在Unity中实现音口同步-01-概述
在Unity中实现音口同步-02-Salsa
在Unity中实现音口同步-03-OneClick
嫌长的话可以看这个:
- 制作一个带有BlendShapes面部动画的模型,导入unity
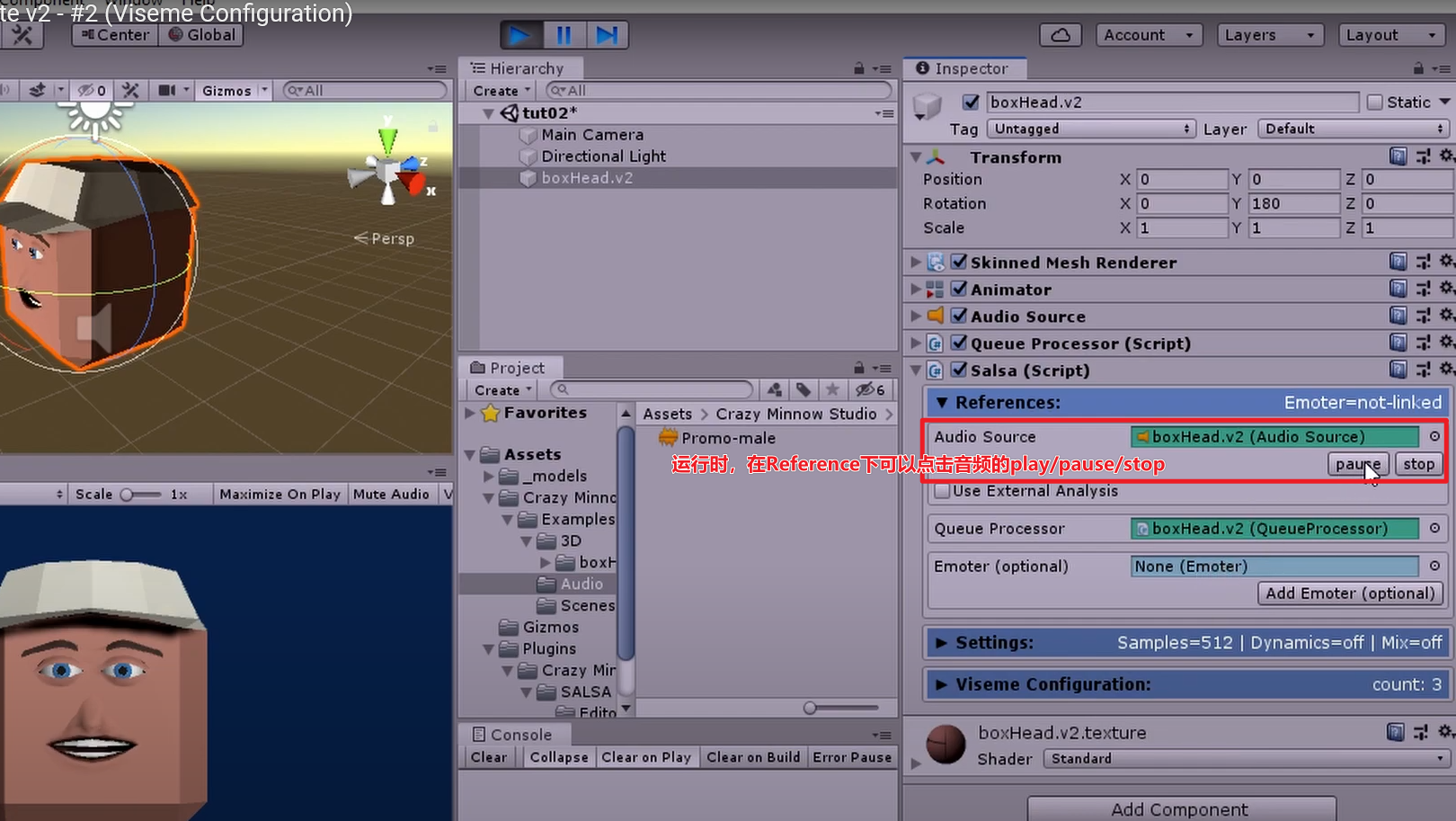
- 添加Salsa脚本,蓝色背景框表示配置OK,黄色则表示需要配置
- 在References中,我们点击【AddAudioSource】【AddQueueProcessor】的按钮即可自动挂载脚本。
- 在viseme下配置3个口型变化(saySmall、sayMedium、sayLarge),然后勾选TriggerDisplayMode,点击Curve。
- 如果使用录好的音频作为音源,则在AudioSource脚本上加载audio-clip,点击运行人物可以张嘴说话啦
- 如果想使用麦克风作为音源,则前往插件官网下载MicInput资源包,导入后即可添加SalsaMicInput.cs脚本,并且在面板里勾选【muteMicrophone】【overrideRate】【LinkWithSalsa】(勾选最后一项的时候面板会自动添加一个MicPointerSync.cs的脚本)
- 如果想实现眨眼动画,需要使用Emoter脚本
正文
- 制作一个带有BlendShapes的模型,导入unity
***如果你使用的模型属于Autodesk Character Generator (ACG)/DAZ 3D/Mixamo Fuse/Reallusion CC3 & iClone/UMA
DCS,那么你可以下载安装对应的OneClick,跳过本文,点击GameObject下的OneClick一键配置Salsa、EmoteR、Eyes脚本——详见官方youtube教程第4节,或者
- 添加Salsa脚本(挂空物体或者模型都行),蓝色背景框表示配置OK,黄色则表示需要配置
- 在References中,我们点击【AddAudioSource】【AddQueueProcessor】的按钮即可自动挂载脚本。
- 在viseme下配置3个口型变化(saySmall、sayMedium、sayLarge),然后勾选TriggerDisplayMode,有曲线和线性两种自动插值(到时候看哪个效果好选哪个,推荐Curve)。(作用是划分不同口型的区间大小,比如DataAnalysis根据音频给出的一个数值,如果落在saySmall的Trigger区间,就播放saySmall的动画)
Salsa-Viseme参数详解:
Viseme,意为“可视音素”,在由语音驱动的头部动画中,对应一个音位的口型。
- 【Animation Timings】
on=How quickly in seconds the full-on animation occurs
off=How long in seconds the full-off animation occurs
on参数需和Settings-UpdateDelay参数协同 - 【Disable smoothly?】
如果你在代码里关闭动画,动画会立即停止,而勾上smoothly可以让动画以off timing的方式结束 - 【Easing】
其中CubicOut是a quick start and a slow finish
Salsa-Settings参数详解:
- 【DataAnalysis】
-
- Samples=512意味着每次DataAnalysis采样512个数据
-
- Update Delay=0.08意味着每0.08秒从音频中采样一段数据做DataAnalysis
如果Update Delay偏大,那么会丢失音频的细节;如果它比下面的on参数小,那么viseme动画就来不及播放至最大值。没有固定的标准值,根据你需要的效果来调整参数。
- Update Delay=0.08意味着每0.08秒从音频中采样一段数据做DataAnalysis
-
- DataAnalysis会给出一个数值,根据这个数值触发对应Trigger区间的viseme动画。
-
- 如果是播放固有的音频,Playhead Bias意味着程序会提前采样还未播放的数据,使得嘴唇在声音播放前动起来
- 如果使用麦克风,你可以用
【Dynamics】 -
- LinearScaledCutoffs——根据DataAnalysis给出的数值,把小于下限的值过滤掉,把大于上限的值归为1,然后对上下限区间内的数值映射到0~1区间——设置下限的目的在于排除噪声,设置上限的目的在于重新定义音源的波动大小,比如对于一段高品质的音频,波峰波谷明确,那么上限设为1没有问题,但如果音频音量较轻或者你使用麦克风,那么应该降低上限,使得trigger值偏大的viseme也能经常被触发
-
- Global Dynamics——调整所有的viseme变形程度 ,适用于嘟哝/说悄悄话的样子
-
- Advanced Dynamics——勾选这一项意味着不会出现停滞不动的viseme(尤其是在只有3个口型变化时很容易出现达到最大值而停滞 的口型),程序会根据DataAnalysis给出的值在0~1之间给出viseme的最大值,但一般来说我们不希望出现0,所以给定PrimaryBias作为下限确保viseme动画播放的最小量
-
- Apply Jitter——适用于唱歌连续发一个声音时嘴唇微微抖动的样子
-
- Use Secondary Mix——程序会按百分比混合当前viseme和它下面的一个viseme
-
- Use Rollback——适用于2D
Salsa-References参数详解:
- 【AudioSource-Using External Analysis】使用text-to-lipsync和dissonance插件时会用到
- 【Emoter】超过EmphasisTrigger阈值,就有概率触发Emoter脚本(超过EmphasisTrigger越多/Emphasis Chance越大,触发概率就越大),然后Emoter脚本会随机选择一个表情播放
- 添加Emoter脚本
Emoter可以单独使用,也可关联Salsa获得基于音频的时机(在Salsa-References中,点击【AddEmoter】即可添加Emoter脚本)。
你可以在EmoteConfiguration里组合制作丰富的表情,表情称为emote
Emoter-Settings参数详解:
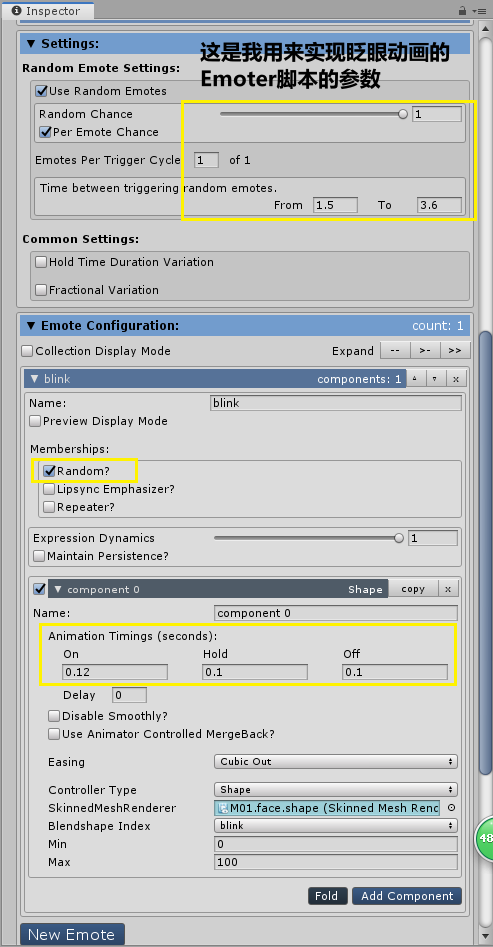
【Hold Time Duration Variation】它会重写每个emote的hold-time,使emote每次持续的时间具有波动
【Fractional Variation】使emote的大小具有波动(而非每次都达到max),比如本来眨眼的动作如果勾上Fractional Variation就会变成眼睛只闭一半而合不上了~
Emoter-References参数详解:
一个角色一个Queue Processor,Salsa>Emoter>Eyes脚本都关联同一个Queue Processor
Emote参数详解:
有点懒写不动了……上面都是看教程记的笔记
放一张我用来实现人物眨眼动画的Emoter参数:
Tip:
1.一个viseme里可以有多个component,这意味着你可以组合blendshape做出组合表情
2.运行时,在Reference下可以点击音频的play/pause/stop
3.每次手动配置还挺烦的,所以可以自己写一个oneclick脚本实现一键配置
最后
以上就是安静信封最近收集整理的关于在Unity中实现音口同步-02-Salsa的全部内容,更多相关在Unity中实现音口同步-02-Salsa内容请搜索靠谱客的其他文章。








发表评论 取消回复