核心知识与集群介绍(基于v21.11版本)
目录
1. 介绍
2. 优缺点
3. 表引擎
3.1 Log
3.2 Engine Families MergeTree
3.3 Integration Engines
3.4 Special Engines
4. 数据类型
5. SQL
6. 集群介绍
1. 介绍
ClickHouse是一款由俄罗斯 Yandex 公司开发的用于联机分析(OLAP)的列式数据库管理系统(DBMS)。
常见的 OLAP 引擎: Hive、Spark SQL、Presto、Kylin、Impala、Druid、Clickhouse、Greeplum等。
2. 优缺点
特性:
- 真正的列式数据库管理系统
- 数据压缩
- 数据存储在磁盘.数据存储在磁盘可以降低成本,clickhouse 即使在普通磁盘上,也可以快速的查询出结果。
- 多核心并行处理
- 多服务器分布式处理.分布式表,可以利用多个服务器,并行执行查询。
- 支持 SQL
- 向量引擎
- 索引
- 适合在线查询
- 支持近似计算
- 自适应 join
- 支持数据副本机制.可以设置数据存储的备份,提高可用性。
- 角色控制
缺点:
- 没有完整的事务支持
- 不能高频、低延迟的修改或删除数据
- 不适合单行点查询
3. 表引擎
clickhouse 有多种表引擎,适用于不同的场景。建表语句如下:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [NULL|NOT NULL] [DEFAULT|MATERIALIZED|ALIAS expr1] [compression_codec] [TTL expr1],
name2 [type2] [NULL|NOT NULL] [DEFAULT|MATERIALIZED|ALIAS expr2] [compression_codec] [TTL expr2],
...
) ENGINE = engine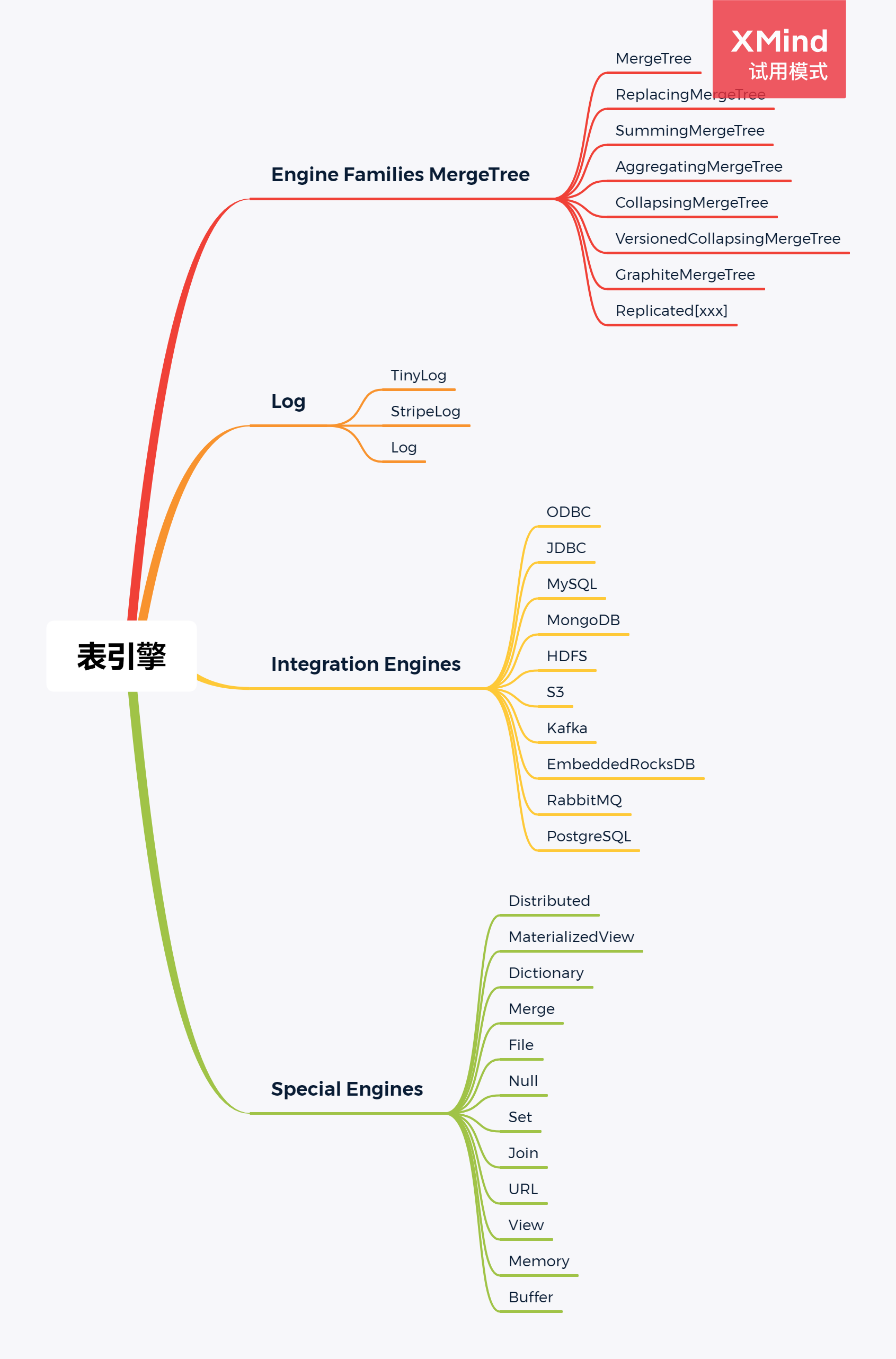
3.1 Log
- 插入数据会锁表
- 不支持索引,也就是说范围查询效率不高
- 适用于临时数据,一次性写入的表,测试表
3.1.1 TinyLog
- 最简单的引擎
- 适合一次写入,只读的场景
- 数据量在 100w 以内
- 没有并发控制,同时读写会报错,并发写入,数据不可用
3.1.2 StripeLog
- 可以并发读,写入会阻塞读操作
3.1.3 Log
- 可以并发读,性能比 StripeLog 要好一些
- 因为使用 __marks.mrk 文件记录每个数据块的偏移,写入数据出现问题,表直接报废
3.2 Engine Families MergeTree
- 使用最多的表引擎
- 支持索引、分区
3.2.1 MergeTree
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1], -- MATERIALIZED 从别的列物化出来这一列, 用于减少查询时候的计算量
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2], -- ALIAS 不实际存储这一列, 在查询的时候执行
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1, -- 二级索引
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2,
...
PROJECTION projection_name_1 (SELECT <COLUMN LIST EXPR> [GROUP BY] [ORDER BY]), -- 实验性功能, part 级别的物化视图, 在查询的时候会自动使用
PROJECTION projection_name_2 (SELECT <COLUMN LIST EXPR> [GROUP BY] [ORDER BY])
) ENGINE = MergeTree()
ORDER BY expr -- 排序字段
[PARTITION BY expr] -- 分区
[PRIMARY KEY expr] -- 主键, 默认和 order by 一致, 一般情况下不设置, 跟 order by 保持一致
[SAMPLE BY expr] -- 抽样, 必须是主键或者排序字段包含的字段, 必须是 UInt 类型字段
[TTL expr -- 数据过期时间
[DELETE|TO DISK 'xxx'|TO VOLUME 'xxx' [, ...] ]
[WHERE conditions]
[GROUP BY key_expr [SET v1 = aggr_func(v1) [, v2 = aggr_func(v2) ...]] ] ]
[SETTINGS name=value, ...]使用示例:
-- 示例1
CREATE TABLE test.label_number_local
(
`tag_code` String,
`user_id` UInt64 COMMENT '用户 id',
`value` Float64 COMMENT '标签值'
)
ENGINE = MergeTree
PARTITION BY tag_code
ORDER BY tag_code
-- 示例2, TTL
CREATE TABLE test.dw_domestic_hotel_monitor_crm_realtime
(
`dt` String COMMENT '时间分区',
`type` String COMMENT '类型',
`hour` String COMMENT '小时',
`hotel_seq` String COMMENT 'hotel_seq',
`device_id` String COMMENT '设备id',
`platform` String COMMENT '客户端',
......
)
ENGINE = MergeTree()
PARTITION BY (dt,
type)
ORDER BY (dt,
hour,
type,
......)
-- 删除 dt+2day <= today(now()) and type!='order' 的数据, 即保留最近两天(包括当天)的数据
TTL parseDateTimeBestEffort(dt) + toIntervalDay(2) WHERE type != 'order'
-- 示例3, sample
CREATE TABLE test.clicks
(
`CounterID` UInt64,
`EventDate` DATE,
`UserID` UInt64
)
ENGINE = MergeTree()
ORDER BY (CounterID, intHash32(UserID))
SAMPLE BY intHash32(UserID)
-- 查询, 按 intHash32(UserID) 采样, 伪随机, 相同采样率每次查询结果一致
select * from test.clicks sample 0.23.2.2 ReplacingMergeTree
会自动删除具有相同 order by 字段值的重复数据。但是他只会在后台合并分区文件的时候删除,所以不可靠。适用于清除重复数据节省空间,但不保证没有重复数据。
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = ReplacingMergeTree([ver]) -- 带有版本号的列, 支持的数据类型 UInt*, Date, DateTime, DateTime64
[PARTITION BY expr]
[ORDER BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]3.2.3 SummingMergeTree
会自动合并具有相同 order by 字段值的重复数据,把其他数值类型的列加在一起。
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = SummingMergeTree([columns]) -- 数值类型的列, 且不在 order by 字段中, 默认值是所有不在 order by 字段的数值类型列
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]3.2.4 AggregatingMergeTree
会自动合并具有相同 order by 字段值的重复数据,把其他列聚合到一行。
列的类型,可以指定 AggregateFunction、SimpleAggregateFunction、其他类型,指定其他类型,使用第一次插入的值。
AggregateFunction 使用示例: AggregateFunction | ClickHouse Documentation
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = AggregatingMergeTree()
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[TTL expr]
[SETTINGS name=value, ...]使用示例:
CREATE MATERIALIZED VIEW test.basic
ENGINE = AggregatingMergeTree() PARTITION BY toYYYYMM(StartDate) ORDER BY (CounterID, StartDate)
AS SELECT
CounterID,
StartDate,
sumState(Sign) AS Visits,
uniqState(UserID) AS Users
FROM test.visits
GROUP BY CounterID, StartDate;
-- 查询
SELECT
StartDate,
sumMerge(Visits) AS Visits,
uniqMerge(Users) AS Users
FROM test.basic
GROUP BY StartDate
ORDER BY StartDate;3.2.5 CollapsingMergeTree
根据一个标识字段,合并 order by 相同的行。
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = CollapsingMergeTree(sign) -- 标识字段, 字段类型 Int8, 1 标识有效, -1 标识无效
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]使用示例:
-- 建表
CREATE TABLE test.UAct
(
UserID UInt64,
PageViews UInt8,
Duration UInt8,
Sign Int8
)
ENGINE = CollapsingMergeTree(Sign)
ORDER BY UserID
-- 插入数据
INSERT INTO test.UAct VALUES (4324182021466249494, 5, 146, 1)
INSERT INTO test.UAct VALUES (4324182021466249494, 5, 146, -1),(4324182021466249494, 6, 185, 1)
OPTIMIZE TABLE test.UAct -- 合并 part
-- 查询数据
SELECT * FROM test.UAct
-- 结果
4324182021466249494 6 185 13.2.6 VersionedCollapsingMergeTree
根据标识字段+version合并 order by 字段相同的行。
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = VersionedCollapsingMergeTree(sign, version)
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]使用示例:
CREATE TABLE test.UAct_VC
(
UserID UInt64,
PageViews UInt8,
Duration UInt8,
Sign Int8,
Version UInt8
)
ENGINE = VersionedCollapsingMergeTree(Sign, Version)
ORDER BY UserID
-- 插入数据
INSERT INTO test.UAct_VC VALUES
(4324182021466249494, 5, 146, 1, 1),
(4324182021466249494, 5, 146, -1, 1),
(4324182021466249494, 6, 185, 1, 2),
(4324182021466249494, 7, 185, 1, 3),
(4324182021466249494, 7, 185, -1, 4)
OPTIMIZE TABLE test.UAct_VC
-- 查询数据
select * from test.UAct_VC limit 10
-- 结果, 会把 version 相同的数据进行合并
4324182021466249494 6 185 1 2
4324182021466249494 7 185 1 3
4324182021466249494 7 185 -1 43.2.7 GraphiteMergeTree
用来保存 Graphite 数据。
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
Path String,
Time DateTime,
Value <Numeric_type>,
Version <Numeric_type>
...
) ENGINE = GraphiteMergeTree(config_section)
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]3.2.8 数据备份
上面的七个 MergeTree 引擎,都有对应带数据备份的引擎。
- ReplicatedMergeTree
- ReplicatedSummingMergeTree
- ReplicatedReplacingMergeTree
- ReplicatedAggregatingMergeTree
- ReplicatedCollapsingMergeTree
- ReplicatedVersionedCollapsingMergeTree
- ReplicatedGraphiteMergeTree
clickhouse 的数据备份是表级别的,一个集群中,可以既有带备份的表,也可以有不带备份的表。他的使用如下所示:
CREATE TABLE table_name [ON CLUSTER cluster]
(
x UInt32
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/default/table_name', '{replica}')
ORDER BY xshard 和 replica 是配置在 clickhouse 配置文件的变量,每个 ck 节点对这两个变量都有不同的值,也可以不用变量直接写值。
下面的 sql 演示了如何创建一个1分片2备份的表。
-- clickhouse3
create table test.s1r2
(
t String
) engine = ReplicatedMergeTree('/clickhouse/tables/test/s1r2', 'r1')
order by t
-- clickhouse4
create table test.s1r2
(
t String
) engine = ReplicatedMergeTree('/clickhouse/tables/test/s1r2', 'r2')
order by t下面的 sql 演示了如何创建一个3分片2备份的表。
-- clickhouse3
create table test.s3r2
(
t String
) engine = ReplicatedMergeTree('/clickhouse/tables/s1/test/s3r2', 'r1')
order by t
-- clickhouse4
create table test.s3r2
(
t String
) engine = ReplicatedMergeTree('/clickhouse/tables/s1/test/s3r2', 'r2')
order by t
-- clickhouse5
create table test.s3r2
(
t String
) engine = ReplicatedMergeTree('/clickhouse/tables/s2/test/s3r2', 'r1')
order by t
-- clickhouse6
create table test.s3r2
(
t String
) engine = ReplicatedMergeTree('/clickhouse/tables/s2/test/s3r2', 'r2')
order by t
-- clickhouse7
create table test.s3r2
(
t String
) engine = ReplicatedMergeTree('/clickhouse/tables/s3/test/s3r2', 'r1')
order by t
-- clickhouse 8
create table test.s3r2
(
t String
) engine = ReplicatedMergeTree('/clickhouse/tables/s3/test/s3r2', 'r2')
order by t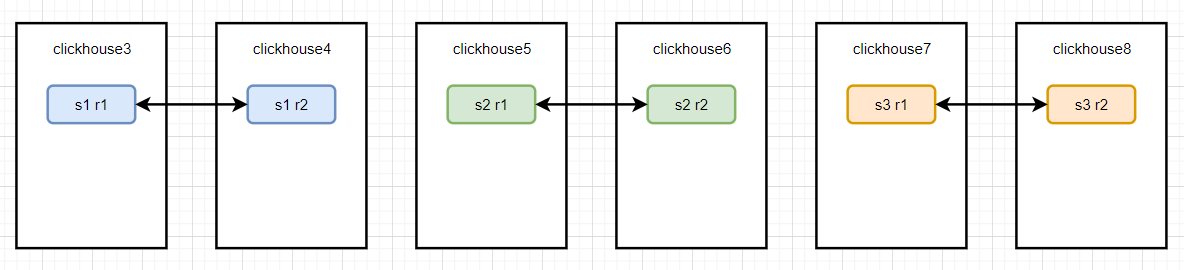
clickhouse 是多主异步复制。在多分片的时候,可以自己写逻辑来控制不同分片的数据,也可以通过分布式表来实现分片。
3.3 Integration Engines
- ODBC
- JDBC
- MySQL
- MongoDB
- HDFS
- S3
- Kafka
- EmbeddedRocksDB
- RabbitMQ
- PostgreSQL
详细看一下 kafka 引擎,其他的用的比较少。
kafka 引擎的表,可以从 kafka 拉取数据,使用示例如下:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = Kafka()
SETTINGS
kafka_broker_list = 'host:port',
kafka_topic_list = 'topic1,topic2,...',
kafka_group_name = 'group_name',
kafka_format = 'data_format'[,] -- https://clickhouse.com/docs/en/interfaces/formats/
[kafka_row_delimiter = 'delimiter_symbol',]
[kafka_schema = '',]
[kafka_num_consumers = N,]
[kafka_max_block_size = 0,] -- 每次从 kafka 拉取最大的数据大小
[kafka_skip_broken_messages = N,]
[kafka_commit_every_batch = 0,]
[kafka_thread_per_consumer = 0] -- 为每个消费者提供独立的线程-- kafka, 相当于 clickhouse 访问 kafka 的一个接口, 不存储数据
CREATE TABLE default.crm_realtime_kafka
(
`hour` String,
`log_time` String,
`log_date` String,
...
)
ENGINE = Kafka('l-qkafkapubn1.ops.cn2.qunar.com:9092,l-qkafkapubn2.ops.cn2.qunar.com:9092,l-qkafkapubn3.ops.cn2.qunar.com:9092,l-qkafkapubn4.ops.cn2.qunar.com:9092,l-qkafkapubn5.ops.cn2.qunar.com:9092,l-qkafkapubn6.ops.cn2.qunar.com:9092',
'custom_h_realtime_data_crm', -- kafka_topic_list
'ck_crm', -- kafka_group_name
'JSONEachRow') -- kafka_format
-- 存储数据的表
CREATE TABLE default.dw_domestic_hotel_monitor_realtime_flow
(
`hour` String,
`log_time` String,
`log_date` String,
...
)
ENGINE = MergeTree()
PARTITION BY (dt, type)
ORDER BY (dt, type, checkin_date, checkout_date)
-- 物化视图, 把 kafka 表的数据持久化到另一张表
CREATE MATERIALIZED VIEW crm_realtime_kafka_consumer TO dw_domestic_hotel_monitor_realtime_flow AS SELECT * from crm_realtime_kafka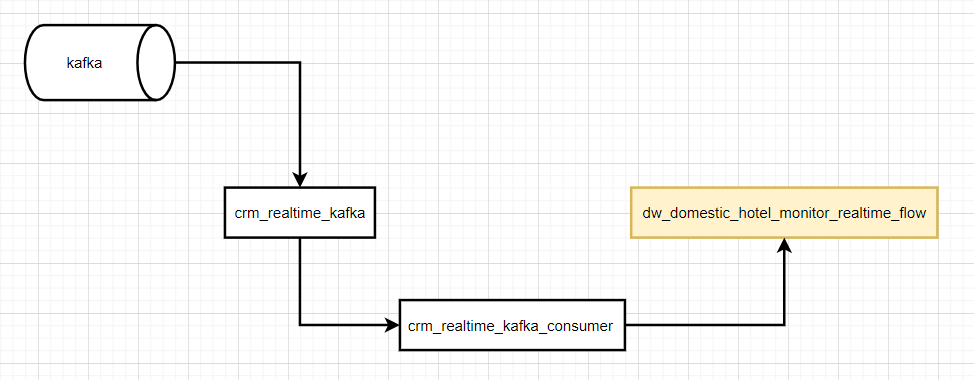
kafka 引擎的表,提供了5个虚拟列(select * 的时候查不出来,只有查询这个字段,才会显示出来),可以用来监控一些信息
- _topic 消费的 kafka topic
- _key 这条消息的 key
- _offset 这条消息的 offset
- _timestamp 这条消息写入 kafka 的时间
- _partition 消费的 kafka partition
3.4 Special Engines
3.4.1 Distributed
不存储数据,自动并行化查询,用来建分布式表。
-- 本地表, 存储数据
CREATE TABLE default.dw_domestic_hotel_monitor_realtime_flow_local on cluster s4r4
(
`hour` String,
`log_time` String,
`log_date` String,
...
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard_s4r4}/default/dw_domestic_hotel_monitor_realtime_flow_local', '{replica_s4r4}')
PARTITION BY (dt, type)
ORDER BY (dt, type, checkin_date, checkout_date)
-- 分布式表, 不存储数据, 查询的时候查这个表, 会自动把查询语句分发到每台机器, 并行化执行
CREATE TABLE default.dw_domestic_hotel_monitor_realtime_flow on cluster s4r4
AS default.dw_domestic_hotel_monitor_realtime_flow_local
ENGINE = Distributed(
's4r4', -- 集群名
'default', -- 库名
'dw_domestic_hotel_monitor_realtime_flow_local', -- 表名
sipHash64(dt)) -- 分 shard 的字段3.4.2 MaterializedView
物化视图,相当于提前计算好数据存起来,类似于插入触发器,在往源表插入数据的时候触发,修改、删除则不会触发,如果有 group by,也只是会对当前插入的这一批数据 group by。
CREATE MATERIALIZED VIEW [IF NOT EXISTS] [db.]table_name [ON CLUSTER] [TO[db.]name] [ENGINE = engine] [POPULATE] AS SELECT ...3.4.3 Merge
本身不存储数据,会把查询路由到其他表,并行执行查询,只支持读。
CREATE TABLE ... Engine=Merge(db_name, tables_regexp)
-- 使用示例
CREATE TABLE WatchLog_old(date Date, UserId Int64, EventType String, Cnt UInt64)
ENGINE=MergeTree(date, (UserId, EventType), 8192);
INSERT INTO WatchLog_old VALUES ('2018-01-01', 1, 'hit', 3);
CREATE TABLE WatchLog_new(date Date, UserId Int64, EventType String, Cnt UInt64)
ENGINE=MergeTree PARTITION BY date ORDER BY (UserId, EventType);
INSERT INTO WatchLog_new VALUES ('2018-01-02', 2, 'hit', 3);
CREATE TABLE WatchLog as WatchLog_old ENGINE=Merge(currentDatabase(), '^WatchLog');
SELECT *, _table FROM WatchLog;
-- 结果
2018-01-01 1 hit 3 WatchLog_old
2018-01-02 2 hit 3 WatchLog_new3.4.4 Null
不存储数据,可以在 NULL 引擎的表上建物化视图,这样不存储原始数据,直接存储到物化视图。
CREATE TABLE test(key String, value UInt32) ENGINE = NULL;3.4.5 Join
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
) ENGINE = Join(join_strictness, join_type, k1[, k2, ...])示例:
CREATE TABLE id_val(`id` UInt32, `val` UInt32) ENGINE = TinyLog;
INSERT INTO id_val VALUES (1,11)(2,12)(3,13);
CREATE TABLE id_val_join(`id` UInt32, `val` UInt8) ENGINE = Join(ANY, LEFT, id);
INSERT INTO id_val_join VALUES (1,21)(1,22)(3,23);
SELECT * FROM id_val ANY LEFT JOIN id_val_join USING (id);3.4.6 View
普通视图,不存储数据,类似于 hive 的视图。
CREATE VIEW view AS SELECT ...3.4.7 Memory
数据只存储在内存中,因为数据是无压缩的存储在内存,查询扫描速度最高可以打到 10G/s,重启数据会丢。
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
)
ENGINE = Memory3.4.9 其他
- Dictionary
- File
- Set
- URL
- Buffer
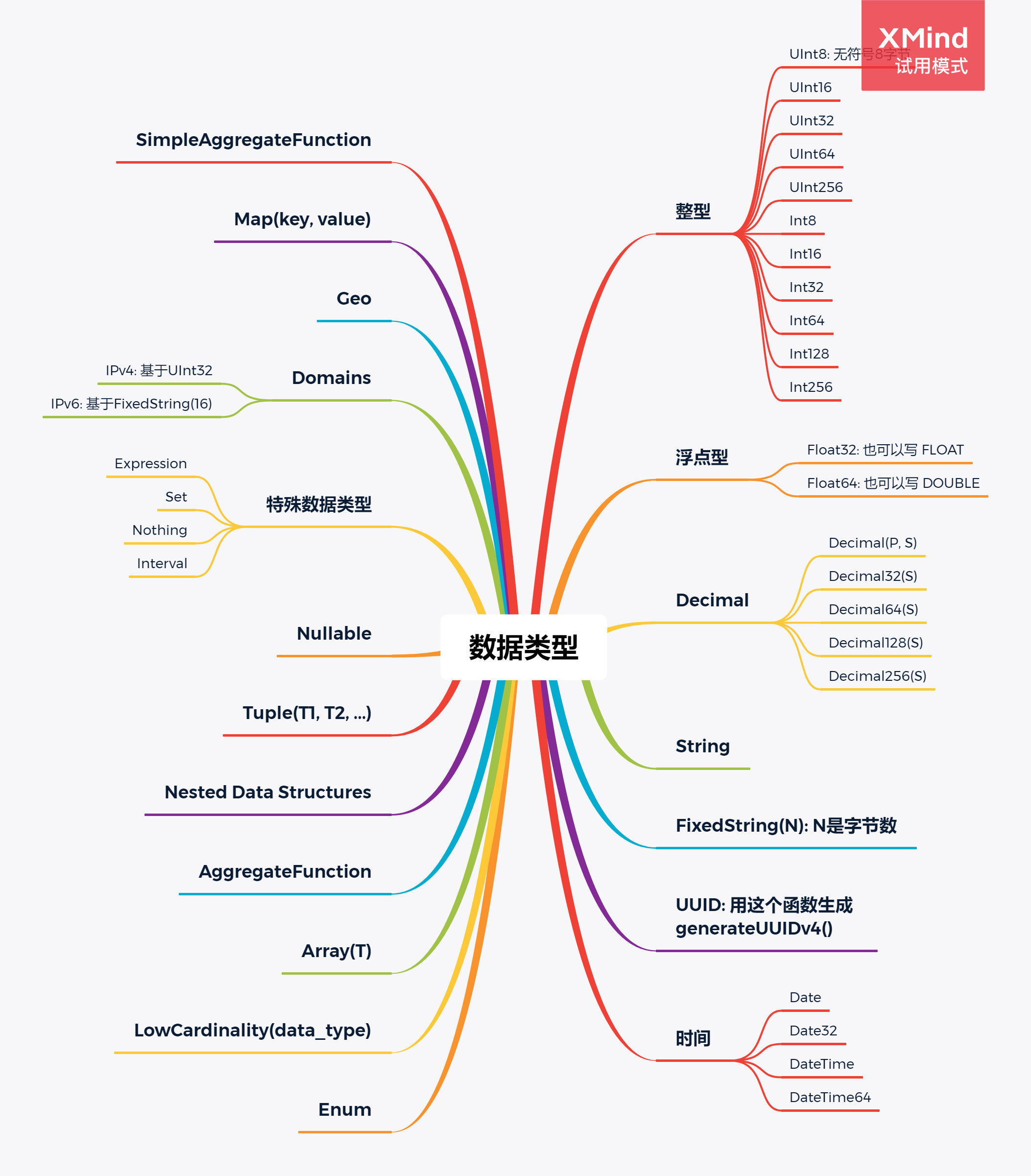
4. 数据类型
5. SQL
-- 创建表
CREATE TABLE IF NOT EXISTS test.student
(
id UInt32,
name String, -- 姓名
age UInt32, -- 年龄
scores Array(UInt32), -- 成绩
class String -- 班级
) ENGINE = MergeTree()
ORDER BY id;
-- 插入数据
INSERT INTO test.student VALUES
(1, '张三', 16, array(100, 140, 90), '一班'),
(2, '李四', 16, array(90, 140, 90), '一班'),
(3, '王五', 17, array(100, 100, 90), '一班'),
(4, '小明', 16, array(130, 140, 120), '二班'),
(5, '小红', 15, array(130, 120, 120), '二班'),
(6, '小军', 15, array(60, 120, 120), '三班'),
(7, '小兰', 17, array(80, 120, 100), '三班'),
(8, '小光', 16, array(140, 120, 120), '三班');
-- 1. 明细查询
select id, name, age, scores, class from test.student;
-- 2. 学生的最大年龄
select max(age) as max_age from test.student;
-- 3. 每个班的学生人数
select class, count(*) as student_num from test.student group by class;
-- 4. 按总分从高到低排序
select name, arraySum(scores) as total_score from test.student order by total_score desc;
-- 5. 每个班按成绩从高到低排序
select
class,
name,
arraySum(scores) as total_score,
row_number() over(partition by class order by total_score desc) rank
from test.student
order by class, rank;
select
class, name_arr as name, total_score_arr as total_score, rank
from
(select
class,
groupArray(name) as name_arr,
groupArray(total_score) as total_score_arr,
arrayEnumerateDense(total_score_arr) rank
from (select class, name, arraySum(scores) as total_score from test.student order by total_score desc) tmp
group by class) tmp2
array join name_arr, total_score_arr, rank
order by class, rank;
-- join...6. 集群介绍
clickhouse 集群通过配置文件来配置,修改配置后不需要重启,会自动加载。
<!-- 集群配置 -->
<remote_servers_default>
<s4r4>
<shard>
<!-- 写数据请求转发的权重, 默认是 1 -->
<!-- <weight>1</weight> -->
<!-- 默认值 false, 如果底层不是复制表, 设置为 false, 插入分布式表的时候, 会把所有副本都写一份,
如果是复制表, 设置为 true, 插入分布式表仅写到一个副本, 由复制表来完成数据同步备份 -->
<internal_replication>true</internal_replication>
<replica>
<host>l-clickhouse3.h.cn6</host>
<port>9000</port>
<user>default</user>
<password>****</password>
</replica>
<replica>
<host>l-clickhouse7.h.cn6</host>
<port>9000</port>
<user>default</user>
<password>****</password>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>l-clickhouse4.h.cn6</host>
<port>9000</port>
<user>default</user>
<password>****</password>
</replica>
<replica>
<host>l-clickhouse8.h.cn6</host>
<port>9000</port>
<user>default</user>
<password>****</password>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>l-clickhouse5.h.cn6</host>
<port>9000</port>
<user>default</user>
<password>****</password>
</replica>
<replica>
<host>l-clickhouse9.h.cn6</host>
<port>9000</port>
<user>default</user>
<password>****</password>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>l-clickhouse6.h.cn6</host>
<port>9000</port>
<user>default</user>
<password>****</password>
</replica>
<replica>
<host>l-clickhouse10.h.cn6</host>
<port>9000</port>
<user>default</user>
<password>****</password>
</replica>
</shard>
</s4r4>
</remote_servers_default>在 system.clusters 表中可以看到目前已有的集群。

集群只是逻辑上的集群,同一个 clickhouse 实例,可以属于不同的多个集群。
最后
以上就是拉长网络最近收集整理的关于clickhouse 核心知识与集群介绍1. 介绍2. 优缺点3. 表引擎4. 数据类型5. SQL6. 集群介绍的全部内容,更多相关clickhouse内容请搜索靠谱客的其他文章。








发表评论 取消回复