文章目录
- 概述
- 适用场景
- 库引擎(部分)
- 1、Atomic
- 2、Lazy
- 3、Mysql、SQLite、PostergreSQL等一系列
- 数据类型(部分)
- 表引擎-合并树系列
- ReplacingMergeTree
- SummingMergeTree
- 分区
- clickhouse底层的合并操作Merge
- 排序键
- 主键
- 数据修改删除SQL语法
- 数据副本
- 分布式表引擎
- 读写流程(概述)
- 分布式表写入流程
- 读流程
- 读相关的数据一致性问题
- SQL优化方面的使用建议
- BI系统中数据的增量更新(replace into)
概述
clickhouse官方文档 https://clickhouse.com/docs/zh/
clickhouse是OLAP的列式数据库,底层是C++编写的。
相比于OLTP在线事务的处理,clickhouse更关注于海量数据的计算分析,关注的是数据吞吐、查询速度、计算性能等指标,对于数据频繁变更不太擅长,所以clickhouse通常用来构建后端的离线和实时数仓。
适用场景
1、绝大多数都是读请求,对数据的修改比较少或者几乎没有
2、数据量很大,既包括数据的行数,也包括数据的列数(宽表)
3、数据通常是大的批次进行更新而不是单行更新
4、对事务的要求不是必须的,通常只要求数据最终一致性
5、clickhouse对内存以及cpu的要求特别高
库引擎(部分)
1、Atomic
clickhouse默认的库引擎,它支持非阻塞的DROP TABLE和RENAME TABLE查询和原子的EXCHANGE TABLES t1 AND t2查询。
2、Lazy
类似于日志的功能,在最后一次访问之后,只在RAM中保存expiration_time_in_seconds秒。只能用于*Log表。
建库语句:
CREATE DATABASE testlazy ENGINE = Lazy(expiration_time_in_seconds);
3、Mysql、SQLite、PostergreSQL等一系列
拿Mysql举例,相当于通过clickhouse来连接Mysql的是数据库,可以执行insert、delete等sql语句,但不能执行create table、alter、rename等sql语句。这些库引擎,在clickhouse中不存储数据,只是将请求转发给了Mysql。
建库语句:
CREATE DATABASE test_database
ENGINE = PostgreSQL(‘host:port’, ‘database’, ‘user’, ‘password’[, use_table_cache]);
数据类型(部分)
注意大小写(ck严格要求大小写)
1、整型
Int8 Int16 Int32 Int64
2、无符号整型
UInt8 UInt16 UInt32 UInt64
3、浮点型
Float32 Float64
4、Decimal类型
Decimal32(s) Decimal64(s) Decimal128(s)
5、字符型
String
6、时间类型
Date 2022-03-01
Datetime 2022-03-01 10:10:10
Datetime64 2022-03-01 10:10:10.230
7、可为空类型
官方:总是对性能产生负面影响
Nullable
Create table test(x Nullable(Int8)) engine =
8、UUID类型
自动生成无序的随机数, select generateUUIDv4()
表引擎-合并树系列

MergeTree所有系列的表引擎前都可加前缀 Replicated 是支持数据副本的意思
ReplacingMergeTree

SummingMergeTree

分区
[PARTITION BY expr]
查询本地表的分区SQL:select partition from system.parts where table = ’ ';
1、在服务器上,每张表里的数据分区样式,下图是例子t_stock表

第一个_1代表数据块最小的编号,第二个_1代表数据块最大的编号,_0代表合并的次数
2、再看看每个数据块里的数据:
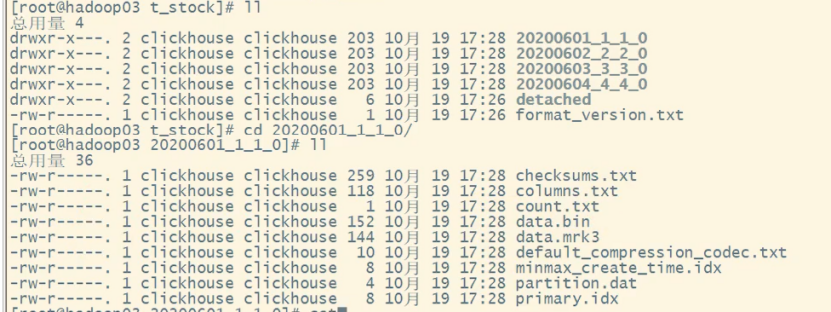
data.bin 里存着压缩后的数据
columns.txt是列信息
3、服务器上的查询结果:

clickhouse底层的合并操作Merge
数据从内存写入硬盘的操作称为合并操作,
合并方式有两种:
方式一:clickhouse后台会不定时的自动执行合并操作(3-5分钟?)
方式二:手动干预合并 sql:optimize table tableName final;
1、看看新增数据后,没有合并前的效果

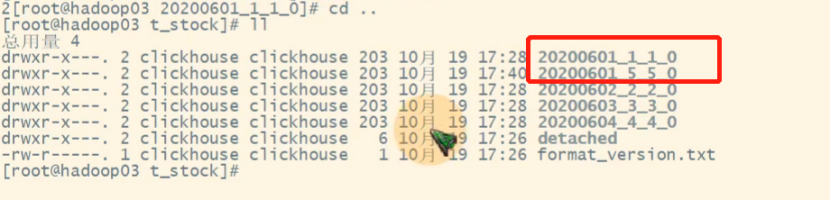
2、手动干预合并后的效果
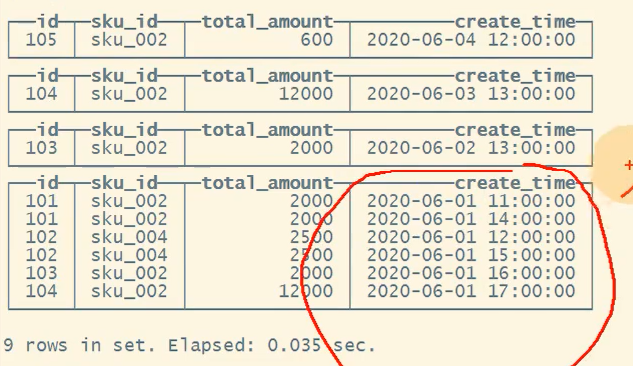
3、合并前和合并后的数据块截图
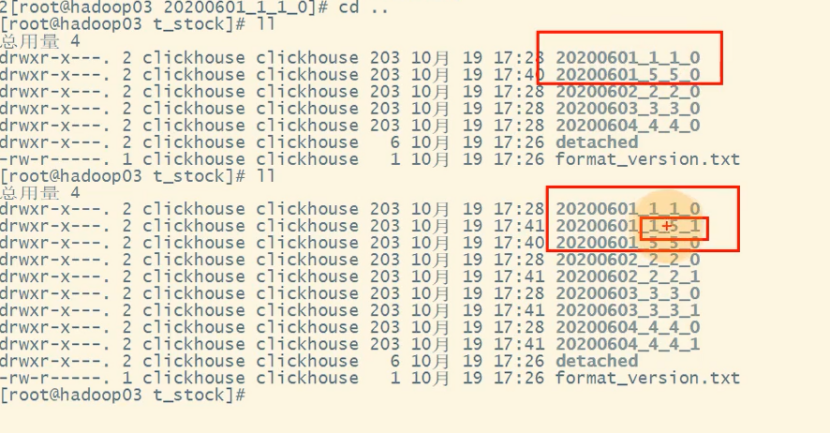 合并后不会删除掉之前的数据块,ck后期会有一个大合并,这时才会删掉废弃的数据块
合并后不会删除掉之前的数据块,ck后期会有一个大合并,这时才会删掉废弃的数据块
排序键
ORDER BY exper
order by可以设置多个字段列

主键
[PRIMARY KEY expr]

数据修改删除SQL语法
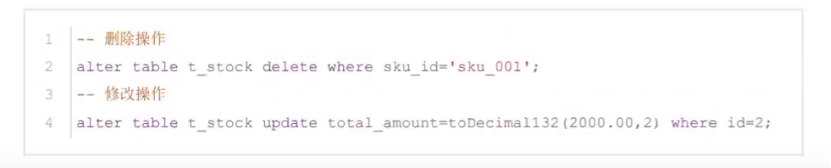 修改和删除操作,会新产生一个临时分区,原始的数据会打一个删除的标记,频繁的修改和删除会产生大量的临时分区,会进行大量的合并,服务器压力就变大了
修改和删除操作,会新产生一个临时分区,原始的数据会打一个删除的标记,频繁的修改和删除会产生大量的临时分区,会进行大量的合并,服务器压力就变大了
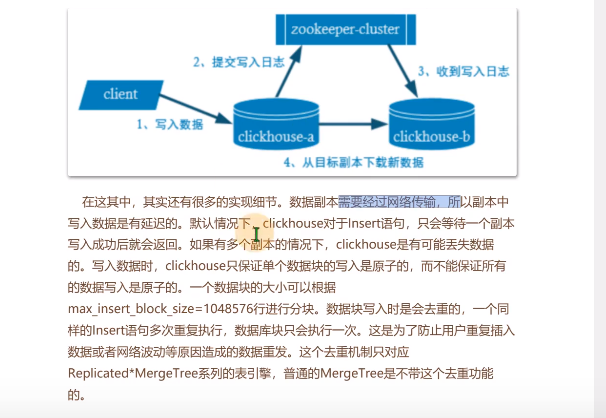
数据副本
clickhouse副本和副本之间没有主从关系
分布式表引擎
可以通过 [create table ‘tableName’ on cluster logs] 来进行,on cluster logs表示在logs这个集群上执行
读写流程(概述)
分布式表写入流程
1、设置同步or异步的配置
insert_sync = ture时表示同步写入,配合insert_timeout参数使用,i
Insert_sync = false 时表示异步写入
同步写入是指数据直接写入实际的表中,而异步写入是指数据首先被写入本地文件系统,然后发送到远端节点
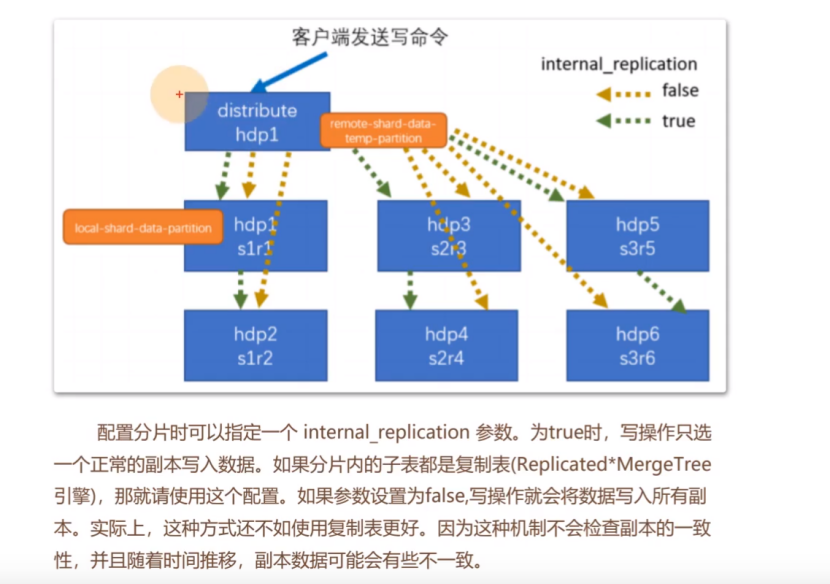
2、写入流程
2.1、
Internal_reliaction参数,false时,所有副本,都由分布式表来完成写入操作
Internal_reliaction参数,true时,只有每个分片中的一个副本由分布式表来完成写入操作。
2.2、true时,使用到了数据副本的机制,当分片1中r1给r2同步时,r2挂掉了,在r2恢复后,会有一个重试的操作。
2.3、写入是有一个数据权重分配策略,可以配置的
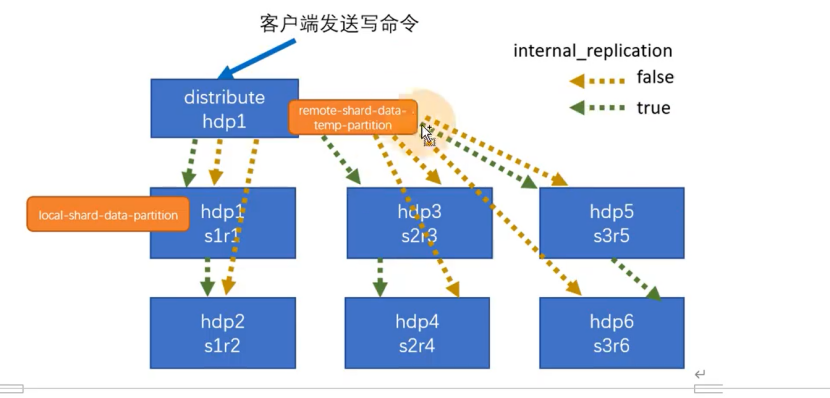
读流程
每个副本上都有一个errors_count的一个错误记录,当读取命令打在分布式表上时,分布式表会优先选择errors_count小的副本进行读取
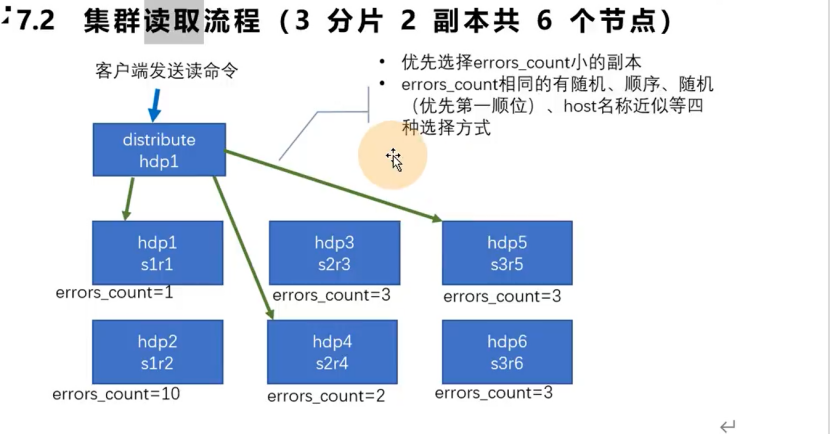
读相关的数据一致性问题
https://cloud.tencent.com/developer/article/1748216
SQL优化方面的使用建议
clickhouse支持explan进行查询执行计划等操作,详情见开发文档https://clickhouse.com/docs/zh/sql-reference/statements/explain/
sql上的注意事项:https://www.jianshu.com/p/e5050f046699
BI系统中数据的增量更新(replace into)
Asteria增量更新如何实现?
1、查询ck本地表中的分区sql
select partition from system.parts where table = ‘’;
2、Ck表的分区是如下两种格式(clickhouse_version_value是插入ck表时这批数据的版本号,时间戳)
2.1、设置里以date类型的字段为分区
PARTITION BY (clickhouse_version_value, toYYYYMMDD(toDate(substring(‘field_value’, 1, 10))))
对应的ck里的分区样式 (‘20220324081602’,20220314)
2.2、默认无设置数据集分区
PARTITION BY (clickhouse_version_value, toYYYYMM(clickhouse_version_value))
3、数据replace into流程举例
3.1、增量更新第一次更新,表中的数据:
| Day | orderId | price | asteria_order | clickhouse_version_value |
|---|---|---|---|---|
| 20220324 | 订单号一 | 20元 | 1 | 20220324101010 |
| 20220324 | 订单号二 | 15元 | 2 | 20220324101010 |
| 20220325 | 订单号三 | 19元 | 3 | 20220324101010 |
3.2、增量更新,第二次运行sql查询出来的数据:
| Day | orderId | price | asteria_order | clickhouse_version_value |
|---|---|---|---|---|
| 20220325 | 订单号三 | 22元 | 4 | 20220324202020 |
| 20220325 | 订单号四 | 31元 | 5 | 20220324202020 |
| 20220326 | 订单号五 | 32元 | 6 | 20220324202020 |
3.3、查询出每个本地表中的旧分区信息
(20220324101010, 20220324)
(20220324101010, 20220325)
3.4、将第二次sql查询出的数据插入ck表中
3.5、查询clickhouse_version_value = ‘20220324202020’ 的字段day的数据
20220325、20220326
3.6、对3.2中旧分区的右半部分进行匹配,删除掉新增的数据中匹配成功的day数据,即:20220305
Alter table tableNamecluster drop partiton (20220324101010, 20220325);
3.7、结束,最后表中的数据如下图
| Day | orderId | price | asteria_order | clickhouse_version_value |
|---|---|---|---|---|
| 20220324 | 订单号一 | 20元 | 1 | 20220324101010 |
| 20220324 | 订单号二 | 15元 | 2 | 20220324101010 |
| 20220325 | 订单号三 | 22元 | 4 | 20220324202020 |
| 20220325 | 订单号四 | 31元 | 5 | 20220324202020 |
| 20220326 | 订单号五 | 32元 | 6 | 20220324202020 |
最后
以上就是大意皮卡丘最近收集整理的关于clickhouse初学以及利用ck实现BI系统的增量更新概述适用场景库引擎(部分)数据类型(部分)表引擎-合并树系列分区clickhouse底层的合并操作Merge排序键主键数据修改删除SQL语法数据副本分布式表引擎读写流程(概述)读相关的数据一致性问题SQL优化方面的使用建议BI系统中数据的增量更新(replace into)的全部内容,更多相关clickhouse初学以及利用ck实现BI系统的增量更新概述适用场景库引擎(部分)数据类型(部分)表引擎-合并树系列分区clickhouse底层的合并操作Merge排序键主键数据修改删除SQL语法数据副本分布式表引擎读写流程(概述)读相关的数据一致性问题SQL优化方面的使用建议BI系统中数据的增量更新(replace内容请搜索靠谱客的其他文章。








发表评论 取消回复