免费视频教程 https://www.51doit.com/ 或者联系博主微信 17710299606
1 windows上
System.setProperty("HADOOP_USER_NAME", "root");
Configuration conf = new Configuration();
// 设置访问的集群的位置
conf.set("fs.defaultFS", "hdfs://doit01:9000");
// 设置yarn的位置
conf.set("mapreduce.framework.name", "yarn");
// yarn的resourcemanager的位置
conf.set("yarn.resourcemanager.hostname", "doit01");
// 设置MapReduce程序运行在windows上的跨平台参数
conf.set("mapreduce.app-submission.cross-platform","true");
job.setJar() ;package com._51doit.yarn.wc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* @Auther: 多易教育-行哥
* @Date: 2020/7/10
* @Description:
* 1 运行模式 默认是local 设置运行在yarn上
* 2 yarn的位置 resourcemanage
* 3 读取数据 HDFS
* 4 用户名
* 5 跨平台参数
*
*/
public class WordCountDriver {
public static void main(String[] args) throws Exception {
// 1 配置对象
System.setProperty("HADOOP_USER_NAME", "root");
Configuration conf = new Configuration();
// 设置访问文件系统
conf.set("fs.defaultFS", "hdfs://linux01:9000");
// 设置MR程序运行模式 yarn
conf.set("mapreduce.framework.name", "yarn");
// yarn的resourcemanager的位置
conf.set("yarn.resourcemanager.hostname", "linux01");
// 设置MapReduce程序运行在windows上的跨平台参数
conf.set("mapreduce.app-submission.cross-platform","true");
// 2 创建任务对象
Job job = Job.getInstance(conf, "wc");
job.setJar("C:\Users\ThinkPad\Desktop\demo.jar");
job.setJarByClass(WordCountDriver.class);
// 2.1 设置 map和reduce任务类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//2.2 设置map和reduce 的输出KV
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 2.3 设置reduce的个数 默认1
job.setNumReduceTasks(2);
// 2.3 设置输入和输出路径
FileInputFormat.setInputPaths(job,new Path("/data/wc/"));
FileOutputFormat.setOutputPath(job,new Path("/data/wc_res"));
// 3 提交任务 等待程序执行完毕 返回值是否成功
boolean b = job.waitForCompletion(true);
System.exit(b?0:-1);
}
}打包程序到指定的目录中
2 linux上
打包程序,将jar包上传到Linux操作系统
package com._51doit.yarn.wc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* @Auther: 多易教育-行哥
* @Date: 2020/7/10
* @Description:
* 1 运行模式 默认是local 设置运行在yarn上
* 2 yarn的位置 resourcemanage
* 3 读取数据 HDFS
* 4 用户名
* 5 跨平台参数
*
*/
public class WordCountDriver {
public static void main(String[] args) throws Exception {
// 1 配置对象
// System.setProperty("HADOOP_USER_NAME", "root");
Configuration conf = new Configuration();
// 设置访问文件系统
//conf.set("fs.defaultFS", "hdfs://linux01:9000");
// 设置MR程序运行模式 yarn
conf.set("mapreduce.framework.name", "yarn");
// yarn的resourcemanager的位置
conf.set("yarn.resourcemanager.hostname", "linux01");
// 设置MapReduce程序运行在windows上的跨平台参数
// conf.set("mapreduce.app-submission.cross-platform","true");
// 2 创建任务对象
Job job = Job.getInstance(conf, "wc");
// job.setJar("C:\Users\ThinkPad\Desktop\demo.jar");
job.setJarByClass(WordCountDriver.class);
// 2.1 设置 map和reduce任务类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//2.2 设置map和reduce 的输出KV
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 2.3 设置reduce的个数 默认1
job.setNumReduceTasks(2);
// 2.3 设置输入和输出路径
FileInputFormat.setInputPaths(job,new Path("/data/wc/"));
FileOutputFormat.setOutputPath(job,new Path("/data/wc_res"));
// 3 提交任务 等待程序执行完毕 返回值是否成功
boolean b = job.waitForCompletion(true);
System.exit(b?0:-1);
}
}在配置了HADOOP环境变量的机器上执行命令 运行MR程序
hadoop jar /demo.jar com._51doit.yarn.wc.WordCountDriver
20/07/14 14:41:46 INFO client.RMProxy: Connecting to ResourceManager at linux01/192.168.133.201:8032
20/07/14 14:41:47 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
20/07/14 14:41:47 INFO input.FileInputFormat: Total input files to process : 1
20/07/14 14:41:48 INFO mapreduce.JobSubmitter: number of splits:1
20/07/14 14:41:48 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1594624386350_0003 非本地模式
20/07/14 14:41:48 INFO impl.YarnClientImpl: Submitted application application_1594624386350_0003
20/07/14 14:41:48 INFO mapreduce.Job: The url to track the job: http://linux01:8088/proxy/application_1594624386350_0003/
20/07/14 14:41:48 INFO mapreduce.Job: Running job: job_1594624386350_0003
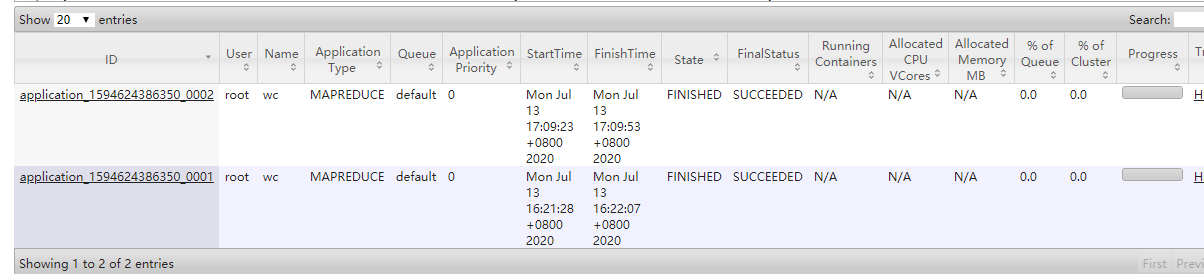
在yarn监控页面可以查看到任务
最后
以上就是凶狠钢铁侠最近收集整理的关于hadoop详细笔记(十七) 将MapReduce程序提交到Yarn上运行1 windows上2 linux上的全部内容,更多相关hadoop详细笔记(十七)内容请搜索靠谱客的其他文章。








发表评论 取消回复