在ClickHouse的整个体系里面,MergeTree表引擎绝对是一等公民,使用ClickHouse就是在使用MergeTree,这种说法一点也不为过。
众所周知,MergeTree表引擎是一个家族系列,目前整个系列一共包含了14种不同类型的MergeTree,可谓是功能丰富了吧?
但凡事都有两面性,功能丰富的同时也无疑让很多朋友犯了难。
这么多表引擎,它们之间是什么关系?
我们到底应该使用哪一种表引擎?
今天我就用这篇文章,尝试回答上述两个高频问题。
老师常教导我们要训练结构化思维,通过抽象、归纳等办法来分析一个事物,有时候会起到事半功倍的效果。
这么多表引擎,它们之间是什么关系?
我们可以使用两种关系,来理解整个MergeTree系列:
-
继承关系
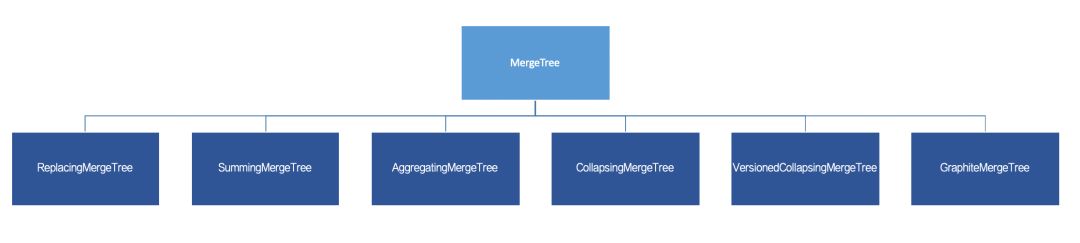
首先,为了便于理解,可以使用继承关系来看待MergeTree。通过最基础的MergeTree表引擎,向下派生出6个变种表引擎,如下图所示
在ClickHouse底层具体的实现方法中,上述7种表引擎的区别主要体现在Merge合并的逻辑部分。如下图所示,是我简化后的对象关系:
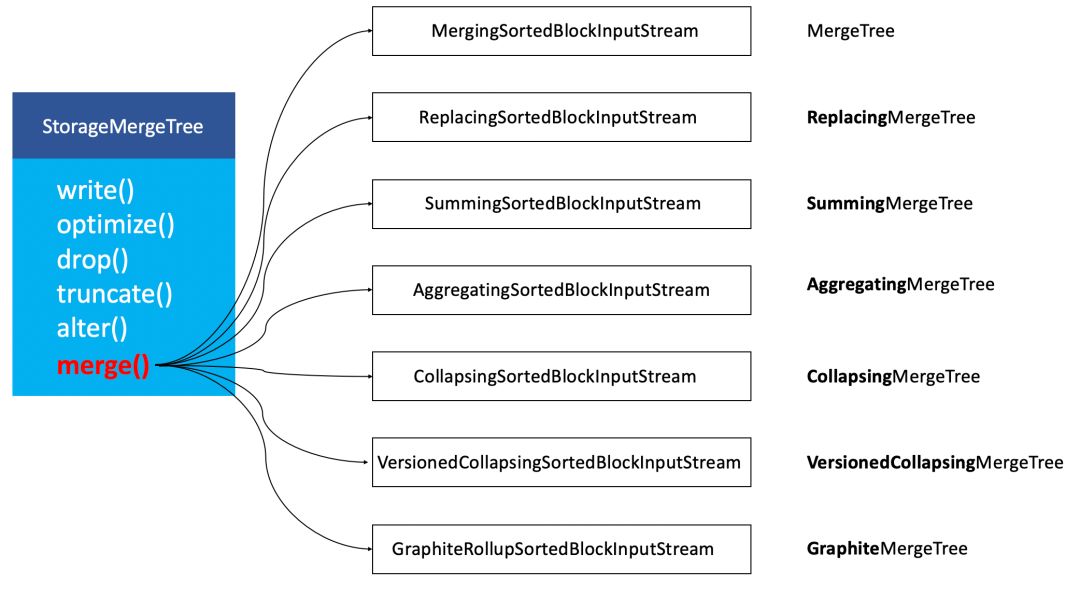
可以看到,在具体的实现逻辑部分,7种MergeTree共用一个主体,在触发Merge动作时,调用了各自独有的合并逻辑。
而除开MergeTree之外的其他6个变种表引擎,它们的Merge合并逻辑,全部是建立在MergeTree基础之上的,如下图所示:
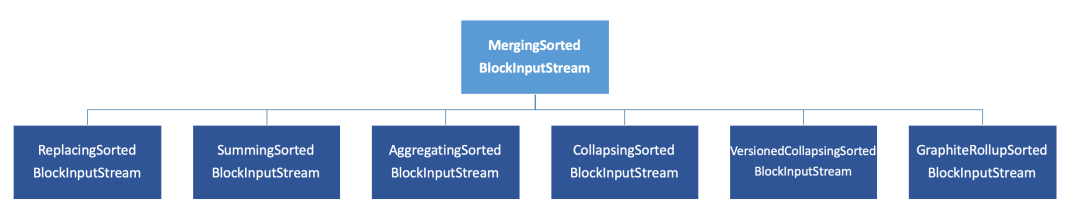
它们均继承于MergeTree的 MergingSortedBlockInputStream。
MergingSortedBlockInputStream 的主要作用,是按照ORDER BY的规则保持新分区数据的有序性。
而其他6种变种MergeTree的合并逻辑,则是在有序的基础之上 "各有所长",要么是将排序后相邻的重复数据消除、亦或是将它们累加汇总。
所以,从继承关系的角度来理解,我们不仅明白了这7种MergeTree的关系,也进一步明确了一个事实,它们的主要区别在Merge部分的逻辑,所以特殊功能只会在Merge合并时才会触发。
-
组合关系
刚才已经介绍了7种MergeTree的关系,余下的7种是ReplicatedMergeTree系列。
ReplicatedMergeTree与普通的MergeTree又有什么区别呢? 我们接着看下面这张图:
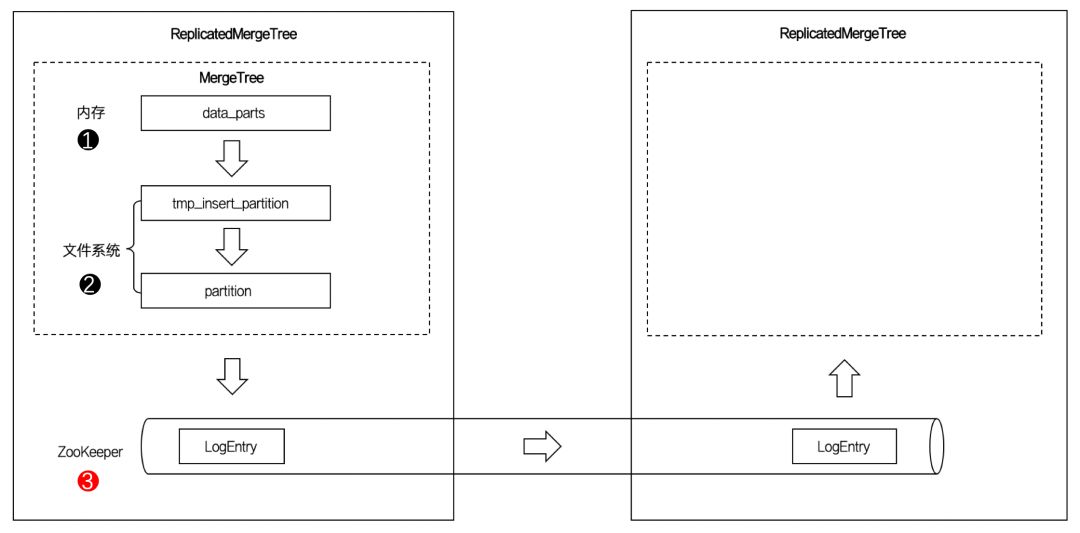
图中的虚线框部分是MergeTree的能力边界,而ReplicatedMergeTree在它的基础之上增加了分布式协同的能力。
借助ZooKeeper的消息日志广播,实现了副本实例之间的数据同步功能。
ReplicatedMergeTree系列可以用组合关系来理解,如下图所示:
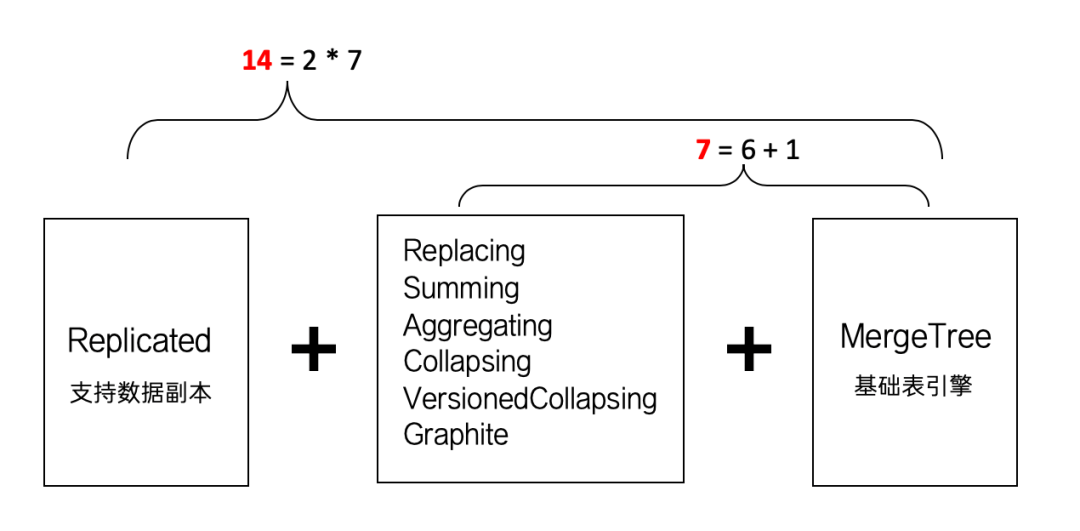
当我们为7种MergeTree加上Replicated前缀后,又能组合出7种新的表引擎,这些ReplicatedMergeTree拥有副本协同的能力。
我们到底应该使用哪一种表引擎?
现在回答第二个问题,按照使用的场景划分,可以将上述14种表引擎大致分成以下6类应用场景:
-
默认情况
在没有特殊要求的场合,使用基础的MergeTree表引擎即可,它不仅拥有高效的性能,也提供了所有MergeTree共有的基础功能,包括列存、数据分区、分区索引、一级索引、二级索引、TTL、多路径存储等等。
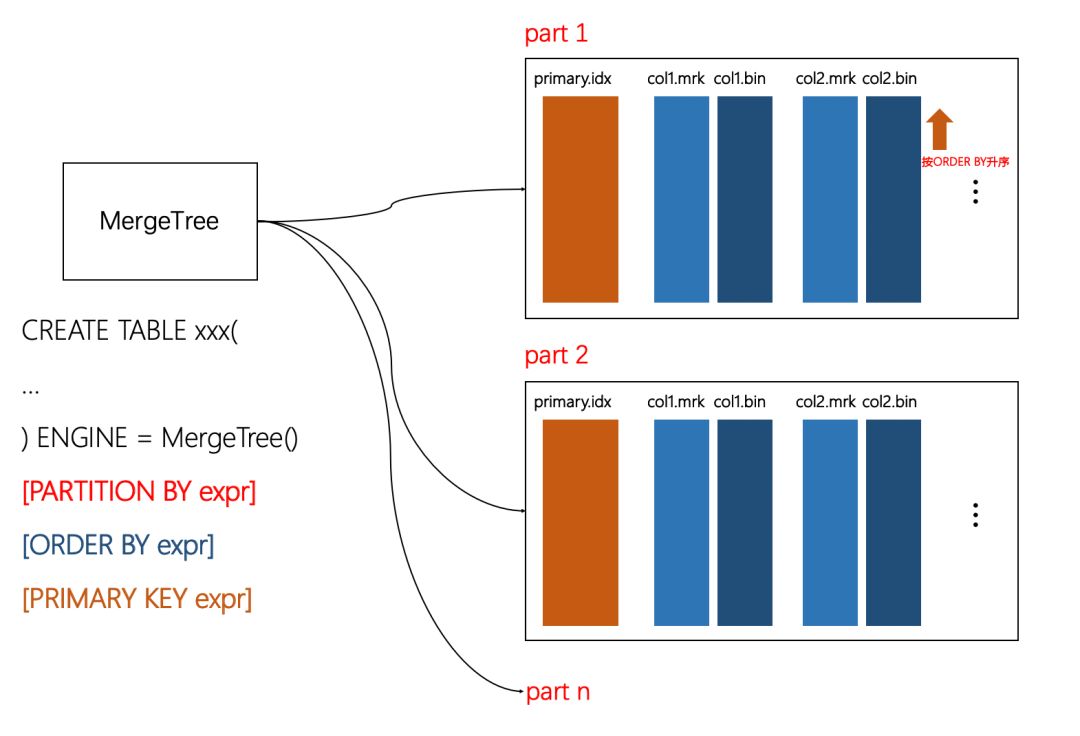
与此同时,它也定义了整个MergeTree家族的基调,例如:
ORDER BY 决定了每个分区中数据的排序规则;
PRIMARY KEY 决定了一级索引(primary.idx);
ORDER BY 可以指代PRIMARY KEY, 通常只用声明ORDER BY 即可。
接下来将要介绍的其他表引擎,除开ReplicatedMergeTree系列外,都是在Merge合并动作时添加了各自独有的逻辑。
-
数据去重
通过刚才的说明,大家应该明白,MergeTree的主键(PRIMARY KEY)只是用来生成一级索引(primary.idx)的,并没有唯一性约束这样的语义。
一些朋友在使用MergeTree的时候,用传统数据库的思维来理解MergeTree就会出现问题。
如果业务上不允许数据重复,遇到这类场景就可以使用ReplacingMergeTree,如下图所示:
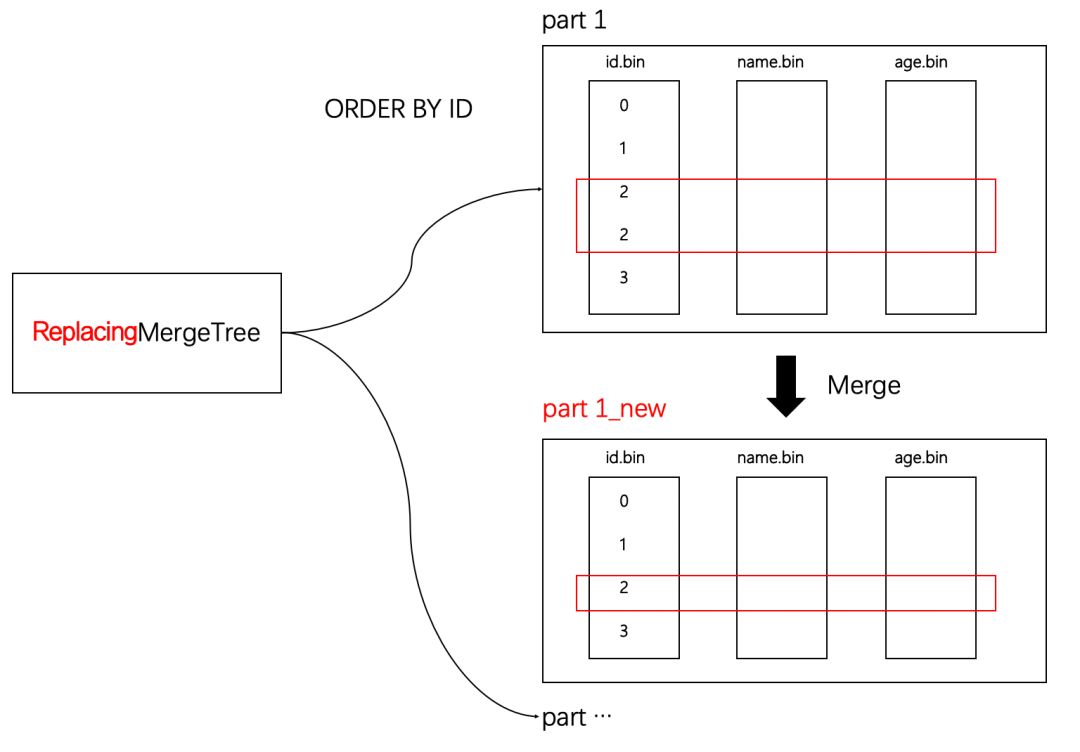
ReplacingMergeTree通过ORDER BY,表示判断唯一约束的条件。当分区合并之时,根据ORDER BY排序后,相邻重复的数据会被排除。
由此,可以得出几点结论:
第一,使用ORDER BY作为特殊判断标识,而不是PRIMARY KEY。关于这一点网上有一些误传,但是如果理解了ORDER BY与PRIMARY KEY的作用,以及合并逻辑之后,都能够推理出应该是由ORDER BY决定。
ORDER BY的作用, 负责分区内数据排序;
PRIMARY KEY的作用, 负责一级索引生成;
Merge的逻辑, 分区内数据排序后,找到相邻的数据,做特殊处理。
第二,只有在触发合并之后,才能触发特殊逻辑。以去重为例,在没有合并的时候,还是会出现重复数据。
第三,只对同一分区内的数据有效。以去重为例,只有属于相同分区的数据才能去重,跨越不同分区的重复数据不能去重。
上述几点结论,适用于包含ReplacingMergeTree在内的6种MergeTree,所以后面不在赘述。
-
预聚合(数据立方体)
有这么一类场景,它的查询主题是非常明确的,也就是说聚合查询的维度字段是固定,并且没有明细数据的查询需求,这类场合就可以使用SummingMergeTree或是AggregatingMergeTree,如下图所示:
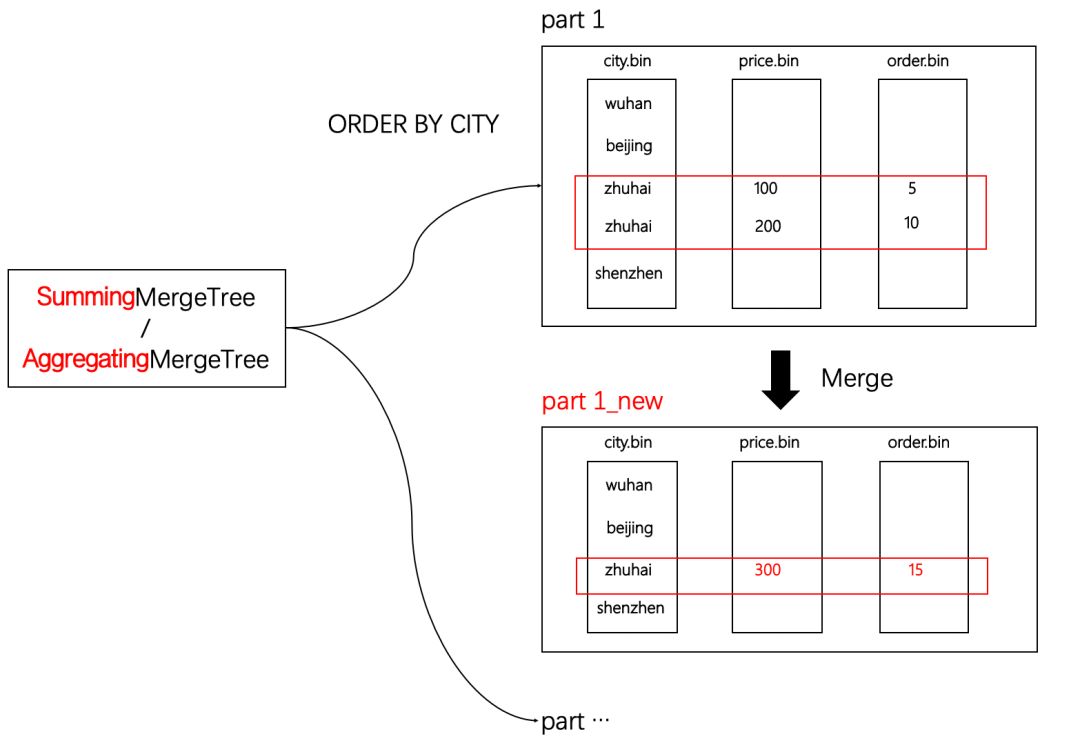
可以看到,在新分区合并后,在同一分区内,ORDER BY条件相同的数据会进行合并。如此一来,首先表内的数据行实现了有效的减少,其次度量值被预先聚合,进一步减少了后续计算开销。
聚合类MergeTree通常可以和表引擎协同使用,如下图所示:
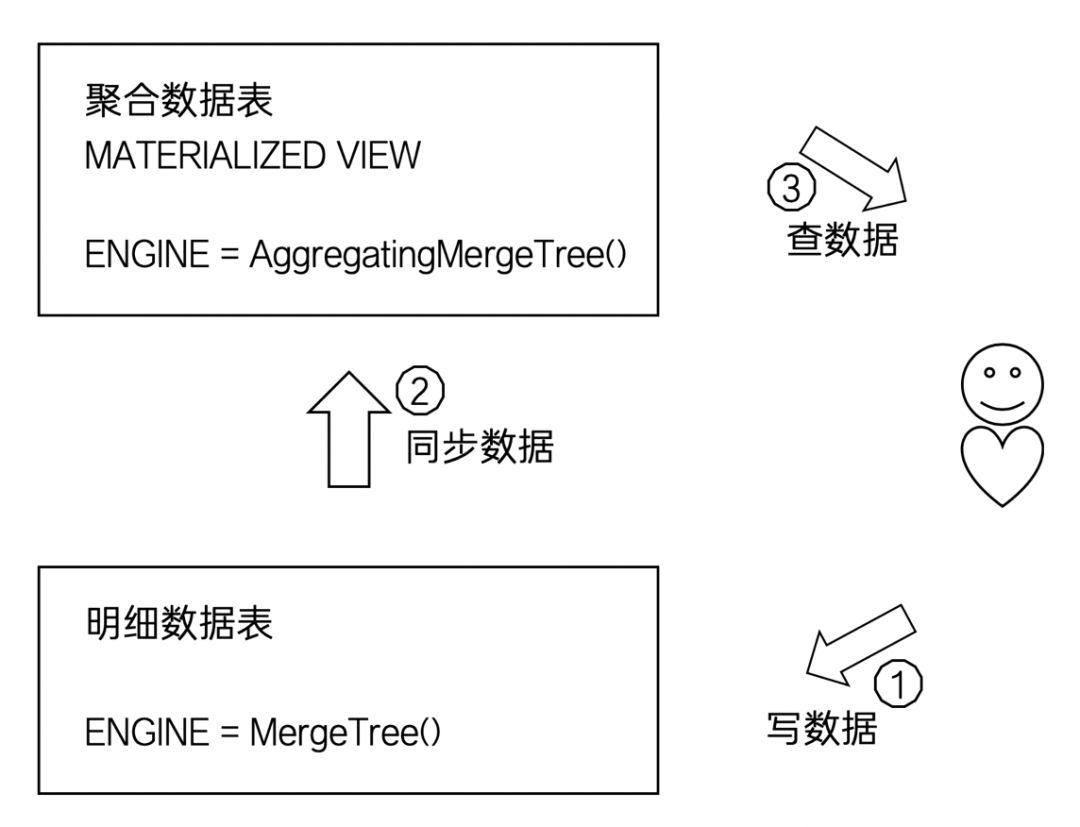
可以将物化视图设置成聚合类MergeTree,将其作为固定主题的查询表使用。
值得一提的是,通常只有在使用SummingMergeTree或AggregatingMergeTree的时候,才需要同时设置ORDER BY与PRIMARY KEY。
显式的设置PRIMARY KEY,是为了将主键和排序键设置成不同的值,是进一步优化的体现。
例如某个场景的查询需求如下:
聚合条件,GROUP BY A,B,C
过滤条件,WHERE A
此时,如下设置将会是一种较优的选择:
GROUP BY A,B,C
PRIMARY KEY A
BTW,如果ORDER BY与PRIMARY KEY不同,PRIMARY KEY必须是ORDER BY的前缀(为了保证分区内数据和主键的有序性)。
-
数据更新
数据的更新在ClickHouse中有多种实现手段,例如按照分区Partition重新写入、使用Mutation的DELETE和UPDATE查询。
使用CollapsingMergeTree或VersionedCollapsingMergeTree也能实现数据更新,这是一种使用标记位,以增代删的数据更新方法,如下图所示:
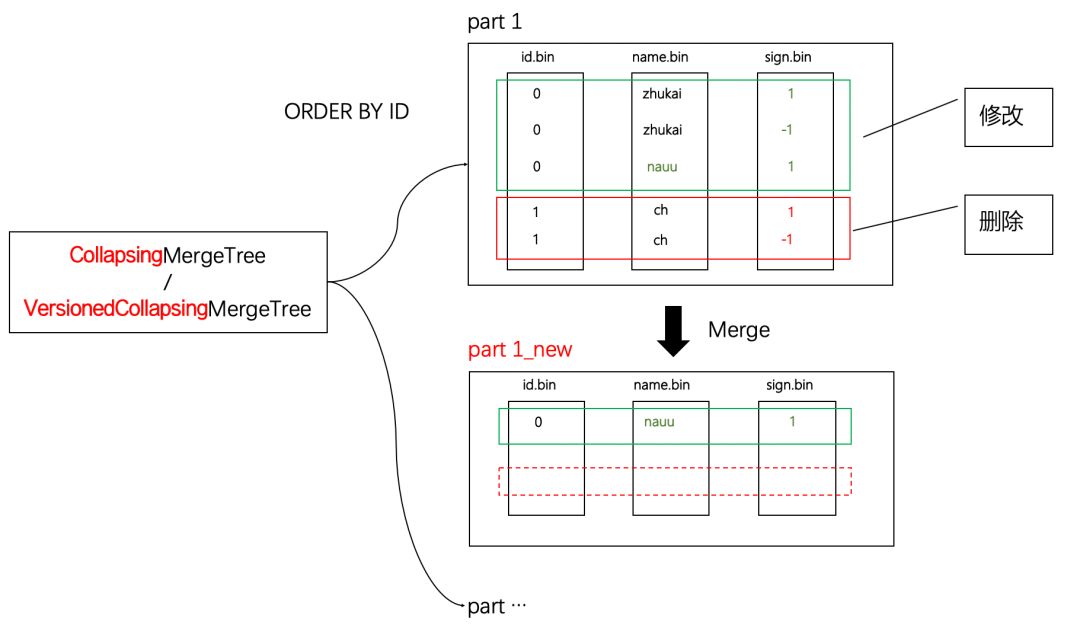
通过增加一个标志字段(例如图中的sigh字段),作为数据有效性的判断依据。
可以看到,在新分区合并后,在同一分区内,ORDER BY条件相同的数据,其标志值为1和-1的数据行会进行抵消。
下图是另外一种便于理解的视角,就如同挤压瓦楞纸一般,数据被抵消了:
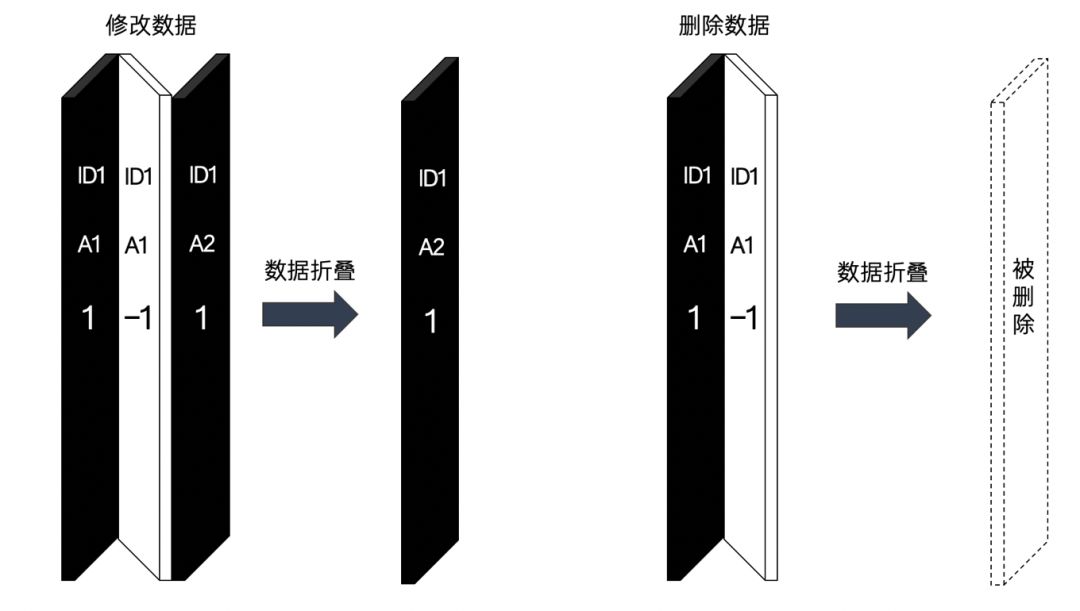
CollapsingMergeTree和VersionedCollapsingMergeTree的区别又是什么呢?
CollapsingMergeTree对数据写入的顺序是敏感的,它要求标志位需要按照正确的顺序排序。例如按照1,-1的写入顺序是正确的; 而如果按照-1,1的错误顺序写入,CollapsingMergeTree就无法正确抵消。
试想,如果在一个多线程并行的写入场景,我们是无法保证这种顺序写入的,此时就需要使用VersionedCollapsingMergeTree了。
VersionedCollapsingMergeTree在CollapsingMergeTree基础之上,额外要求指定一个version字段,在分区Merge合并时,它会自动将version字段追加到ORERY BY的末尾,从而保证了标志位的有序性。
ENGINE = VersionedCollapsingMergeTree(sign,ver)ORDER BY id//等效于ORDER BY id,ver
-
监控集成
GraphiteMergeTree可以与Graphite集成,如果你使用了Graphite作为系统的运行监控系统, 则可以通过GraphiteMergeTree存储指标数据,加速查询性能、降低存储成本。
-
高可用
Replicated* 拥有数据副本的能力,如下图所示:
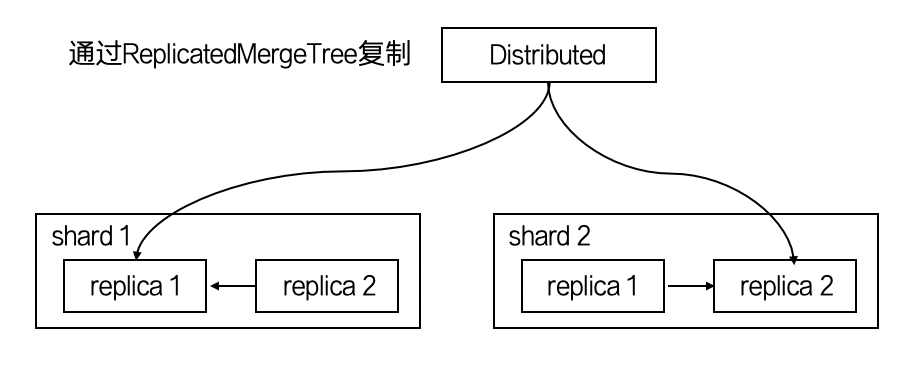
结合刚才的5类场景,如果进一步需要高可用的需求,选择一种MergeTree和Replicated组合即可,例如ReplicatedMergeTree、ReplicatedReplacingMergeTree等等。
最后
以上就是欢呼鞋垫最近收集整理的关于ClickHouse各种MergeTree的关系与作用的全部内容,更多相关ClickHouse各种MergeTree内容请搜索靠谱客的其他文章。








发表评论 取消回复