一、本地事务
1.1 事务的基本性质
数据库事务的几个特性(ACID):
原子性(Atomicity )、一致性( Consistency )、隔离性或独立性( Isolation)
和持久性(Durabilily),简称就是 ACID;
原子性:一系列的操作整体不可拆分,要么同时成功,要么同时失败
一致性:数据在事务的前后,业务整体一致,
比如:转账。A:1000;B:1000; 转 200 事务成功; A:800 B:1200
隔离性:事务之间互相隔离。
持久性:一旦事务成功,数据一定会落盘在数据库。
在以往的单体应用中,我们多个业务操作使用同一条连接操作不同的数据表,一旦有异常,
我们可以很容易的整体回滚;
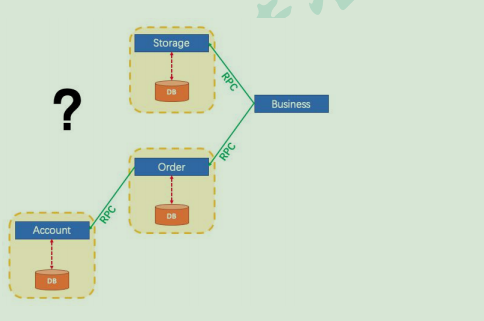
Business:我们具体的业务代码
Storage:库存业务代码;扣库存
Order:订单业务代码;保存订单
Account:账号业务代码;减账户余额
比如买东西业务,扣库存,下订单,账户扣款,是一个整体;必须同时成功或者失败
一个事务开始,代表以下的所有操作都在同一个连接里面;
1.2 事务的隔离级别
1. READ UNCOMMITTED(读未提交)
该隔离级别的事务会读到其它未提交事务的数据,此现象也称之为脏读。
2. READ COMMITTED(读提交)
一个事务可以读取另一个已提交的事务,多次读取会造成不一样的结果,此现象称为不可重
复读问题,Oracle 和 SQL Server 的默认隔离级别。
3. REPEATABLE READ(可重复读)
该隔离级别是 MySQL 默认的隔离级别,在同一个事务里,select 的结果是事务开始时时间
点的状态,也就是说在同一个事务里面,它读到的值都是刚开始读取的值,即使这个值被其他事务更改或删除。因此,同样的 select 操作读到的结果会是一致的,但是,会有幻读现象。MySQL
的 InnoDB 引擎可以通过 next-key locks 机制(参考下文"行锁的算法"一节)来避免幻读。
4. SERIALIZABLE(序列化)
在该隔离级别下事务都是串行顺序执行的,MySQL 数据库的 InnoDB 引擎会给读操作隐式
加一把读共享锁,从而避免了脏读、不可重读复读和幻读问题。
1.3 事务的传播行为
1、★PROPAGATI
ON_REQUIRED:如果当前没有事务,就创建一个新事务,如果当前存在事务,
就加入该事务,该设置是最常用的设置。
2、PROPAGATION_SUPPORTS:支持当前事务,如果当前存在事务,就加入该事务,如果当
前不存在事务,就以非事务执行。
3、PROPAGATION_MANDATORY:支持当前事务,如果当前存在事务,就加入该事务,如果
当前不存在事务,就抛出异常。
4、★PROPAGATION_REQUIRES_NEW:创建新事务,无论当前存不存在事务,都创建新事务。
5、PROPAGATION_NOT_SUPPORTED:以非事务方式执行操作,如果当前存在事务,就把当
前事务挂起。
6、PROPAGATION_NEVER:以非事务方式执行,如果当前存在事务,则抛出异常。
7、PROPAGATION_NESTED:如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,
则执行与 PROPAGATION_REQUIRED 类似的操作。
1.4 实例
// isolation :设置事务的隔离级别;propagation:设置事务的传播级别
@Transactional(isolation = Isolation.READ_COMMITTED,propagation = Propagation.REQUIRED)

1.4 本地事务失效的问题
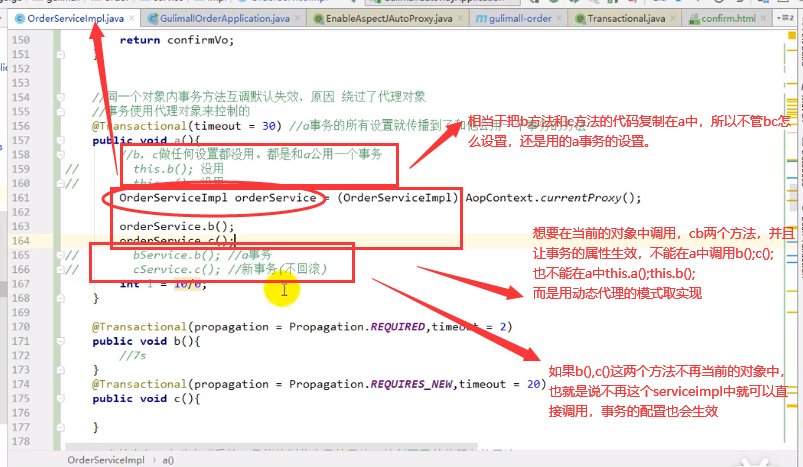
在同一个类里面,编写两个方法,内部调用的时候,会导致事务设置失效。原因是没有用到代理对象的缘故。
解决:
0)、导入 spring-boot-starter-aop
1)、@EnableTransactionManagement(proxyTargetClass = true)
2)、@EnableAspectJAutoProxy(exposeProxy=true)
3)、AopContext.currentProxy()
第一步:添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
第二步:配置
//开启了aspect动态代理模式,exposeProxy =true 对外暴露代理对象
@EnableAspectJAutoProxy(exposeProxy = true)
第三步:测试:
二、分布式事务
2.1 为什么有分布式事务
分布式系统经常出现的异常
机器宕机、网络异常、消息丢失、消息乱序、数据错误、不可靠的 TCP、存储数据丢失…
2.2 CAP 定理与 BASE 理论
CAP 定理
CAP 原则又称 CAP 定理,指的是在一个分布式系统中
一致性(Consistency):
在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访
问同一份最新的数据副本)
可用性(Availability)
在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据
更新具备高可用性)
分区容错性(Partition tolerance)
大多数分布式系统都分布在多个子网络。每个子网络就叫做一个区(partition)。
分区容错的意思是,区间通信可能失败。比如,一台服务器放在中国,另一台服务
器放在美国,这就是两个区,它们之间可能无法通信。
CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾
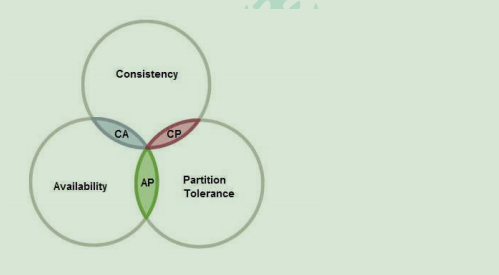
一般来说,分区容错无法避免,因此可以认为 CAP 的 P 总是成立。CAP 定理告诉我们,
剩下的 C 和 A 无法同时做到。
分布式系统中实现一致性的 raft 算法、paxos
http://thesecretlivesofdata.com/raft/
2.3 面临的问题
对于多数大型互联网应用的场景,主机众多、部署分散,而且现在的集群规模越来越大,所
以节点故障、网络故障是常态,而且要保证服务可用性达到 99.99999%(N 个 9),即保证
P 和 A,舍弃 C。
2.4 BASE 理论

2.5 强一致性、弱一致性、最终一致性
从客户端角度,多进程并发访问时,更新过的数据在不同进程如何获取的不同策略,决定了
不同的一致性。对于关系型数据库,要求更新过的数据能被后续的访问都能看到,这是强一
致性。如果能容忍后续的部分或者全部访问不到,则是弱一致性。如果经过一段时间后要求
能访问到更新后的数据,则是最终一致性
三、分布式事务几种方案
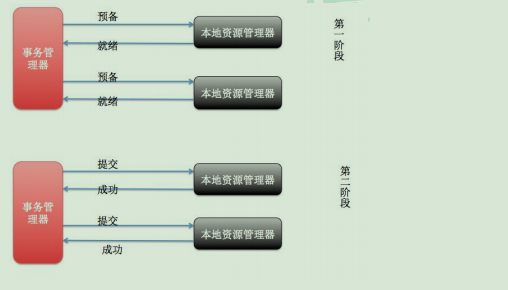
3.1 2PC 模式
数据库支持的 2PC【2 phase commit 二阶提交】,又叫做 XA Transactions。
MySQL 从 5.5 版本开始支持,SQL Server 2005 开始支持,Oracle 7 开始支持。
其中,XA 是一个两阶段提交协议,该协议分为以下两个阶段:
第一阶段:事务协调器要求每个涉及到事务的数据库预提交(precommit)此操作,并反映是
否可以提交. 第二阶段:事务协调器要求每个数据库提交数据。
其中,如果有任何一个数据库否决此次提交,那么所有数据库都会被要求回滚它们在此事务
中的那部分信息。

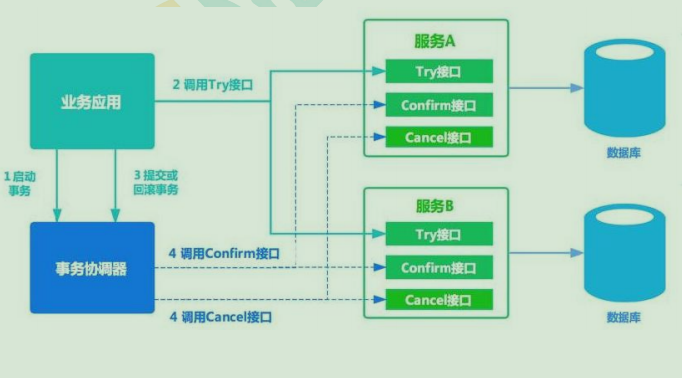
3.2 柔性事务-TCC 事务补偿型方案
刚性事务:遵循 ACID 原则,强一致性。
柔性事务:遵循 BASE 理论,最终一致性;
与刚性事务不同,柔性事务允许一定时间内,不同节点的数据不一致,但要求最终一致。
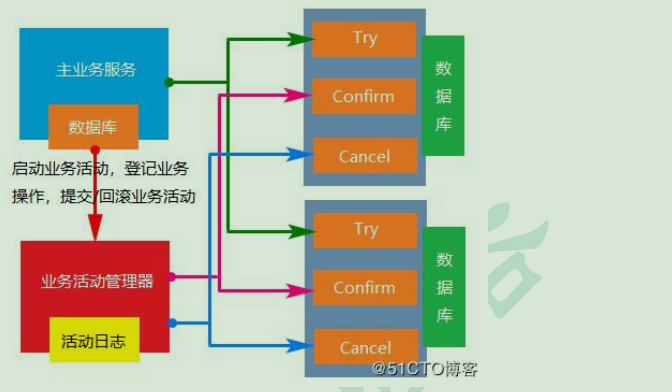
一阶段 prepare 行为:调用 自定义 的 prepare 逻辑。
二阶段 commit 行为:调用 自定义 的 commit 逻辑。
二阶段 rollback 行为:调用 自定义 的 rollback 逻辑。
所谓 TCC 模式,是指支持把 自定义 的分支事务纳入到全局事务的管理中。
3.3 柔性事务-最大努力通知型方案
按规律进行通知,不保证数据一定能通知成功,但会提供可查询操作接口进行核对。这种
方案主要用在与第三方系统通讯时,比如:调用微信或支付宝支付后的支付结果通知。这种
方案也是结合 MQ 进行实现,例如:通过 MQ 发送 http 请求,设置最大通知次数。达到通
知次数后即不再通知。
案例:银行通知、商户通知等(各大交易业务平台间的商户通知:多次通知、查询校对、对
账文件),支付宝的支付成功异步回调
3.4 ★柔性事务-可靠消息+最终一致性方案(异步确保型)
实现:业务处理服务在业务事务提交之前,向实时消息服务请求发送消息,实时消息服务只
记录消息数据,而不是真正的发送。业务处理服务在业务事务提交之后,向实时消息服务确
认发送。只有在得到确认发送指令后,实时消息服务才会真正发送。
防止消息丢失:
/**
- 1、做好消息确认机制(pulisher,consumer【手动 ack】)
- 2、每一个发送的消息都在数据库做好记录。定期将失败的消息再次发送一
遍
*/
四、分布式事务Seata
这种方式时2pc模式模式不适合高并发,可以在后台管理系统的接口中使用。
Seata官网:http://seata.io/zh-cn/
4.1 使用步骤
AT模式的使用步骤,AT模式不适合高并发,可以在后台管理系统的接口中使用。
Seata控制分布式事务
* 1)、每一个微服务必须创建undo_Log
* 2)、安装事务协调器:seate-server
* 3)、整合
* 1、导入依赖
* 2、解压并启动seata-server:
* registry.conf:注册中心配置 修改 registry : nacos
* 3、所有想要用到分布式事务的微服务使用seata DataSourceProxy 代理自己的数据源
* 4、每个微服务,都必须导入 registry.conf file.conf
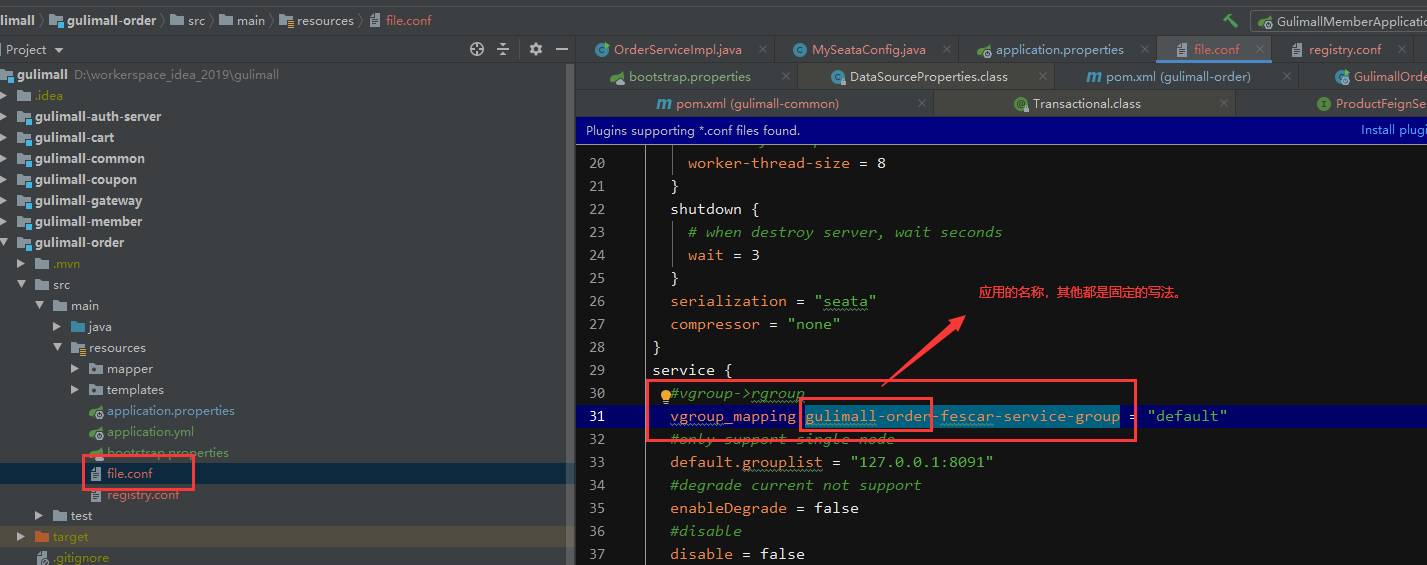
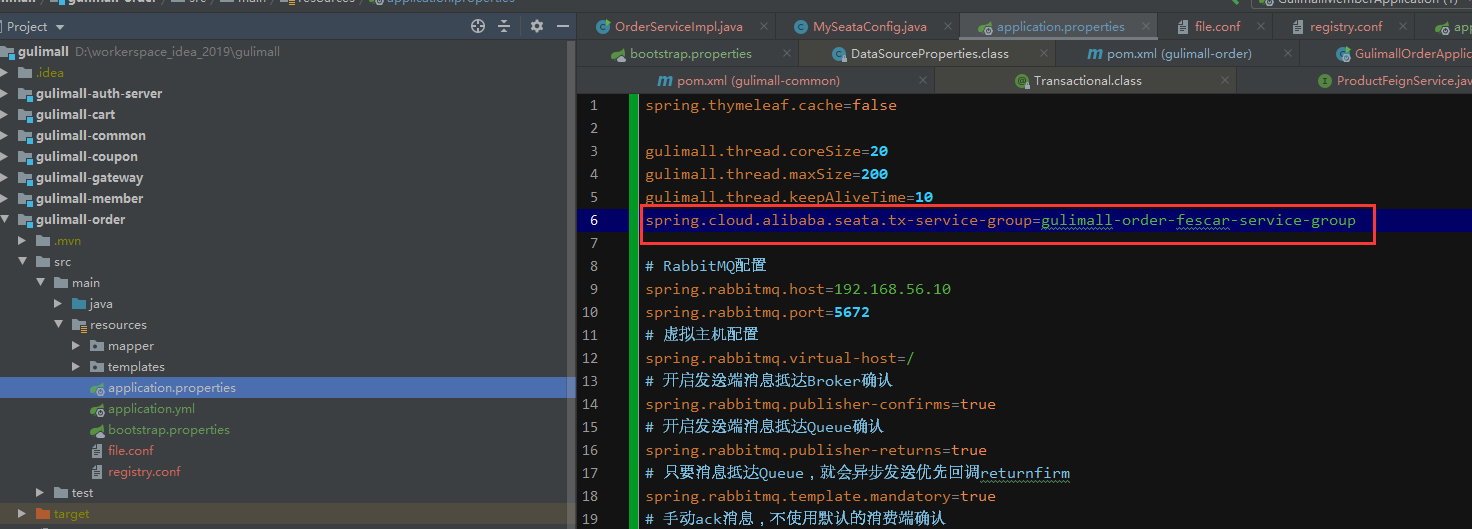
* vgroup_mapping.{application.name}-fescar-server-group = "default"
* 5、启动测试分布式事务
* 6、给分布式大事务的入口标注@GlobalTransactional
* 7、每一个远程的小事务用@Trabsactional
第一步:在每个微服务数据库中新建一个表
-- 注意此处0.3.0+ 增加唯一索引 ux_undo_log
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
`ext` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
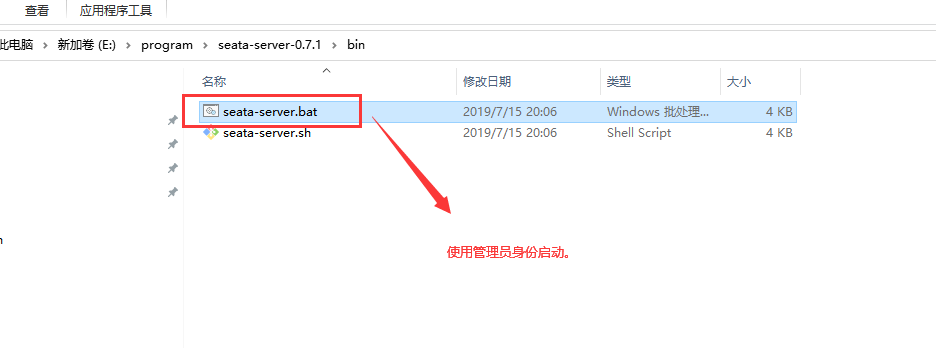
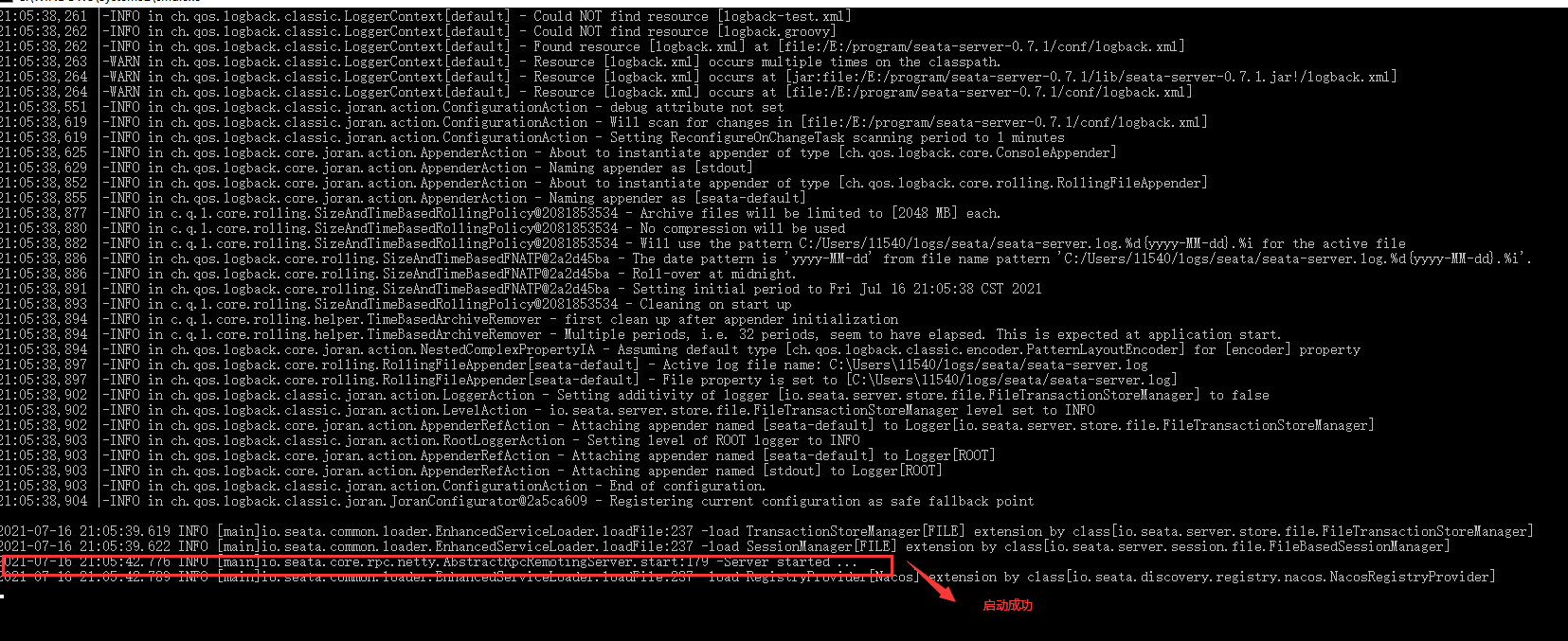
第二步:安装事务协调器:Seata-server
下载地址:https://github.com/seata/seata/releases
下载:v0.7.1 版本
第三步:整合
3.1)导入依赖
由于很多微服务中都会用到seata所以我们把依赖导入到common中
<!--seata分布式事务-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
</dependency>
注意:导入后的依赖中有一个,seata-all 他的版本时0.7.1 这样的话我们的seata服务器的版本也得时0.7.1
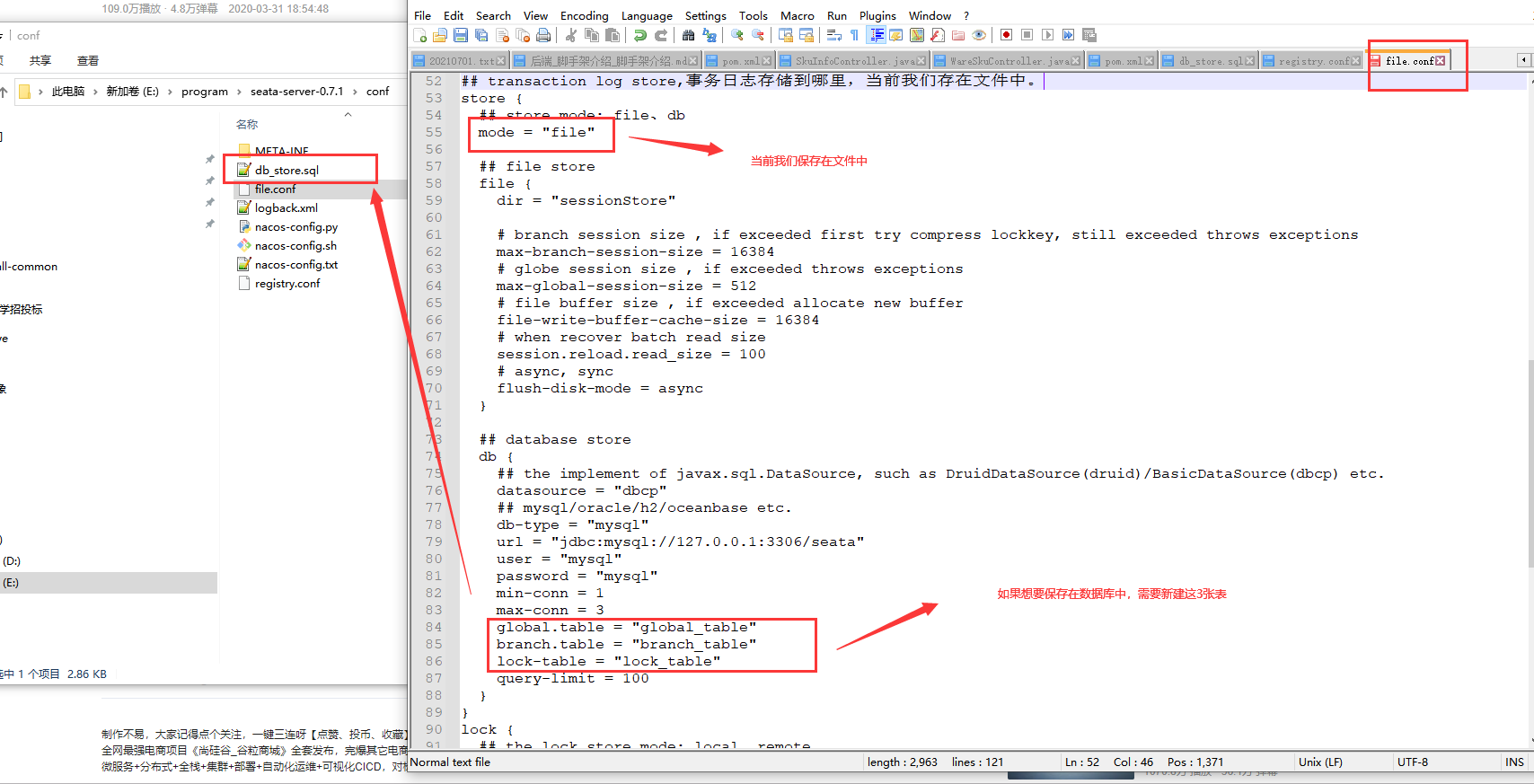
3.2)解压并启动seata-server registry.conf:注册中心配置 修改 registry : nacos
解压0.7.1 版本的额seata服务器
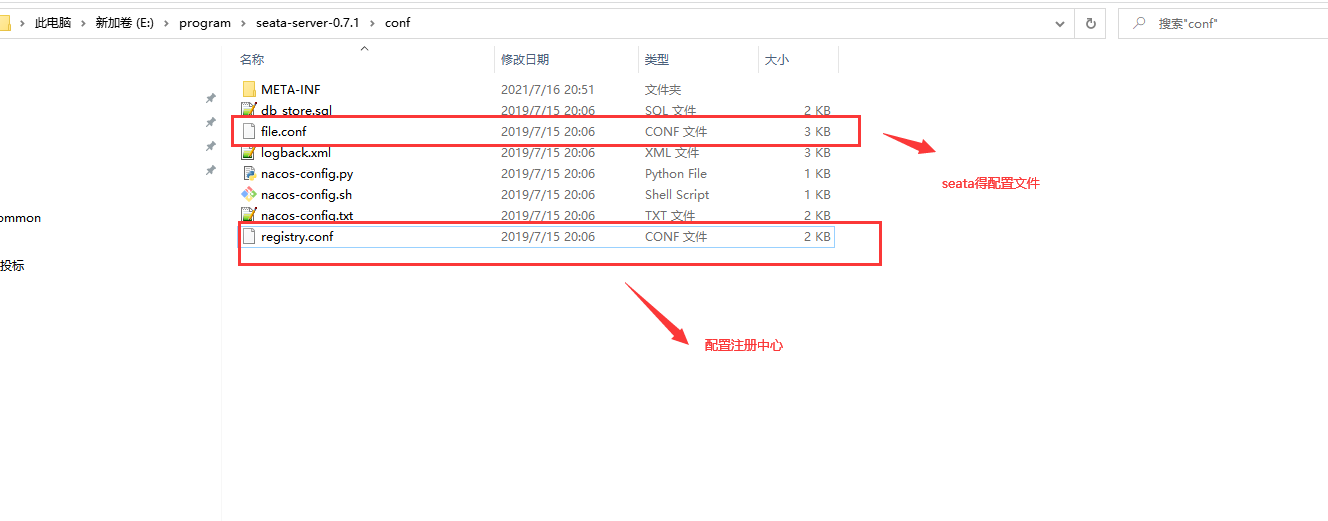
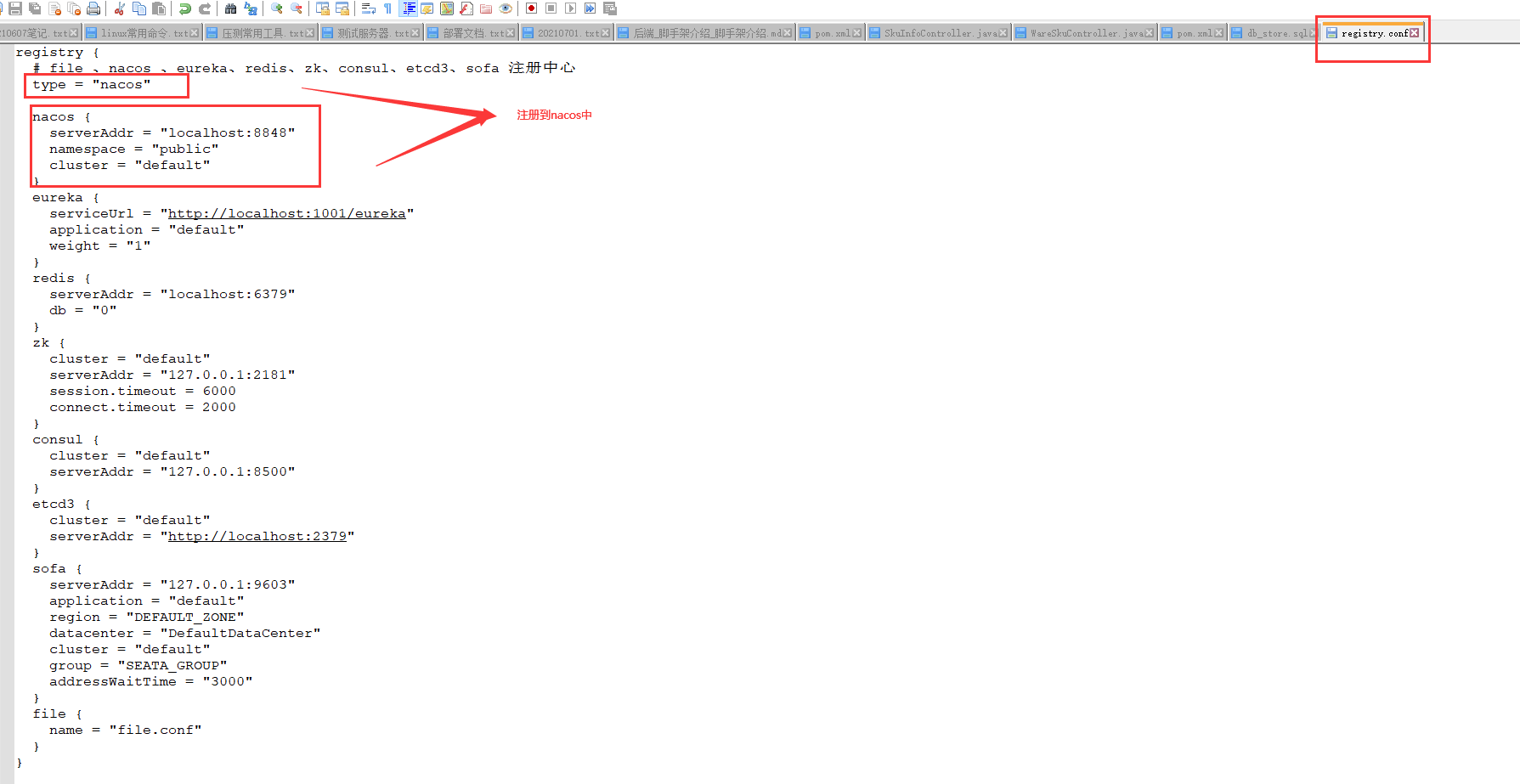
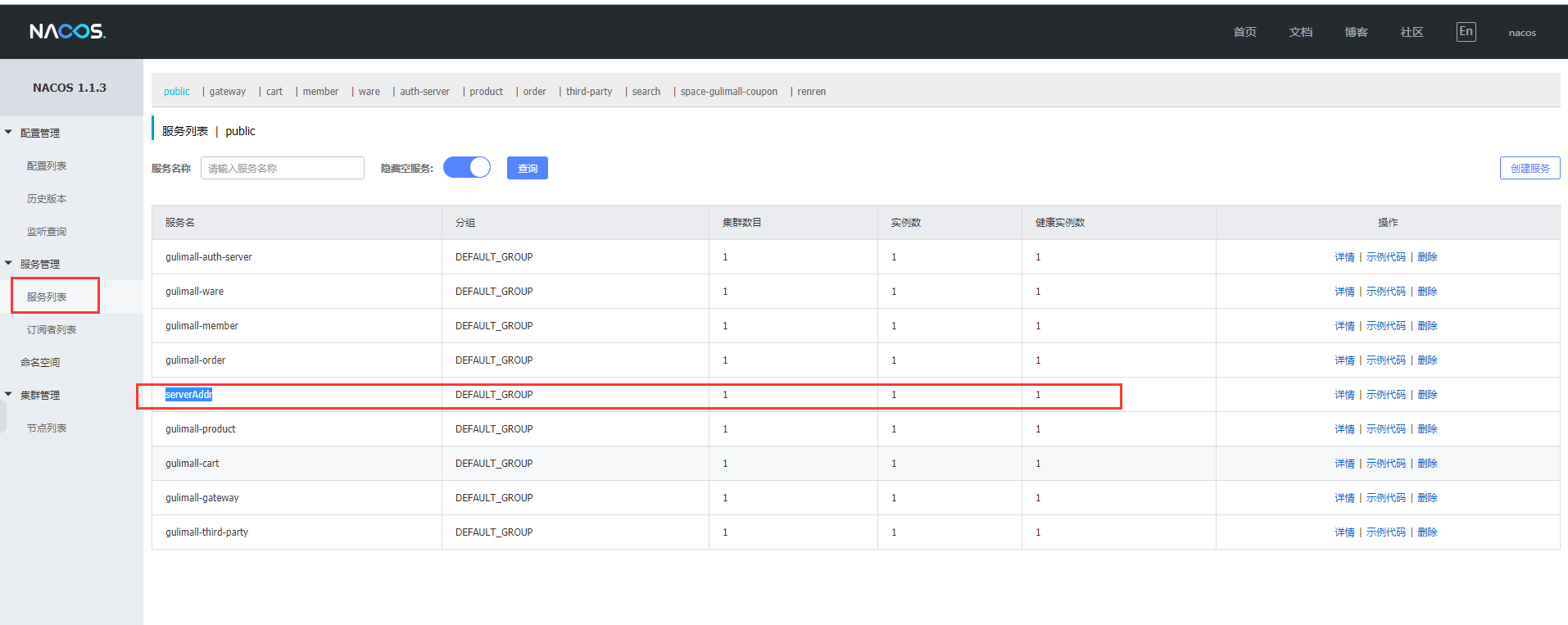
在nacos中查看 名称为:serverAddr
3.3)所有想要用到分布式事务的微服务使用seata DataSourceProxy 代理自己的数据源
@Configuration
public class MySeataConfig {
@Autowired
DataSourceProperties dataSourceProperties;
@Bean
public DataSource dataSource(DataSourceProperties dataSourceProperties) {
// 原来得数据源
HikariDataSource dataSource = dataSourceProperties.initializeDataSourceBuilder().type(HikariDataSource.class).build();
if (StringUtils.hasText(dataSourceProperties.getName())) {
dataSource.setPoolName(dataSourceProperties.getName());
}
// 我们包装后得数据源
return new DataSourceProxy(dataSource);
}
}
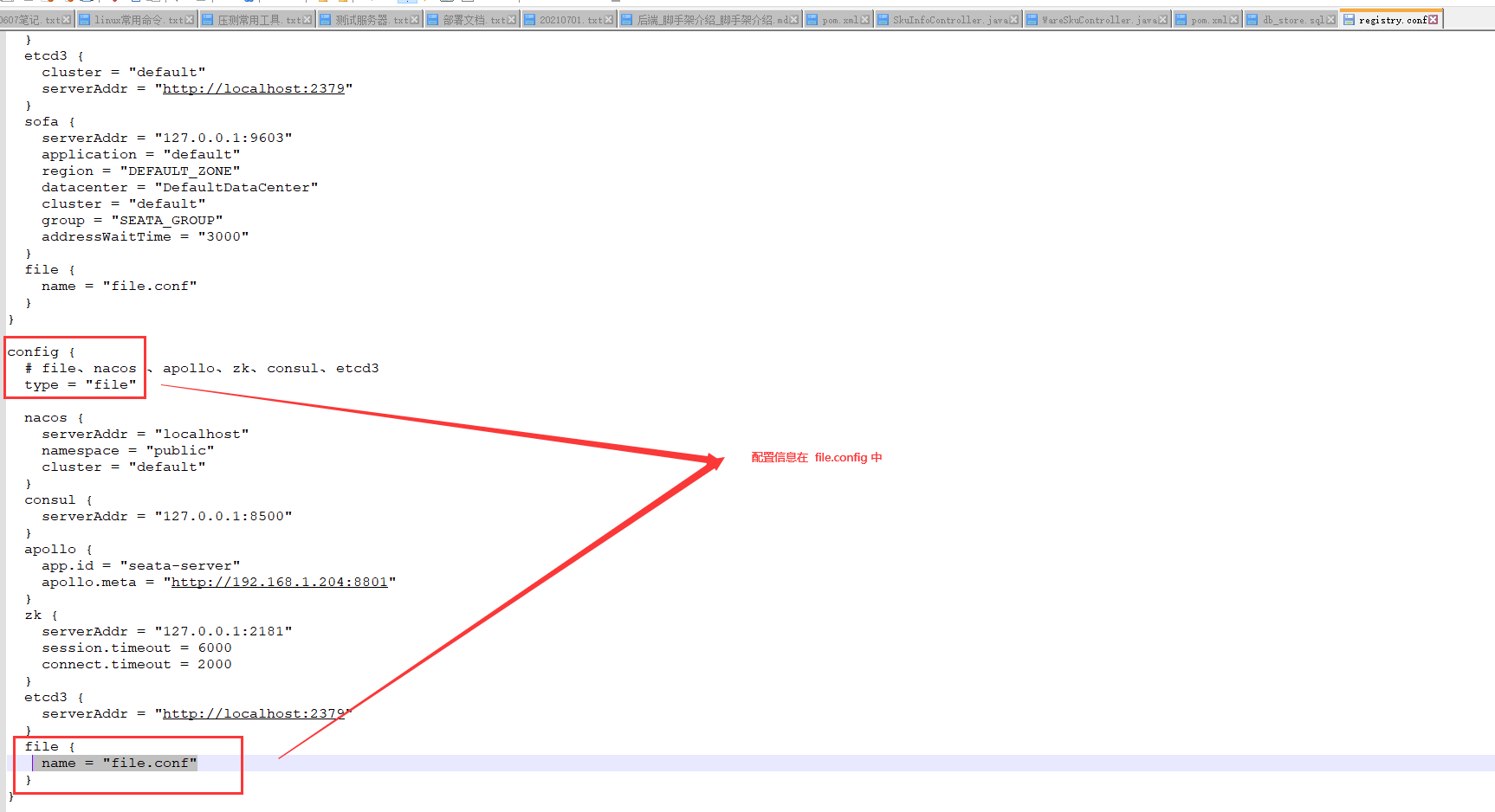
3.4)每个微服务,都必须导入 registry.conf file.conf vgroup_mapping.{application.name}-fescar-server-group = "default"
第一步:添加两个文件
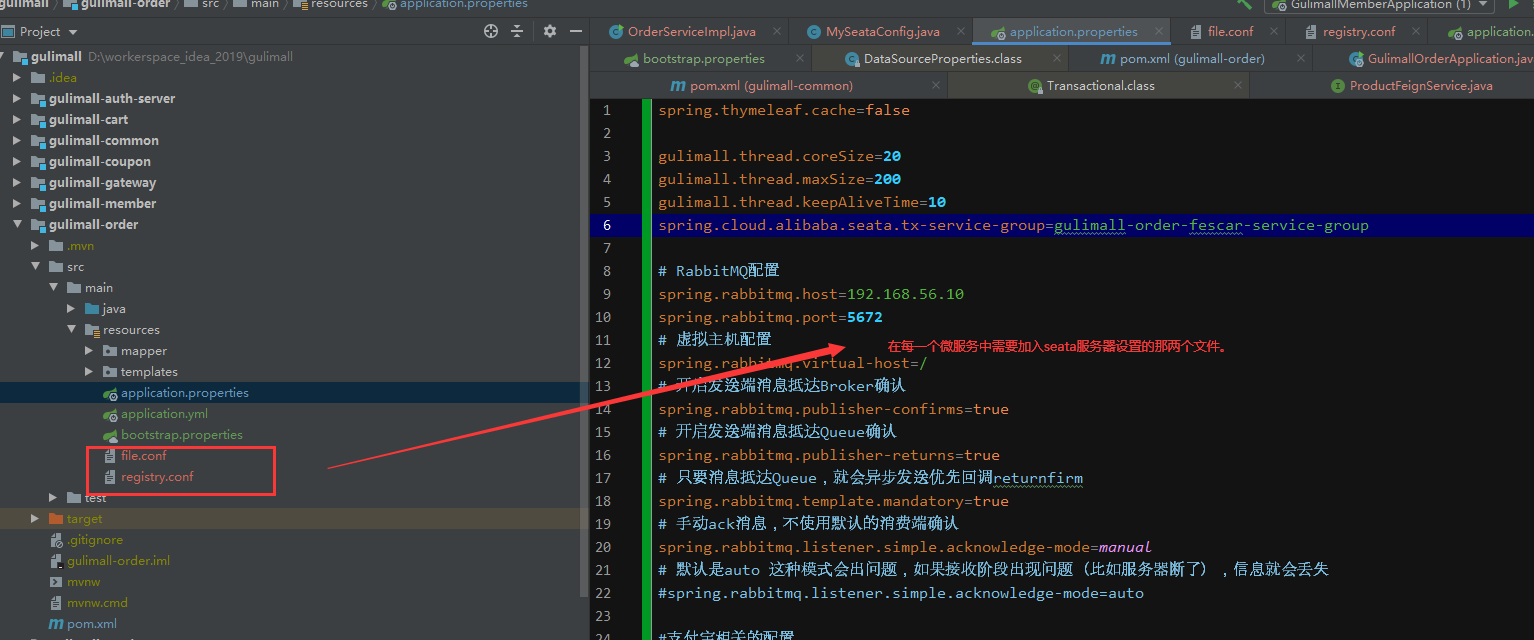
第二步:修改 file.conf 中的vgroup_mapping
第三步:添加配置 ,第二步和第三步完成一个就可以。
3.5)启动测试分布式事务
3.6)给分布式大事务的入口标注@GlobalTransactional
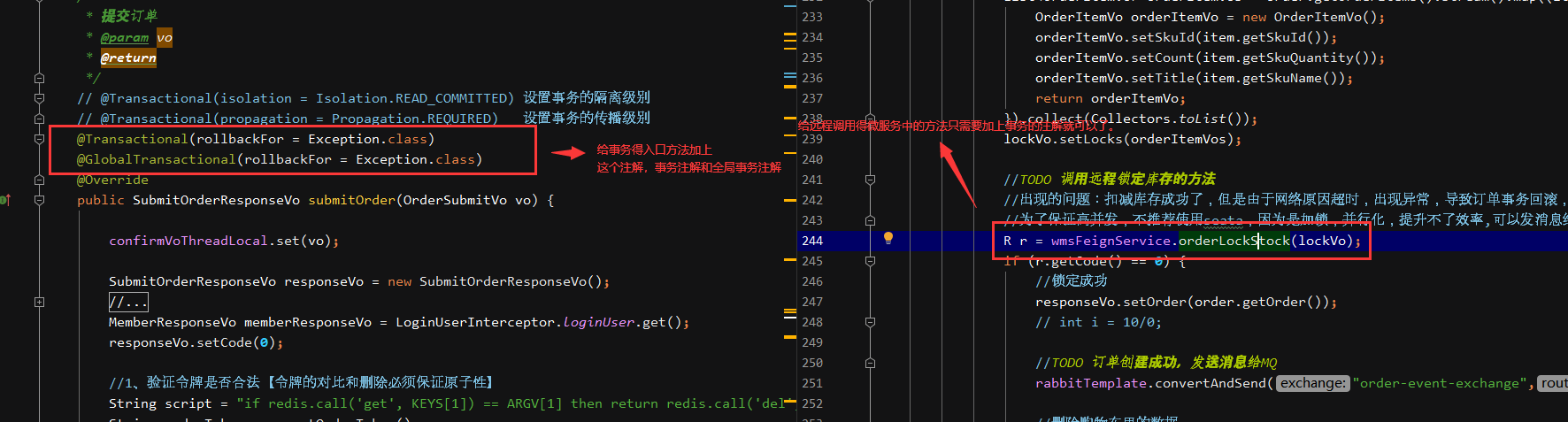
3.7)每一个远程的小事务用@Trabsactional
五、使用mq的延时队列实现,适合于高并发环境
这种方式是:柔性事务-可靠消息+最终一致性方案(异步确保型)
最重要的是要做到防止消息丢失。
防止消息丢失:
/**
- 1、做好消息确认机制(pulisher,consumer【手动 ack】)
- 2、每一个发送的消息都在数据库做好记录。定期将失败的消息再次发送一
遍
*/
最后
以上就是怕孤单小丸子最近收集整理的关于本地事务与分布式事务的全部内容,更多相关本地事务与分布式事务内容请搜索靠谱客的其他文章。








发表评论 取消回复