本爬虫源于女朋友要考时事政治,要我帮她整理中公教育的时事政治内容,因本人最近对爬虫有了初步(一点点)的了解,为了免去机械复制粘贴时间,做了一个低端爬虫,通过本次爬虫,对python基础内容也深入了解了下,程序难免有复杂之处,还望各位大神批评指正。
在开始编写代码时,我选择编译工具为Anaconda中的Spyder,奈何写了几句代码后发现程序自动补全功能需要按TAB键才会有提示,从博客上找资料也没调出自动弹出补全程序的功能,为此选择了Pycharm,这个软件真心占内存,我的垃圾电脑开了老长时间才打开它。废话不多说,上内容。
本代码主要用到两个函数,一个来爬网址,一个爬内容
步骤如下:
1. 目标网址分析
- 中公教育时事政治网址分析
网址主页 http://www.offcn.com/shizheng/sshz/
- 因为资料众多,网页有分页,对其第二、三、四页网址进行分析:
http://www.offcn.com/shizheng/sshz/2.html
http://www.offcn.com/shizheng/sshz/3.html
http://www.offcn.com/shizheng/sshz/3.html
发现网页规律在网页最后的数字上,除了第一页的网址不具有数字,为此选择使用格式化输出,将要爬取的前7页网址写入一个列表urls中,代码如下:
start_url = 'http://www.offcn.com/shizheng/sshz/'
urls = ['http://www.offcn.com/shizheng/sshz/{}.html'.format(i) for i in range(2,8,1)]
urls.insert(0, start_url)2. 分析每一页的网页结构,对每一个月的时事政治的文档链接进行提取
- 博主使用谷歌浏览器,对网页检查后得到下图
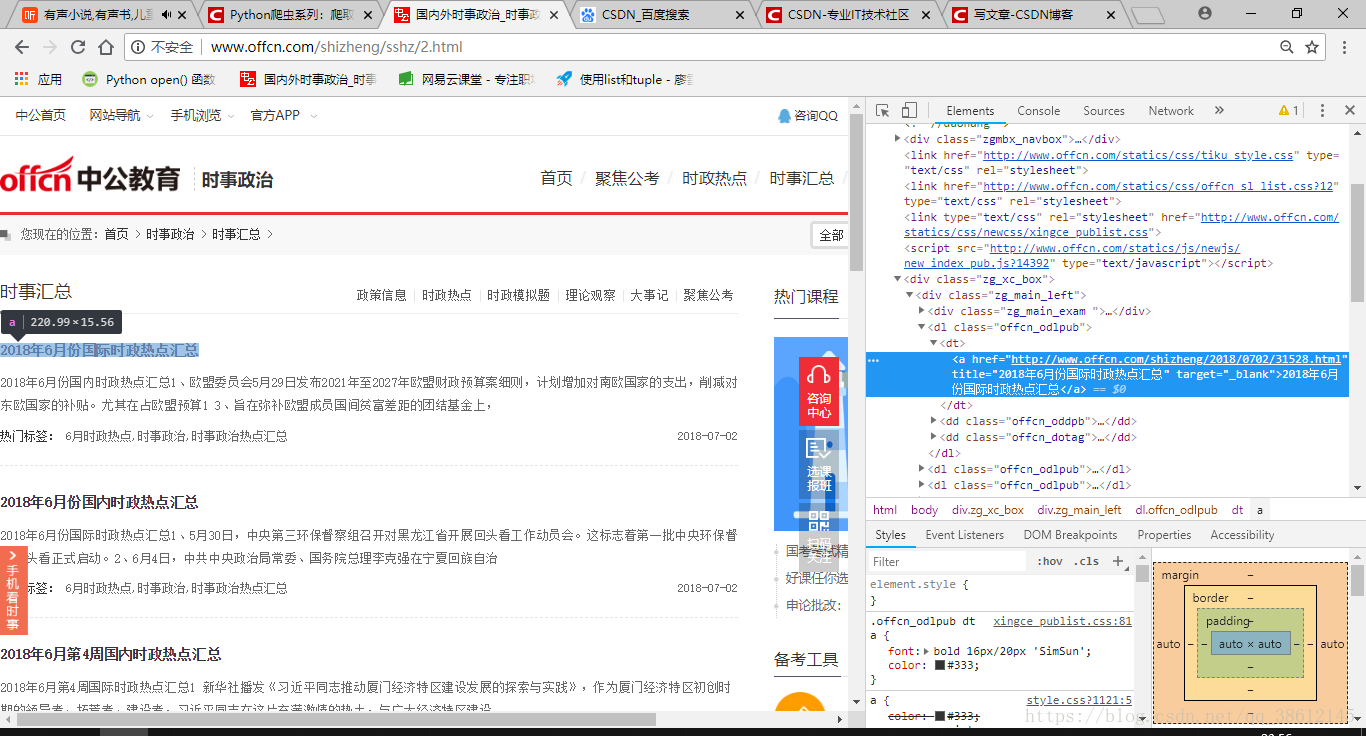
可以看出,每一个月时事内容的网址在body > div.zg_xc_box > div.zg_main_left > dl:nth-child(2) > dt > a中,为此,可以获取每月时事内容的链接地址,所写函数如下:
# 获取目标网址下所有资料链接
def get_urls(single_url):
wb_data = requests.get(single_url)
wb_data.encoding = 'gb2312'
soup = BeautifulSoup(wb_data.text, 'lxml')
infos = soup.select('div.zg_main_left > dl > dt > a')
time.sleep(4)
for info in infos:
data_url = info.get("href")
time.sleep(4)
get_data(data_url) #获取文本信息函数3.获取页面内的文本信息并存入txt文档中
- 对单独的页面内容进行检查后得到
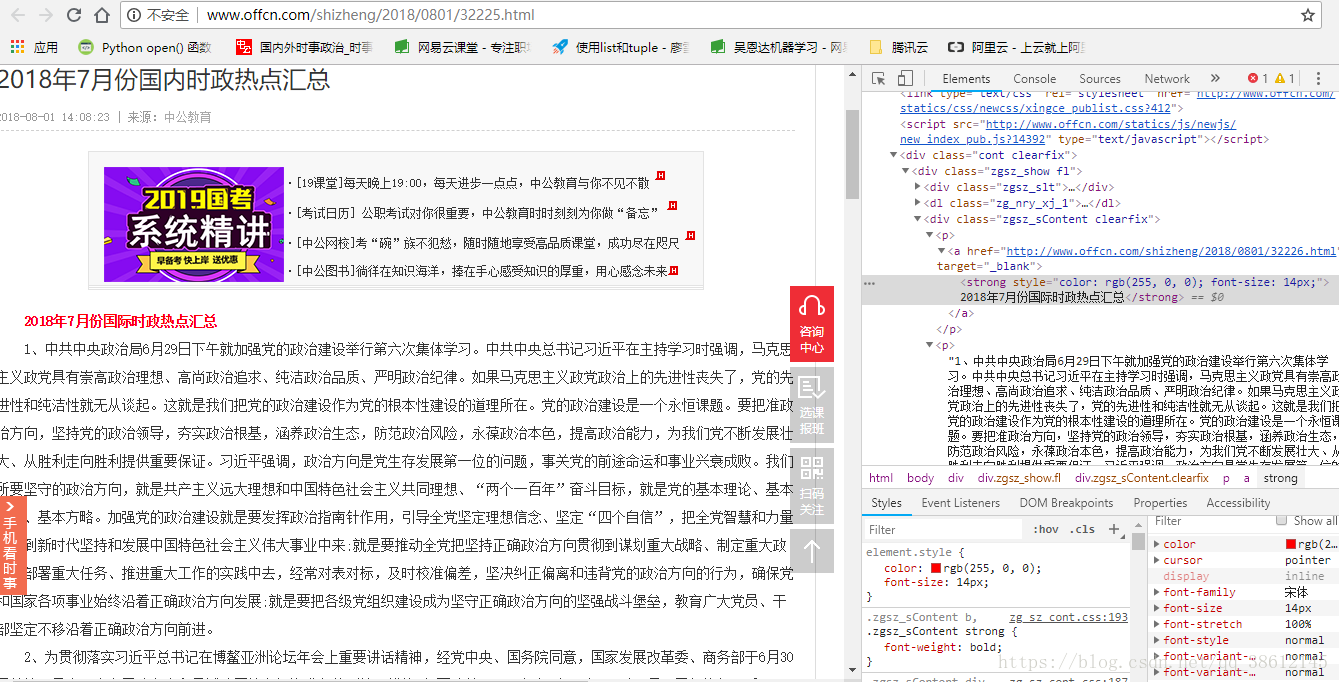
根据copy -> selector ,可以看出,标题内容在body > div.cont.clearfix > div.zgsz_show.fl > div.zgsz_slt > h1;文本内容在body > div.cont.clearfix > div.zgsz_show.fl > div.zgsz_sContent.clearfix > p,为此编写如下函数,将标题和文本内容写入txt文档中
def get_data(data_url):
wb1_data = requests.get(data_url)
wb1_data.encoding = 'gb2312'
soup = BeautifulSoup(wb1_data.text, 'lxml')
title = soup.select('div.cont.clearfix > div.zgsz_show.fl > div.zgsz_slt > h1')[0].get_text()
f.write('n'+ title + 'n') #写入f文档中
passages = soup.select('div.cont.clearfix > div.zgsz_show.fl > div.zgsz_sContent.clearfix > p')
passages.pop(0) #删除列表中第一个元素
for paragraph in passages:
data = paragraph.get_text()
if len(data) > 30: #有些内容为广告,默认大于30字符时为文本内容
f.write(data + 'n')
#判断文本内容有没有第二页,有的话把第二页网址提取出来,并进入进行内容提取
if soup.find_all("div", class_="zg_page list_pagebox"):
another_url = soup.select('div.zg_page.list_pagebox > p > a')[1].get("href")
wb2_data = requests.get(another_url)
wb2_data.encoding = 'gb2312'
soup = BeautifulSoup(wb2_data.text, 'lxml')
passage1 = soup.select('div.cont.clearfix > div.zgsz_show.fl > div.zgsz_sContent.clearfix > p')
passage1.pop(0)
for paragraph1 in passage1:
data1 = paragraph1.get_text()
if len(data1) > 30:
f.write(data1 + 'n')4.思路梳理
1.获取主网站内容
2.分析网站每一页的组成
3.编写爬虫对要求页数内的文本链接进行爬取
4.进入文本链接中对网页组成分析
5.编写爬虫爬取文本内容,对爬取中出现的广告等进行屏蔽,考虑文本内容有多页的问题
6.将内容写入txt文档中,本内容参看了[廖雪峰的IO编程一节](https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/001431917715991ef1ebc19d15a4afdace1169a464eecc2000)
整体代码如下:
#!/usr/bin/env python
# -*- coding:gbk -*-
from bs4 import BeautifulSoup
import requests
import time
def get_data(data_url):
wb1_data = requests.get(data_url)
wb1_data.encoding = 'gb2312'
soup = BeautifulSoup(wb1_data.text, 'lxml')
title = soup.select('div.cont.clearfix > div.zgsz_show.fl > div.zgsz_slt > h1')[0].get_text()
f.write('n'+ title + 'n')
passages = soup.select('div.cont.clearfix > div.zgsz_show.fl > div.zgsz_sContent.clearfix > p')
passages.pop(0)
for paragraph in passages:
data = paragraph.get_text()
if len(data) > 30:
f.write(data + 'n')
if soup.find_all("div", class_="zg_page list_pagebox"):
another_url = soup.select('div.zg_page.list_pagebox > p > a')[1].get("href")
wb2_data = requests.get(another_url)
wb2_data.encoding = 'gb2312'
soup = BeautifulSoup(wb2_data.text, 'lxml')
passage1 = soup.select('div.cont.clearfix > div.zgsz_show.fl > div.zgsz_sContent.clearfix > p')
passage1.pop(0)
for paragraph1 in passage1:
data1 = paragraph1.get_text()
if len(data1) > 30:
f.write(data1 + 'n')
# 获取目标网址下所有资料链接
def get_urls(single_url):
wb_data = requests.get(single_url)
wb_data.encoding = 'gb2312'
soup = BeautifulSoup(wb_data.text, 'lxml')
infos = soup.select('div.zg_main_left > dl > dt > a')
time.sleep(4)
for info in infos:
data_url = info.get("href")
time.sleep(4)
get_data(data_url)
# 将目标网址写入一个list中
start_url = 'http://www.offcn.com/shizheng/sshz/'
urls = ['http://www.offcn.com/shizheng/sshz/{}.html'.format(i) for i in range(2,8,1)]
urls.insert(0, start_url)
with open('C:/Users/lenovo/Desktop/222.txt', 'w', encoding='gb18030') as f:
for url in urls:
get_urls(url)最终获取到了中公教育时事政治的汇总,省去自己复制粘贴的烦恼。
最后
以上就是欢喜香烟最近收集整理的关于爬虫(三)——时事政治内容爬取并存入txt文档步骤如下:的全部内容,更多相关爬虫(三)——时事政治内容爬取并存入txt文档步骤如下内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复