文章目录
- 测试环境
- 配置方法
- 底层实现
- 零拷贝
- 总结
导读:看官方文档说clickhouse现在支持HDFS和AWS S3作为数据存储的仓库,如果是这样的话,那就意味着基于clickhouse也可以实现"存储与计算分离"的架构设计了,那自然对于整个系统的可靠性和可扩展性是有极大帮助的。本文尝试着对这一新功能一探究竟~~
测试环境
- clickhouse版本:21.8, 我们的环境之前有一个20.6的版本,尝试后发现并不支持,于是装了一个较新的版本。
- 云存储:HDFS。我们自己的很多产品都是基于Hadoop生态来开发的,因此选择了比较常用的HDFS作为本次测试使用的云存储方案。
配置方法
按照官方文档说明,在config.xml文件中添加如下配置:
<storage_configuration>
<disks>
<hdfs>
<type>hdfs</type>
<endpoint>hdfs://hdfs1:9000/clickhouse/</endpoint>
</hdfs>
</disks>
<policies>
<hdfs>
<volumes>
<main>
<disk>hdfs</disk>
</main>
</volumes>
</hdfs>
</policies>
</storage_configuration>
<merge_tree>
<min_bytes_for_wide_part>0</min_bytes_for_wide_part>
</merge_tree>
注:很有可能你的环境已经有了storage_configuration的配置,只需要在disks和policies标签下添加hdfs的部分即可。
- endpoint参数:HDFS的一个存储路径,需提前创建好。
配置完成后,重启clickhouse-server服务,验证是否生效:
-
通过system.storage_policies表查看存储策略是否OK
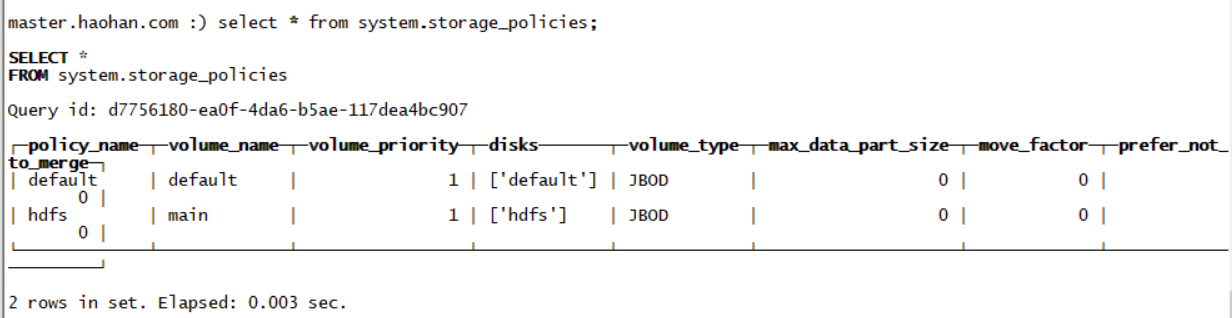
-
通过settings参数指定storage_policy为我们配置好的hdfs,建表语句如下:
create table test_data engine=MergeTree order by id settings storage_policy='hdfs' as with (select ['A','a','A','A','B','B','B','B','B','A','59','90','80','85','90','929','80','72','90','123']) AS dict select dict[number%10 + 1] as id,dict[number + 11] as val from system.numbers limit 10;
库表创建成功,查看库表数据也是OK的。
底层实现
现在确实数据OK了,我也在之前HDFS指定的目录下看到了如下的数据文件:

但这些看着像是base64编码的文件名是什么东西呢?这个的底层索引是如何实现的呢?一开始根本看不懂,于是我首先查看了system.partition分区表,看看这张新建的表分区目录在哪儿,发现索引目录竟然都在本地,难道不应该在HDFS上吗?下图是这个分区目录下的文件,貌似和本地存储的文件列表没什么区别。

但是我查看了其中一个文件columns.txt,发现里面的内容并不是存储的字段信息:
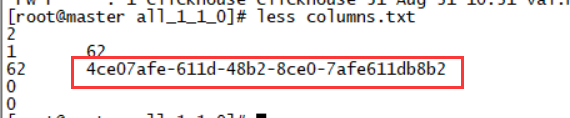
这个串看着这么眼熟,后来一比对,发现和HDFS目录下的其中一个文件名字相同,原来是给你留下的一个记号,于是我查看了HDFS上这个文件的内容,果然这才是“真身”啊:

其他的文件我在比对后同样发现,均和本地目录下的索引文件是一一对应的,也就是说本地索引文件只是个路标,真正的索引和数据还是存储在HDFS上的。
零拷贝
在多个副本的情况下,如果是本地存储,那么clickhouse会在后台进行副本之间数据的同步,但是如果使用这种云存储呢,这种数据同步是不是有点儿多此一举了呢?按照官方文档的说法,在上述这种情况下,他们实现了所谓的“零拷贝”,也就是说副本之间不再同步实际的数据文件,只会同步一些必要的元数据信息。是否果真如此呢?let me try~~
首先,我又找了一台机器,部署了相同版本的CK,并使用了相同的配置,并加上了多副本的配置,配置方法我在此处省略了,类似的文章很多,也可以在官方文档看到。
然后,使用ReplicatedMergeTree引擎,我创建了一张包含两个副本的库表,并采用HDFS作为存储。
create table test_data on cluster ck_cluster engine=ReplicatedMergeTree('/clickhouse/tables/replicated/{shard}/test_data','{replica}') order by id settings storage_policy='hdfs' as with (select ['A','a','A','A','B','B','B','B','B','A','59','90','80','85','90','929','80','72','90','123']) AS dict select dict[number%10 + 1] as id,dict[number + 11] as val from system.numbers limit 10;
本以为HDFS上只会存储一份数据,但是让我失望了,我看到的结果是同样的数据出现了两份,大小一样,名称不一样。
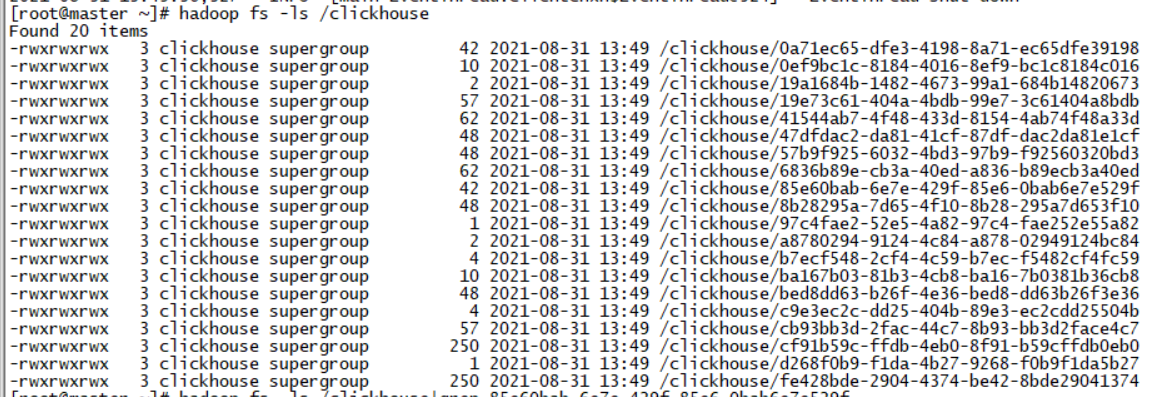
查了很多资料,没找到相应的说法,也许S3可以,我看git上的issue里很多都是关于S3的,希望有哪位朋友有机会的话可以用S3做个相同的测试,看看是否真的有零拷贝的现象。
总结
新版本的clickhouse确实支持了HDFS作为云存储的方案,配置也相对比较简单,使用该方案后,本地索引目录下依然会保留原来的文件名称,但里面的内容是该文件在HDFS上的映射名称,真正的索引和数据都保存在HDFS上。但在多副本的情况下,我在实验中并未看到零拷贝的功能生效,此处是留下的一个疑问。
最后
以上就是无语鸭子最近收集整理的关于clickhouse之HDFS云存储测试环境配置方法底层实现零拷贝总结的全部内容,更多相关clickhouse之HDFS云存储测试环境配置方法底层实现零拷贝总结内容请搜索靠谱客的其他文章。








发表评论 取消回复