世界疫情的数据很多网站都有,这里我还是使用手机网易的疫情数据接口。
首先,切换ua,换成手机模式。百度搜索“网易 疫情”,
第一个就是。
打开这个网址,点开开发者工具,刷新一下。就可以看到有这么几个,第一个请求,就是数据
但是这里我们要用的是世界疫情。所以,还得往下多看几眼。
这第一个请求里,会给你今天的世界疫情数据。但是我们想绘制的是随着时间变化,增长的数据竞赛柱状图。只有一天是不行的。
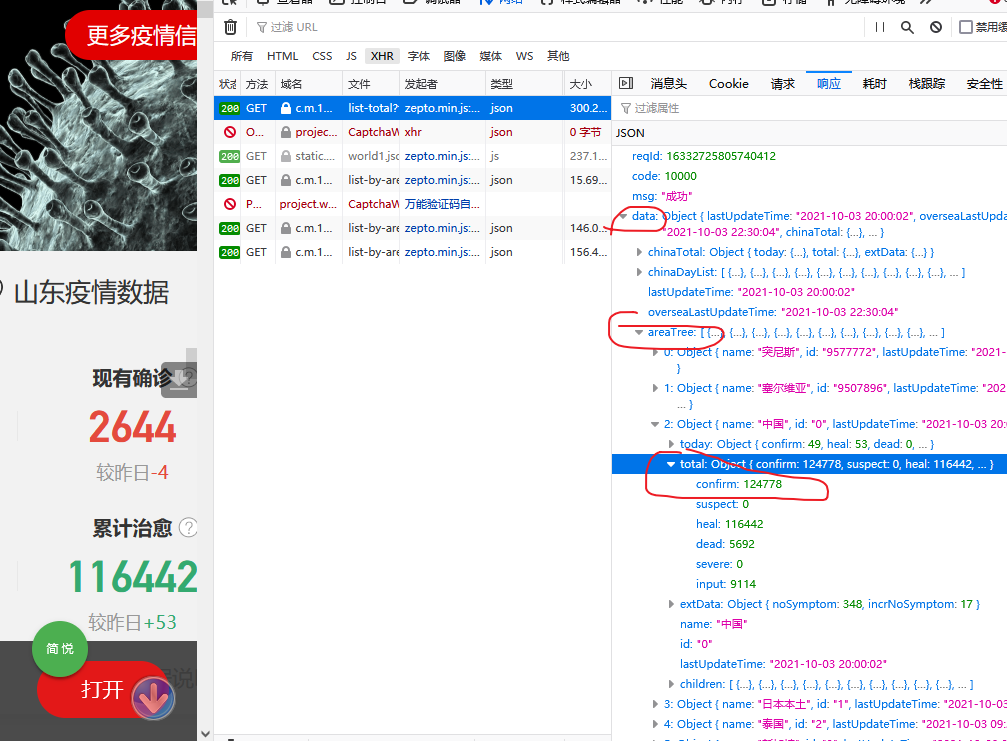
但是,这里有一个游泳的数据是,areaTree下面,每一个国家的id都有了。
后面用数据的请求接口,需要用到这个id。这里我就选7个国家,每个单独记下来就行,也没必要用request提取。
当然了,这里我也是用的python。毕竟第一次也不知道这几个国家的id。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import re
import os
import time
import requests
plt.rcParams["font.family"] = "SimHei"
wk_dir = "数据分析"
data_dir = "数据分析/data"
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 11) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.120 Mobile Safari/537.36',
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Origin': 'https://wp.m.163.com',
'Connection': 'keep-alive',
'Referer': 'https://wp.m.163.com/',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-site',
'TE': 'trailers',
}
params = (
('t', '326632088930'),
)
response = requests.get('https://c.m.163.com/ug/api/wuhan/app/data/list-total', headers=headers, params=params)
#NB. Original query string below. It seems impossible to parse and
#reproduce query strings 100% accurately so the one below is given
#in case the reproduced version is not "correct".
# response = requests.get('https://c.m.163.com/ug/api/wuhan/app/data/list-total?t=326632088930', headers=headers)
rj = response.json()
rj.keys()
data = rj['data']
data.keys()
areaTree = data['areaTree']
countryCode = [ x['id'] for x in areaTree]
countryName = [ x['name'] for x in areaTree]
dct_country_id = dict(zip(countryName, countryCode))
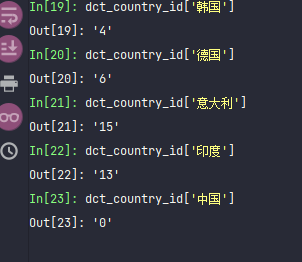
dct_country_id['美国']这里的代码,params,里面只有一个t, 这个t刚开始我以为是时间,但是也不知道这个是怎么构造的。反正就用这个,后面请求历史数据的时候,这个t也不需要改,没啥影响。
返回json格式的,我就依次提取 json数据里的 data→areaTree→各国的id
做成一个字典,这样通过字典就可以查询“美国”返回7,中国是0.
然后点击“世界疫情”
出现,各个国家的数据。
美国后面有“详情”,点击一下,看看这个请求时什么结构,
第二个请求,他的数据就是美国的数据,
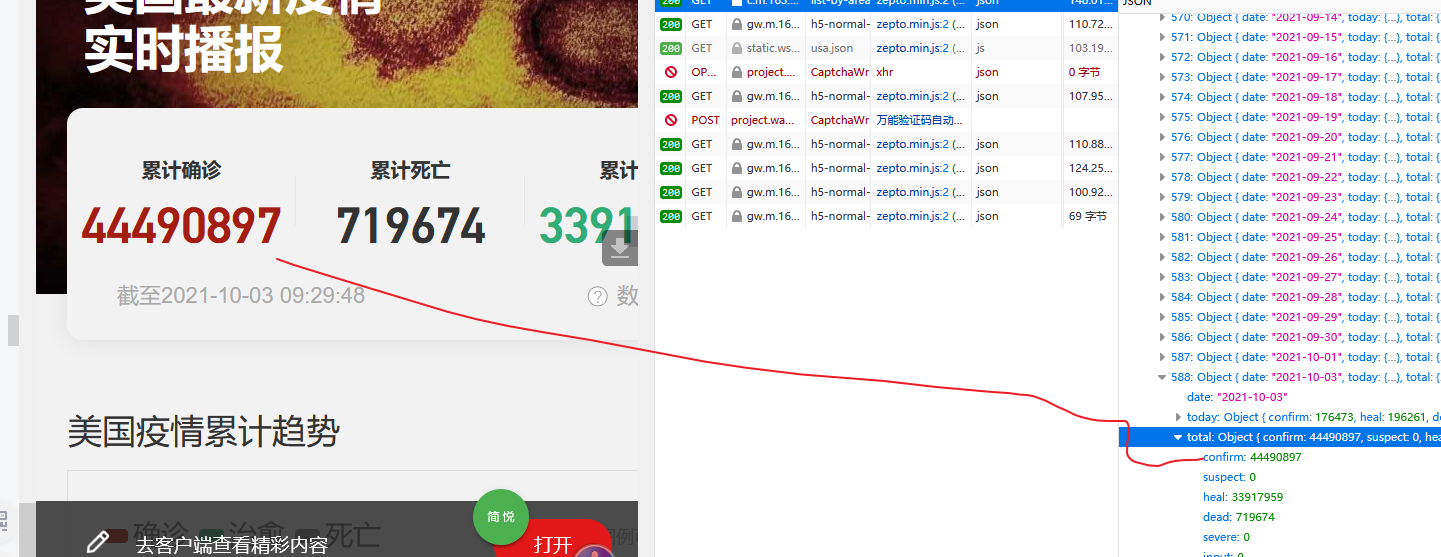
我们看请求头。
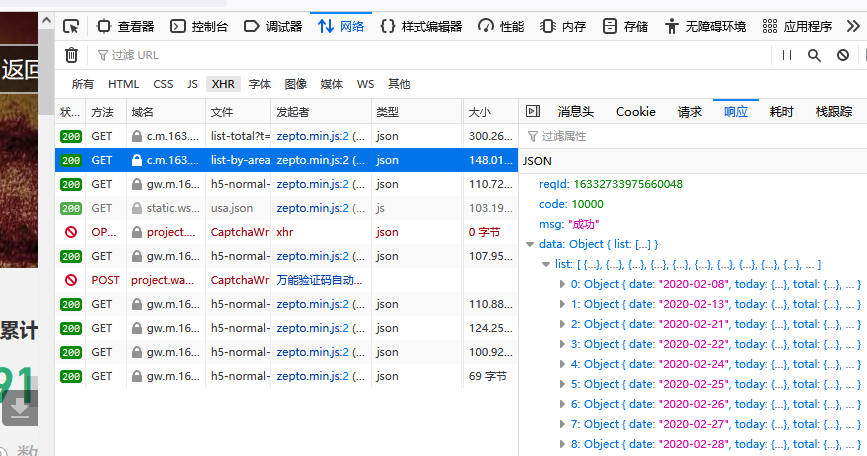
数据最后一行是今天的美国人数。

这个请求头,是这个url
https://c.m.163.com/ug/api/wuhan/app/data/list-by-area-code?areaCode=7&t=1633273396571
直接复制这个网址,到浏览器,可以看出,它就能返回给我们美国的数据。
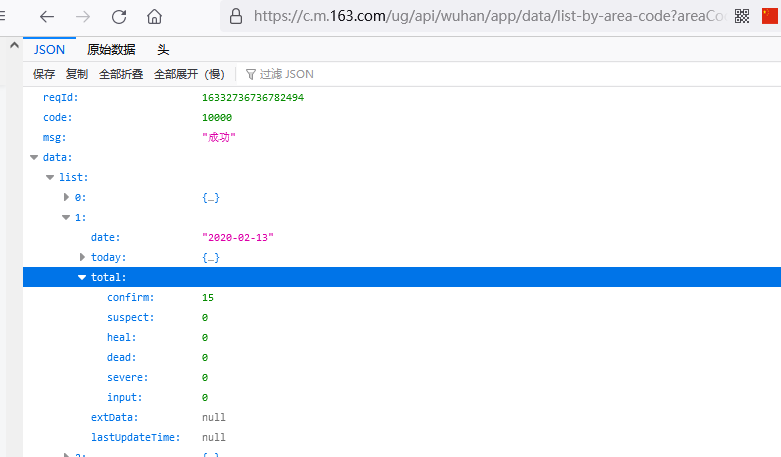
所以规律就是,替换掉 areaCode的数字,我们分别用几个国家的id,替换,轮番请求。就可以得到一个世界各国的疫情历史数据。
need_countries = ['中国', '美国', '英国', '伊朗', '西班牙', '韩国', '德国', '意大利', '印度']
need_countries
dct_allData = {}
for country in need_countries:
country_id = dct_country_id[country]
print(country, "*"*20, country_id)
url = f"https://c.m.163.com/ug/api/wuhan/app/data/list-by-area-code?areaCode={country_id}&t=1633160447810"
print(url)
try:
response = requests.get(url, headers = headers)
time.sleep(3)
rj = response.json()
dct_allData[country] = rj['data']
print("success")
except:
print("failed")
country_id
url
dct_allData
dct_allData.keys()这样就得到了9个国家的数据了。
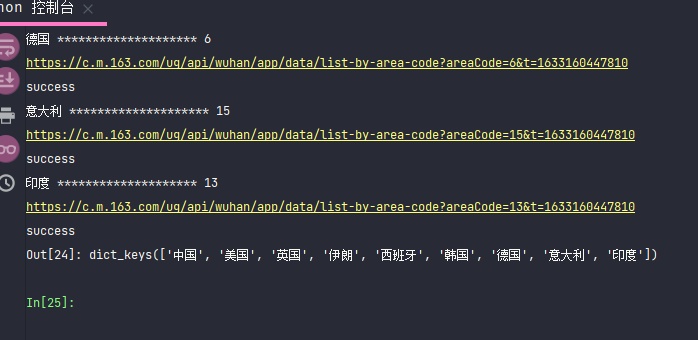
比如,美国的,都在字典 allData里
usa = dct_allData['美国']
usa['list']
list = usa['list']
len(list)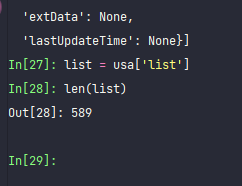
先保存一下数据。
pd.to_pickle(dct_allData, os.path.join(data_dir, "allData疫情数据"))
后面在操作这个数据就可以了。
不需要爬虫了。
这里我们只需要两个数据就可以了。
就是
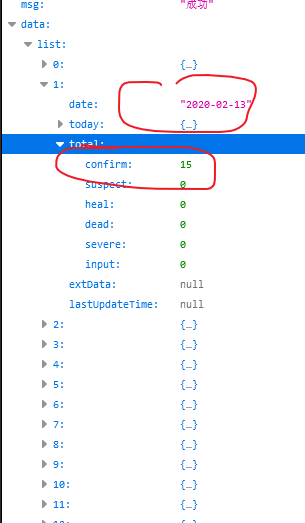
date和confirm
其他都不需要。
dct_confirm = {}
for c in dct_allData.keys():
confirm = [ x['total']['confirm'] for x in dct_allData[c]['list'] ]
dct_confirm[c] = confirm
dct_confirm.keys()
len(dct_confirm['美国'])
len(dct_confirm['印度'])
每一个国家的数据,都可以做成一个dataframe
china_list = china['list']
china_date = [ x['date'] for x in china_list]
china_confirm = [ x['total']['confirm'] for x in china_list]
df_china = pd.DataFrame({
'date':china_date,
'confirm':china_confirm
})
df_china这里要注意的是,不同国家,有的时间没有数据。date不是同样的。数据也不等长。
f_china.shape
usa_list = usa['list']
usa_date = [ x['date'] for x in usa_list]
usa_confirm = [ x['total']['confirm'] for x in usa_list]
df_usa = pd.DataFrame({
'date':usa_date,
'confirm':usa_confirm
})
df_usa.shape
可以看出,中国有604个date有数据,美国只有589个。
这样在合并成一个大表的时候,就需要注意日期,有的是缺失值。
def get_data(key):
len_key = len(df[key]['list'])
print(len_key)
data = []
date = []
for i in range(len_key):
d = df[key]['list'][i]['total']['confirm']
data.append(d)
dt = df[key]['list'][i]['date']
date.append(dt)
return dict(zip(date, data))
dct_data = {}
for key in df.keys():
dct_data[key] = get_data(key)
dct_data.keys()
pd.DataFrame(dct_data)这里我们定义一个提取date和confirm的两个数据的函数,对每个国家执行这个函数,得到dct_data是一个大的字典。
直接用pandas生成这一个字典。
就可以得到一个大表。
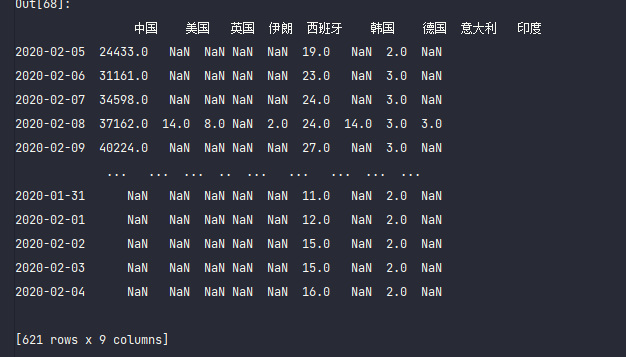
pandas还是很智能,会自动按照各个国家的date排序,把没有数值的弄成NAN,只保留一个date作为index
df_test = pd.DataFrame(dct_data)
df_test.shape
df_test.index
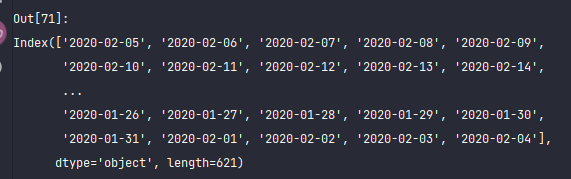
df_test2 = df_test.sort_index(ascending=True)
df_test2
df_test2.keys()
df_test2.columns = ['china', 'usa','uk', 'iran', 'spain', 'korea', 'germey', 'italian', 'india']
df_test2把index按照时间顺序排序,把国家名字改成英文。
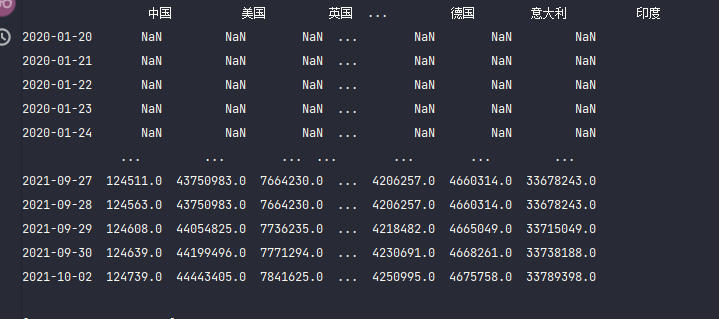
最后
以上就是明亮烤鸡最近收集整理的关于爬虫+数据分析,制作一个世界疫情人数增长动态柱状竞赛图的全部内容,更多相关爬虫+数据分析内容请搜索靠谱客的其他文章。








发表评论 取消回复