
文章目录
客快物流大数据项目学习框架
前言
一、项目简介
二、功能介绍
三、项目背景
四、服务器资源规划
五、技术亮点及价值
六、智慧物流大数据平台
客快物流大数据项目学习框架
前言
利用框架的力量,看懂游戏规则,才是入行的前提
大多数人不懂,不会,不做,才是你的机会,你得行动,不能畏首畏尾
选择才是拉差距关键,风向,比你流的汗水重要一万倍,逆风划船要累死人的
上面这些看似没用,但实际很重要,这里我就不再具体说明,感兴趣的同学可以看看我的大数据学习探讨话题:
学习框架的重要性
我是怎么坚持学习的
怎么确定学习目标
这个栏目为缺少项目的同学全面整理的客快物流大数据项目逻辑,内容是按基础环境搭建到项目架构设计,带你从基础到架构实战,想学会就得自律加坚持,赶快行动吧。
一、项目简介
本项目基于大型物流公司研发的智慧物流大数据平台,该物流公司是国内综合性快递、物流服务商,并在全国各地都有覆盖的网点。经过多年的积累、经营以及布局,拥有大规模的客户群,日订单达上千万,如此规模的业务数据量,传统的数据处理技术已经不能满足企业的经营分析需求。该公司需要基于大数据技术构建数据中心,从而挖掘出隐藏在数据背后的信息价值,为企业提供有益的帮助,带来更大的利润和商机
该大数据项目主要围绕订单、运输、仓储、搬运装卸、包装以及流通加工等物流环节中涉及的数据、信息等。通过大数据分析可以提高运输以及配送效率、减少物流成本、更有效地满足客户服务要求,实现快速、高效、经济的物流,并针对数据分析结果,提出具有中观指导意义的解决方案
物流大数据可以根据市场进行数据分析,提高运营管理效率,合理规划分配资源,调整业务结构,确保每个业务均可盈利。根据数据分析结果,规划、预计运输路线和配送路线,缓解运输高峰期的物流行为,提高客户的满意度,提高客户粘度。
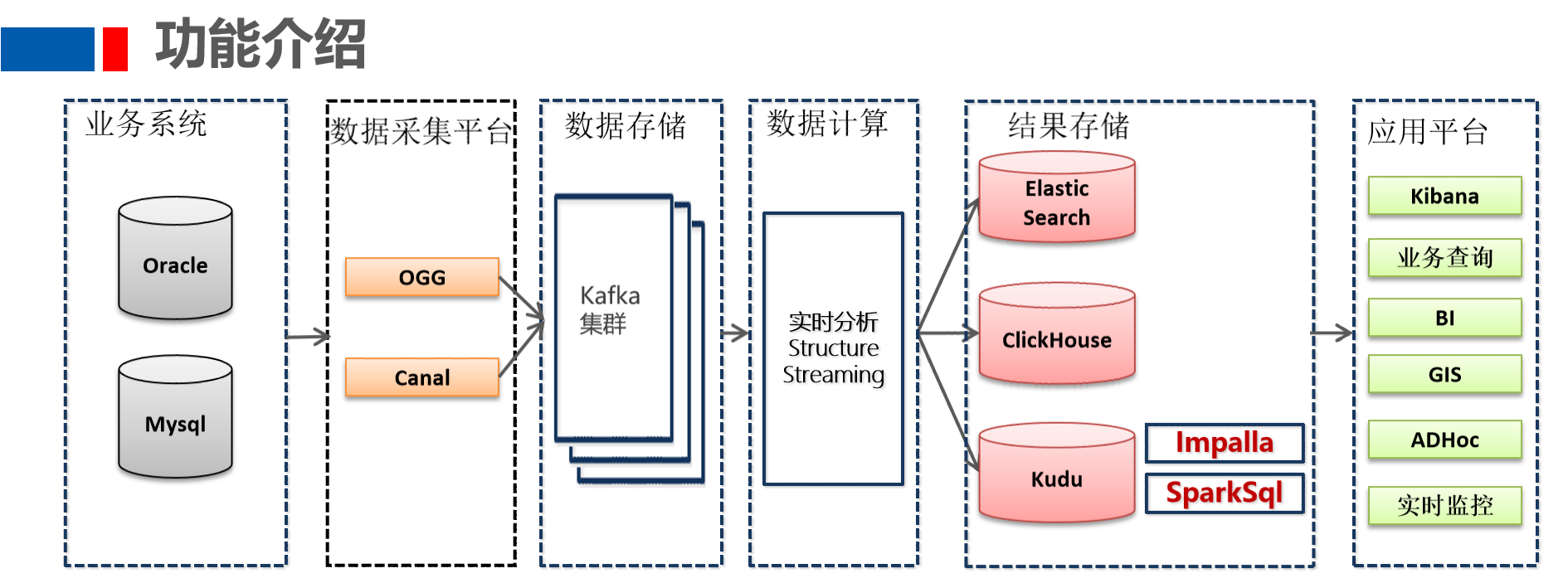
二、功能介绍
- 业务系统数据主要存放到Oracle和Mysql数据库中,比如CRM系统数据在Mysql,OMS系统数据存放在Oracle中
- OGG增量同步Oracle数据库的数据,Canal增量同步Mysql数据库的数据
- OGG及Canal增量抽取的数据会写入到Kafka集群,供实时分析计算程序消费
- 实时分析计算程序消费kafka的数据,将消费出来的数据进行ETL操作
- 为了方便业务部门对各类单据的查询,StructureStreaming流式处理系统将数据经过JOIN处理后,将数据写入到Elastic Search中
- StructureStreaming流处理会将数据写入到ClickHouse,Java Web后端直接将数据查询出来进行展示
- StructureStreaming将实时ETL处理后的数据同步更新到Kudu中,方便进行数据的准实时分析、查询。Impala对kudu数据进行分析查询
- 前端应用对数据进行可视化展示
三、项目背景
本项目基于一家大型物流公司研发的智慧物流大数据平台。该物流公司是国内综合性快递、物流服务商,并在全国各地都有覆盖的网点。经过多年的积累、经营以及布局,拥有大规模的客户群,日订单达上千万。以下列举了国内的几家物流公司某个月份的数据:
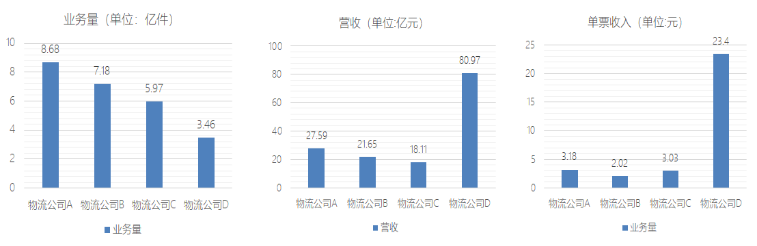
如此规模的业务数据量,传统的数据处理技术已经不能满足企业的经营分析需求。该公司需要基于大数据技术构建数据中心,从而挖掘出隐藏在数据背后的信息价值,为企业提供有益的帮助,带来更大的利润和商机。而自2012年,国家已陆续出台相关的产业规划和政策,也从侧面推动了大数据产业的发展。
该大数据项目主要围绕订单、运输、仓储、搬运装卸、包装以及流通加工等物流环节中涉及的数据、信息等。通过大数据分析可以提高运输以及配送效率、减少物流成本、更有效地满足客户服务要求,实现快速、高效、经济的物流,并针对数据分析结果,提出具有中观指导意义的解决方案。
物流大数据可以根据市场进行数据分析,提高运营管理效率,合理规划分配资源,调整业务结构,确保每个业务均可盈利。根据数据分析结果,规划、预计运输路线和配送路线,环节运输高峰期的物流行为,提高客户的满意度,提高客户粘度。
四、服务器资源规划
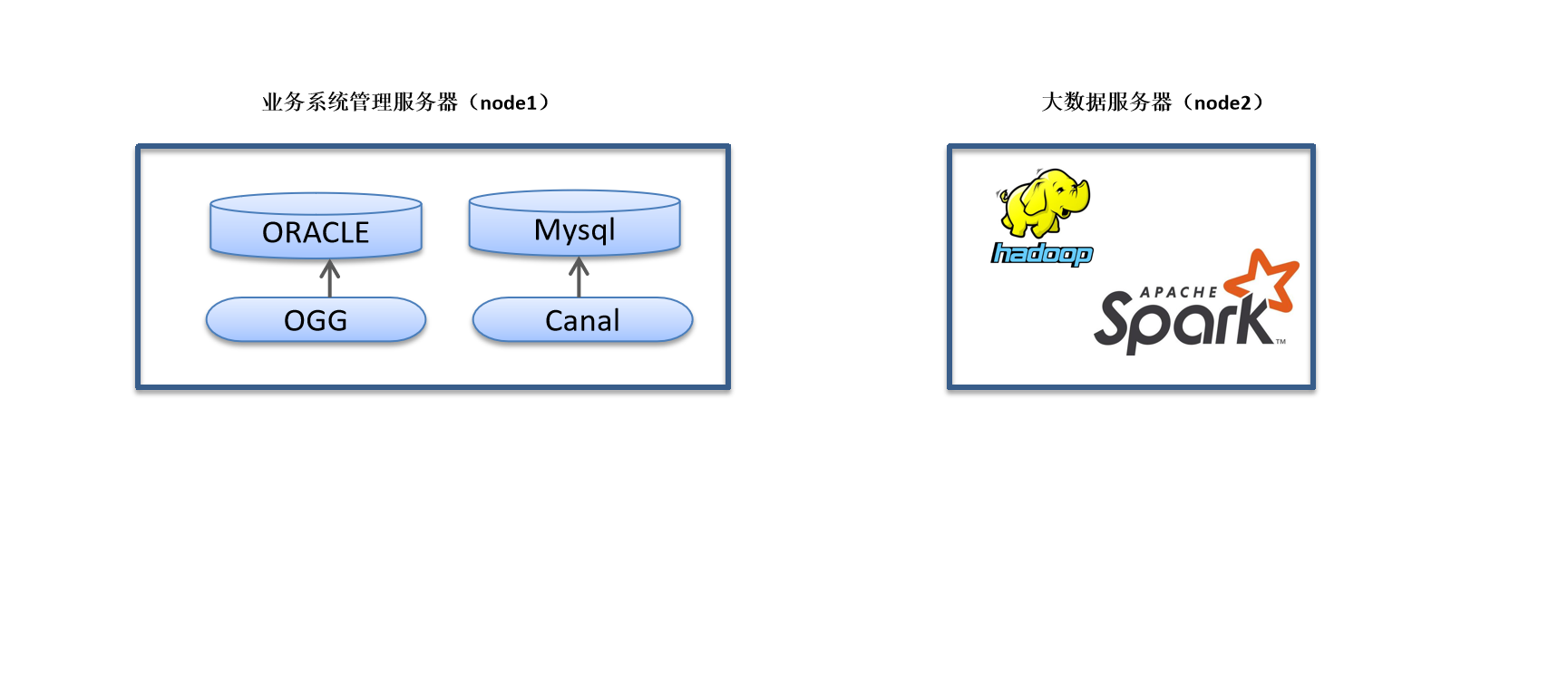
因服务器资源有限,该项目采用两台服务器进行演示,每台服务器配置如下:
| 用途 | 主机名 | 操作系统/版本 | IP | 内存 | 硬盘 |
| 业务系统服务器 | node1 | Centos/7.5.1804 | 192.168.88.10 | 3GB | 40G |
| 大数据服务器 | node2 | Centos/7.5.1804 | 192.168.88.20 | 12GB | 60G |
使用到的软件信息:
| 服务器 | node1 | node2 |
| Docker | √ | |
| Oracle(11g) | √ | |
| OGG | √ | |
| MySql 5.7 | √ | |
| Canal | √ | |
| Hadoop | √ | |
| Spark | √ | |
| Kafka | √ | |
| ClickHouse | √ | |
| ElasticSearch | √ | |
| Kudu | √ | |
| Azkaban | √ | |
| Impala | √ | |
| HUE | √ |
五、技术亮点及价值
- 基于Docker搭建异构数据源,还原企业真实应用场景
- 以企业主流的Spark生态圈为核心技术,例如:Structure Streaming
- Azkaban定时调度主题及指标统计作业
- Kudu + Impala准实时分析系统
- 使用HUE集成Impala进行数据即席查询
- ClickHouse实时存储、计算引擎
- 自定义数据源实现Spark与Clickhouse的整合
- ELK全文检索
- Spring Cloud搭建数据服务
- 存储、计算性能调优
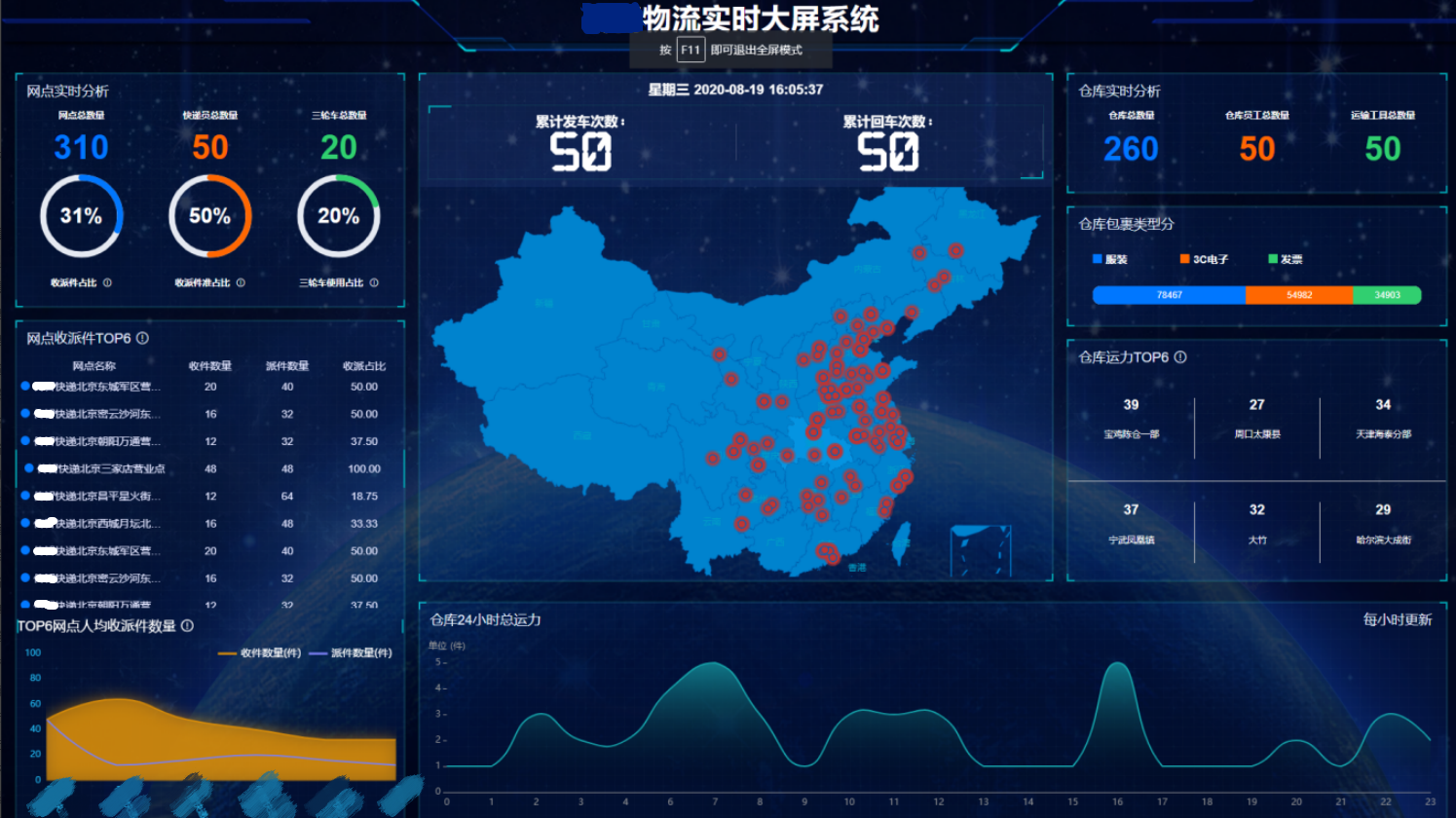
六、智慧物流大数据平台
- ????博客主页:https://lansonli.blog.csdn.net
- ????欢迎点赞 ???? 收藏 ⭐留言 ???? 如有错误敬请指正!
- ????本文由 Lansonli 原创,首发于 CSDN博客????
- ????停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
最后
以上就是文艺大船最近收集整理的关于客快物流大数据项目学习框架客快物流大数据项目学习框架的全部内容,更多相关客快物流大数据项目学习框架客快物流大数据项目学习框架内容请搜索靠谱客的其他文章。








发表评论 取消回复