- 任务描述
- 行标签和单元格标签
- find_all函数
- 获取标签文本
- 编程要求
任务描述
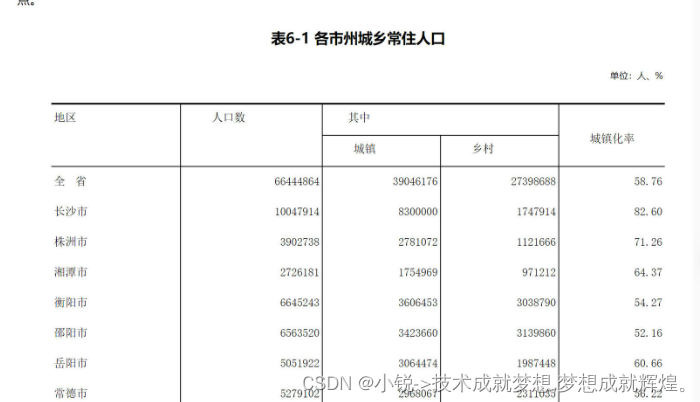
本关任务: 本关任务:根据上个步骤中爬取的表格标签,将表格中从第四行的单元格的文本显示出来
行标签和单元格标签
表格中每行的数据信息被封装在一个<tr></tr>之间的结构中。 每列内容采用<td></td>表示。 因此,如果要获得其中的数据,需要首先找到标签,并遍历其中每个标签,获取其值 例如,表格的第四行对应的html代码如下
find_all函数
通过BeautifulSoup的find_all(name)方法,可以找到多个标签,将多个标签的内容返回为一个列表 lb=bg.find_all("tr") 找到表格的所有tr标签,存入列表lb 若需要找每行下的所有td标签,则需要对lb循环,对每个元素执行find_all("td")
获取标签文本
在用find()方法找到特定的标签后,想获取里面的文本,可以用.text属性或者.string属性。 如果该标签下有多层次的子标签,则必须使用text属性。 对于该网页的td标签,如上图所示,需要用text才能返回文本。并且需要用strip去掉换行符。 如果使用最内层的span标签,则可以使用string属性。
编程要求
对于上述获得的表格标签的内容,爬取从第4行开始的文本, 显示每行的地区名称、总人口、城镇人口、乡村人口和城镇化率 各项之间用空格隔开,包括最后一列后面也有空格 每个地区换一行
# 这是一个请求库
import requests
# 将请求到的内容进行解析
from bs4 import BeautifulSoup
# 这是网址
url = "http://tjj.hunan.gov.cn/hntj/tjfx/tjgb/rkpc/
202105/t20210519_19079329.html"
# 调用请求库进行网页的请求,获取网页的内容
r=requests.get(url)
# 请求的时候防止乱码的发生,一般是utf-8还有一个是b123啥的,忘了,utf-8比较常见。
r.encoding = 'utf-8'
# 对获取到的内容进行解析,用的是text是获取其内容,至于html.parser
是BeautifulSoup的参数的用法,不加上会报错,详细知道BeautifulSoup请查阅相关信息。
soup=BeautifulSoup(r.text,"html.parser")
# 获取文本中的table标签的内容
bg=soup.find('table')
#代码开始
# 导入正则表达式的库
import re
# 在table中获取tr的内容
lb = bg.find_all('tr')
# 定义两个列表,后面用于存储
a = []
b = []
# 其实个人觉得下面的代码有点多余了,当时自己也是按照自己的想法去做的,就没有进行改了,
其实完全可以在lb的基础上进行lb=lb[3:]的操作,为什么会有这一步,因为题目要求是从长沙市开始的,
长沙市在第四行因此需要这么做,如果不太了解的同学可以自行查看lb的结构,就知道答案了。
for i in lb:
a.append(i.find_all('td'))
a = a[3:]
# 这两句是本人的简单测试,可忽视
# print(len(a[0]))
# print(a[0][0])
'''
核心代码讲解部分:
for k, i in enumerate(a):
在这条语句中,k会记住坐标,而i会记住对应的内容,就好像['i lov you','but you do not love me']
;在这个列表中,k分别取值为0,1;i就会分别对应那两句英文;的确,你真的不喜欢我,哈哈哈。
result = re.match(r'.*宋体">(.*?)<',str(j),re.S)
在这条语句中,是使用的正则表达式;re.match(1,2,3);在1的位置为正则表达式提取的要求,
2的位置是匹配的句子,3为满足.*?不能进行换行而存在的需求;注意.*?和.*的用法,
一个是非贪婪匹配一个是贪婪匹配,详解可以去查一下资料。在这里面会返回()中的内容;
如果要提取的要求很多的话,就要多个括号,group(1)是返回第一个括号,
注意这里是从1开始的,而不是0.
'''
for k,i in enumerate(a):
b.append([])
for j in i:
result = re.match(r'.*宋体">(.*?)<', str(j),re.S)
b[k].append(result.group(1))
# 对b中的内容进行提取,其实只是为了满足题目要求罢了,否则完全可以进行pd.DataFrame操作,
直接转为我们要的csv或者excel文件了
for i in b:
for j in i:
print(j,end=' ')
print()
#代码结束期间遇到的错误:
在re.match中报错:
'NoneType' object has no attribute 'group'
运行直接报错,也就是说正则表达式没有匹配到这个字符串,返回结果为None,而我们又调用了group()方法导致了AttributeError。为什么加入一个换行符就匹配不到了,是因为.*?遇到换行符就无法匹配了,因此在这里我们需要加上一个re.S,这个修饰符的作用是使.匹配包括换行符在内的所有字符,re.S在网页匹配中经常用到,因为HTML节点经常会换行,加上它,就可以匹配节点之间的换行l.
最后
以上就是淡定铅笔最近收集整理的关于第2关:爬取表格中指定单元格的信息的全部内容,更多相关第2关:爬取表格中指定单元格内容请搜索靠谱客的其他文章。








发表评论 取消回复