:
insert into amTest select id,name,uniqState(code),date,
sumState(score),avgState(score2)
from mTest group by id,name,date;
其中插入时候必须加*State,*指的是聚合类型,并且没有聚合函数的字段必须包含在group by里面.
查询的话是*Merge,并且也必须加group by,如果只是使用字段查询,会是无法显示的二进制形式,因为ClickHouse是通过二进制,保存中间结果状态的.
select * from mTest;
┌─id─┬─name─────┬─code─┬───────date─┬─score─┬─score2─┐
│ 1 │ zhangsan │ d │ 2020-10-11 │ 91 │ 4 │
└────┴──────────┴──────┴────────────┴───────┴────────┘
┌─id─┬─name─────┬─code─┬───────date─┬─score─┬─score2─┐
│ 1 │ lisi │ c │ 2020-10-10 │ 90 │ 3 │
│ 1 │ zhangsan │ a │ 2020-10-10 │ 89 │ 1 │
│ 1 │ zhangsan │ b │ 2020-10-10 │ 88 │ 2 │
└────┴──────────┴──────┴────────────┴───────┴────────┘
select id,name,uniqMerge(code),date,sumMerge(score),avgMerge(score2)
from amTest
group by id,name,date;
┌─id─┬─name─────┬─uniqMerge(code)─┬───────date─┬─sumMerge(score)─┬─avgMerge(score2)─┐
│ 1 │ zhangsan │ 1 │ 2020-10-11 │ 91 │ 4 │
│ 1 │ lisi │ 1 │ 2020-10-10 │ 90 │ 3 │
│ 1 │ zhangsan │ 2 │ 2020-10-10 │ 177 │ 1.5 │
└────┴──────────┴─────────────────┴────────────┴─────────────────┴──────────────────┘
这样子看用AggregatingMergeTree很麻烦,并且必须通过insert into tableName select的方式插入数据 ,这总不能每次查询前都要清空表再执行一次吧?
其实这种引擎是需要结合物化视图(MATERIALIZED VIEW)的:
create materialized view amView
engine = AggregatingMergeTree
order by (id,name)
partition by date as
select id,name,uniqState(code),date,sumState(score),avgState(score2)
from mTest group by id,name,date;
物化视图中的as select …指的是当前批次的插入的查询结果,而非全表的查询结果(如果想将创建视图前mTest中已有的数据也插入到amView中,在as select 之前加populate关键字)
这样子,每次mTest表中有数据插入,amView也就会执行插入.
-- 创建视图
create materialized view amView
engine = AggregatingMergeTree
order by (id,name)
partition by date
as
select id,name,uniqState(code) as code,date,sumState(score)as score,avgState(score2) as score2
from mTest group by id,name,date;
-- 清空mTest表并且插入数据;
truncate table amTest;
insert into mTest values
(1,'zhangsan','a','2020-10-10',89,1),
(1,'zhangsan','b','2020-10-10',88,2),
(1,'lisi','c','2020-10-10',90,3),
(1,'zhangsan','d','2020-10-11',91,4);
-- 查询数据
select id,name,uniqMerge(code),date,sumMerge(score),avgMerge(score2)
from amView group by id,name,date;
┌─id─┬─name─────┬─uniqMerge(code)─┬───────date─┬─sumMerge(score)─┬─avgMerge(score2)─┐
│ 1 │ zhangsan │ 1 │ 2020-10-11 │ 91 │ 4 │
│ 1 │ lisi │ 1 │ 2020-10-10 │ 90 │ 3 │
│ 1 │ zhangsan │ 2 │ 2020-10-10 │ 177 │ 1.5 │
└────┴──────────┴─────────────────┴────────────┴─────────────────┴──────────────────┘
这样结合物化视图后,我们可以往MergeTree表中写入明细数据,但是才能够AggregatingMergeTree物化视图查询聚合结果.
5 CollapsingMergeTree引擎
这引擎基本不会用,但是它是VersiondeCollapsingMergeTree的基础,所以也要说一下.
这种引擎的适应场景在于有些时候需要删除数据或者更新数据(Alter删除数据代价太大),
create table cmTest(
id Int8,
name String,
date Date,
score Int16,
flag Int8
)engine = CollapsingMergeTree(flag )
order by(id,name)
partition by date
其中最后一个字段flag Int8是规定写法,字段名随意,但必须为Int8类型,并且必须要在CollapsingMergeTree(flag)括号中.并且该字段只能是1或者-1,如果其他数值插入不会报错,但是无法折叠合并.正常折叠也是在文件合并的时候才会删除数据.
insert into cmTest values(1,'zhangsan','2020-10-10',88,1),(1,'zhangsan','2020-10-10',89,-1);
select * from cmTest;
┌─id─┬─name─────┬───────date─┬─score─┬─flag─┐
│ 1 │ zhangsan │ 2020-10-10 │ 88 │ 1 │
│ 1 │ zhangsan │ 2020-10-10 │ 89 │ -1 │
└────┴──────────┴────────────┴───────┴──────┘
optimize table cmTest final;
select * from cmTest;
数据被删除了...
此引擎是根据排序键与flag字段去删除数据,主键(1,‘zhangsan’)相同,flag相反就会折叠掉(删除).但是这一种情况必须要第一次的flag为1,第二次的为-1才会折叠掉,如果第一个为-1第二个为1将无法折叠.
还有一些其他情况,但是此引擎基本不用就不多说了.
6 VersionedCollapsingMergeTree引擎
此引擎是CollapingMergeTree的升级版,除了一个Int8类型的flag字段还需要一个Int8型的版本字段:
应用场景,统计在线玩家:比如游戏登陆时候要把正在登陆的玩家信息放到表中,代表已经登陆,但是下线的时候再插入一条数据,使其折叠,此时合并文件后(或者手动调用optimize语句)数据消失,代表玩家已经下线.
create table vcmTest(
id Int8,
name String,
date Date,
score Int16,
flag Int8,
version Int8
)engine = VersionedCollapsingMergeTree(flag,version)
order by(id,name)
partition by date;
在CollapingMergeTree中需要根据排序键与flag去折叠数据,VersionedCollapsingMergeTree引擎,不过是要主键相同,还必须要version也要相同,但是flag字段无序也能折叠.
insert into vcmTest values
(1,'zhangsan','2020-10-10',88,-1,1),
(1,'zhangsan','2020-10-10',89,-1,1),
(1,'zhangsan','2020-10-10',87,1,1),
(1,'zhangsan','2020-10-10',87,1,2);
select * from vcmTest;
┌─id─┬─name─────┬───────date─┬─score─┬─flag─┬─version─┐
│ 1 │ zhangsan │ 2020-10-10 │ 88 │ -1 │ 1 │
│ 1 │ zhangsan │ 2020-10-10 │ 89 │ -1 │ 1 │
│ 1 │ zhangsan │ 2020-10-10 │ 87 │ 1 │ 1 │
│ 1 │ zhangsan │ 2020-10-10 │ 87 │ 1 │ 2 │
└────┴──────────┴────────────┴───────┴──────┴─────────┘
optimize table vcmTest final;
select * from vcmTest;
┌─id─┬─name─────┬───────date─┬─score─┬─flag─┬─version─┐
│ 1 │ zhangsan │ 2020-10-10 │ 87 │ 1 │ 2 │
└────┴──────────┴────────────┴───────┴──────┴─────────┘
┌─id─┬─name─────┬───────date─┬─score─┬─flag─┬─version─┐
│ 1 │ zhangsan │ 2020-10-10 │ 88 │ -1 │ 1 │
└────┴──────────┴────────────┴───────┴──────┴─────────┘
最后
以上就是老实小甜瓜最近收集整理的关于ClickHouse MergeTree引擎家族的全部内容,更多相关ClickHouse内容请搜索靠谱客的其他文章。





![CREATE TABLE 语句后的 ON [PRIMARY] 起什么作用CREATE TABLE 语句后的 ON [PRIMARY] 起什么作用](https://www.shuijiaxian.com/files_image/reation/bcimg24.png)


发表评论 取消回复