目录
- 一、MapReduce入门
- 1.MapReduce定义
- 2.MapReduce优缺点
- 优点
- 缺点
- 3. MapReduce核心思想
- 4.MapReduce进程
- 5.MapReduce编程规范
- 二、Hadoop序列化
- 1.为什么要序列化?
- 2.什么是序列化?
- 3.为什么不用Java的序列化?
- 4.为什么序列化对Hadoop很重要?
- 5.常用数据序列化类型
- 6.自定义bean对象实现序列化接口(Writable)
- 三、执行hadoop自带wordcount程序
- 1.准备个word.txt文件
- 2.切换到mapreduce下
- 3.执行命令
- 四、自己写个wordcount程序
- WordCountMap
- WordCountReduce
- WordCountMain
- 运行结果
- 部署到hadoop集群上测试
- 打个jar包
- 将测试文件上传到hadoop工作目录上
- 执行命令测试
开局一把刀,装备全靠打。
我们开局先讲概念,然后执行下hadoop自带的一个wordcount程序,相当于我们java中的hello word。
然后自己动手写个wordcount程序,在win10下看下效果,最后部署到服务器上看下效果。
一、MapReduce入门
1.MapReduce定义
Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架。
Mapreduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上。
2.MapReduce优缺点
优点
- 1)MapReduce 易于编程。它简单的实现一些接口,就可以完成一个分布式程序,这个分布式程序可以分布到大量廉价的PC机器上运行。也就是说你写一个分布式程序,跟写一个简单的串行程序是一模一样的。就是因为这个特点使得MapReduce编程变得非常流行。
- 2)良好的扩展性。当你的计算资源不能得到满足的时候,你可以通过简单的增加机器来扩展它的计算能力。(此处可以自己动手添加个datanode的实验试试,看下集群上有没有)
参考这篇文章 https://blog.csdn.net/baidu_21349635/article/details/91949972 - 3)高容错性。MapReduce设计的初衷就是使程序能够部署在廉价的PC机器上,这就要求它具有很高的容错性。比如其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上运行,不至于这个任务运行失败,而且这个过程不需要人工参与,而完全是由 Hadoop内部完成的。
- 4)适合PB级以上海量数据的离线处理。它适合离线处理而不适合在线处理。比如像毫秒级别的返回一个结果,MapReduce很难做到。
缺点
MapReduce不擅长做实时计算、流式计算、DAG(有向无环图)计算。
- 1)实时计算。MapReduce无法像Mysql一样,在毫秒或者秒级内返回结果。
- 2)流式计算。流式计算的输入数据是动态的,而MapReduce的输入数据集是静态的,不能动态变化。这是因为MapReduce自身的设计特点决定了数据源必须是静态的。
- 3)DAG(有向无环图)计算。多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,MapReduce并不是不能做,而是使用后,每个MapReduce作业的输出结果都会写入到磁盘,会造成大量的磁盘IO,导致性能非常的低下。
- 4)MapReduce编程模型只能包含一个map阶段和一个reduce阶段,如果用户的业务逻辑非常复杂,那就只能多个mapreduce程序,串行运行。
3. MapReduce核心思想
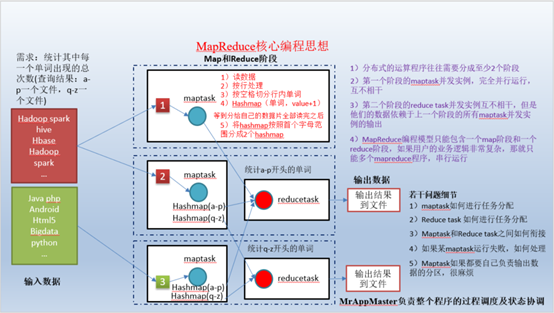
来个通俗点的图。
4.MapReduce进程
一个完整的mapreduce程序在分布式运行时有三类实例进程:
- 1)MrAppMaster:负责整个程序的过程调度及状态协调。
- 2)MapTask:负责map阶段的整个数据处理流程。
- 3)ReduceTask:负责reduce阶段的整个数据处理流程。
5.MapReduce编程规范
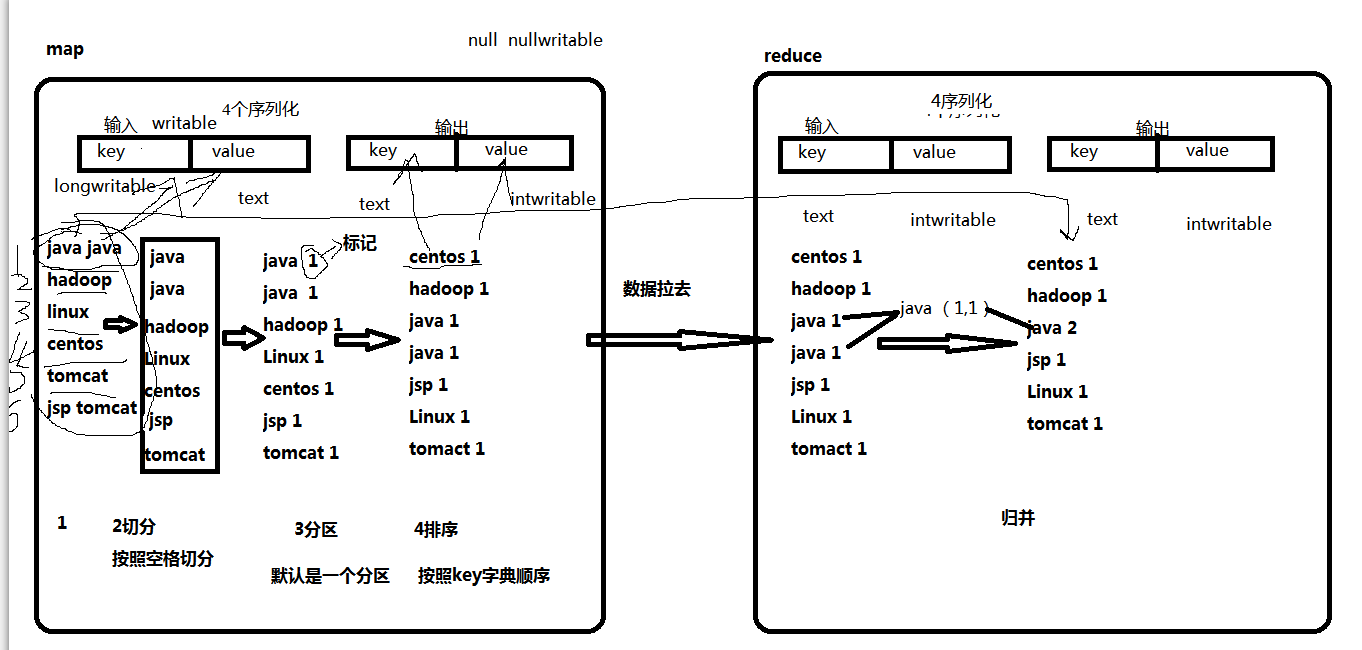
用户编写的程序分成三个部分:Mapper,Reducer,Driver(提交运行mr程序的客户端)
1)Mapper阶段
(1)用户自定义的Mapper要继承自己的父类
(2)Mapper的输入数据是KV对的形式(KV的类型可自定义)
(3)Mapper中的业务逻辑写在map()方法中
(4)Mapper的输出数据是KV对的形式(KV的类型可自定义)
(5)map()方法(maptask进程)对每一个<K,V>调用一次
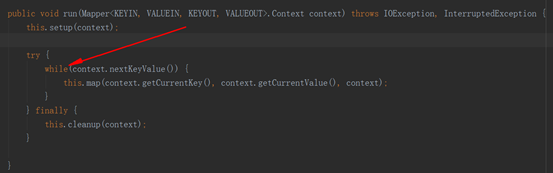
2)Reducer阶段
(1)用户自定义的Reducer要继承自己的父类
(2)Reducer的输入数据类型对应Mapper的输出数据类型,也是KV
(3)Reducer的业务逻辑写在reduce()方法中
(4)Reducetask进程对每一组相同k的<k,v>组调用一次reduce()方法
3)Driver阶段
整个程序需要一个Drvier来进行提交,提交的是一个描述了各种必要信息的job对象
二、Hadoop序列化
1.为什么要序列化?
一般来说,“活的”对象只生存在内存里,关机断电就没有了。而且“活的”对象只能由本地的进程使用,不能被发送到网络上的另外一台计算机。 然而序列化可以存储“活的”对象,可以将“活的”对象发送到远程计算机。
2.什么是序列化?
序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储(持久化)和网络传输。
反序列化就是将收到字节序列(或其他数据传输协议)或者是硬盘的持久化数据,转换成内存中的对象。
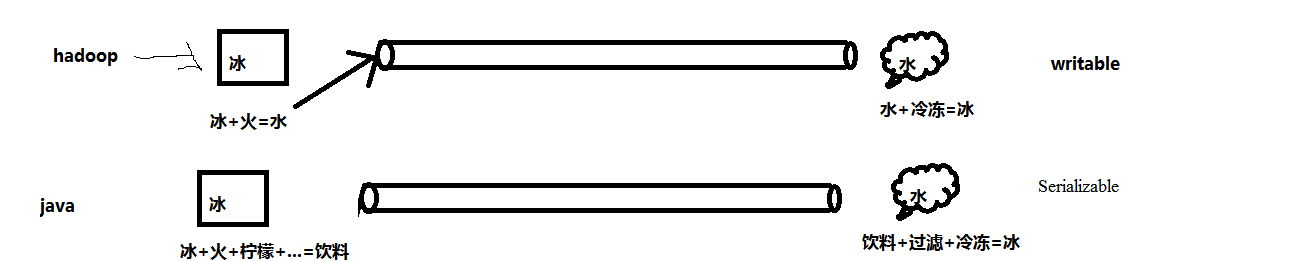
3.为什么不用Java的序列化?
Java的序列化是一个重量级序列化框架(Serializable),一个对象被序列化后,会附带很多额外的信息(各种校验信息,header,继承体系等),不便于在网络中高效传输。所以,hadoop自己开发了一套序列化机制(Writable),精简、高效。
4.为什么序列化对Hadoop很重要?
因为Hadoop在集群之间进行通讯或者RPC调用的时候,需要序列化,而且要求序列化要快,且体积要小,占用带宽要小。所以必须理解Hadoop的序列化机制。
序列化和反序列化在分布式数据处理领域经常出现:进程通信和永久存储。然而Hadoop中各个节点的通信是通过远程调用(RPC)实现的,那么RPC序列化要求具有以下特点:
1)紧凑:紧凑的格式能让我们充分利用网络带宽,而带宽是数据中心最稀缺的资
2)快速:进程通信形成了分布式系统的骨架,所以需要尽量减少序列化和反序列化的性能开销,这是基本的;
3)可扩展:协议为了满足新的需求变化,所以控制客户端和服务器过程中,需要直接引进相应的协议,这些是新协议,原序列化方式能支持新的协议报文;
4)互操作:能支持不同语言写的客户端和服务端进行交互;
5.常用数据序列化类型
常用的数据类型对应的hadoop数据序列化类型
| Java****类型 | Hadoop Writable****类型 |
|---|---|
| boolean | BooleanWritable |
| byte | ByteWritable |
| int | IntWritable |
| float | FloatWritable |
| long | LongWritable |
| double | DoubleWritable |
| string | Text |
| map | MapWritable |
| array | ArrayWritable |
6.自定义bean对象实现序列化接口(Writable)
1)自定义bean对象要想序列化传输,必须实现序列化接口,需要注意以下7项。
(1)必须实现Writable接口
(2)反序列化时,需要反射调用空参构造函数,所以必须有空参构造
public FlowBean() {
super();
}
(3)重写序列化方法
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
(4)重写反序列化方法
@Override
public void readFields(DataInput in) throws IOException {
upFlow = in.readLong();
downFlow = in.readLong();
sumFlow = in.readLong();
}
(5)注意反序列化的顺序和序列化的顺序完全一致
(6)要想把结果显示在文件中,需要重写toString(),可用”t”分开,方便后续用。
(7)如果需要将自定义的bean放在key中传输,则还需要实现comparable接口,因为mapreduce框中的shuffle过程一定会对key进行排序。
@Override
public int compareTo(FlowBean o) {
// 倒序排列,从大到小
return this.sumFlow > o.getSumFlow() ? -1 : 1;
}
三、执行hadoop自带wordcount程序
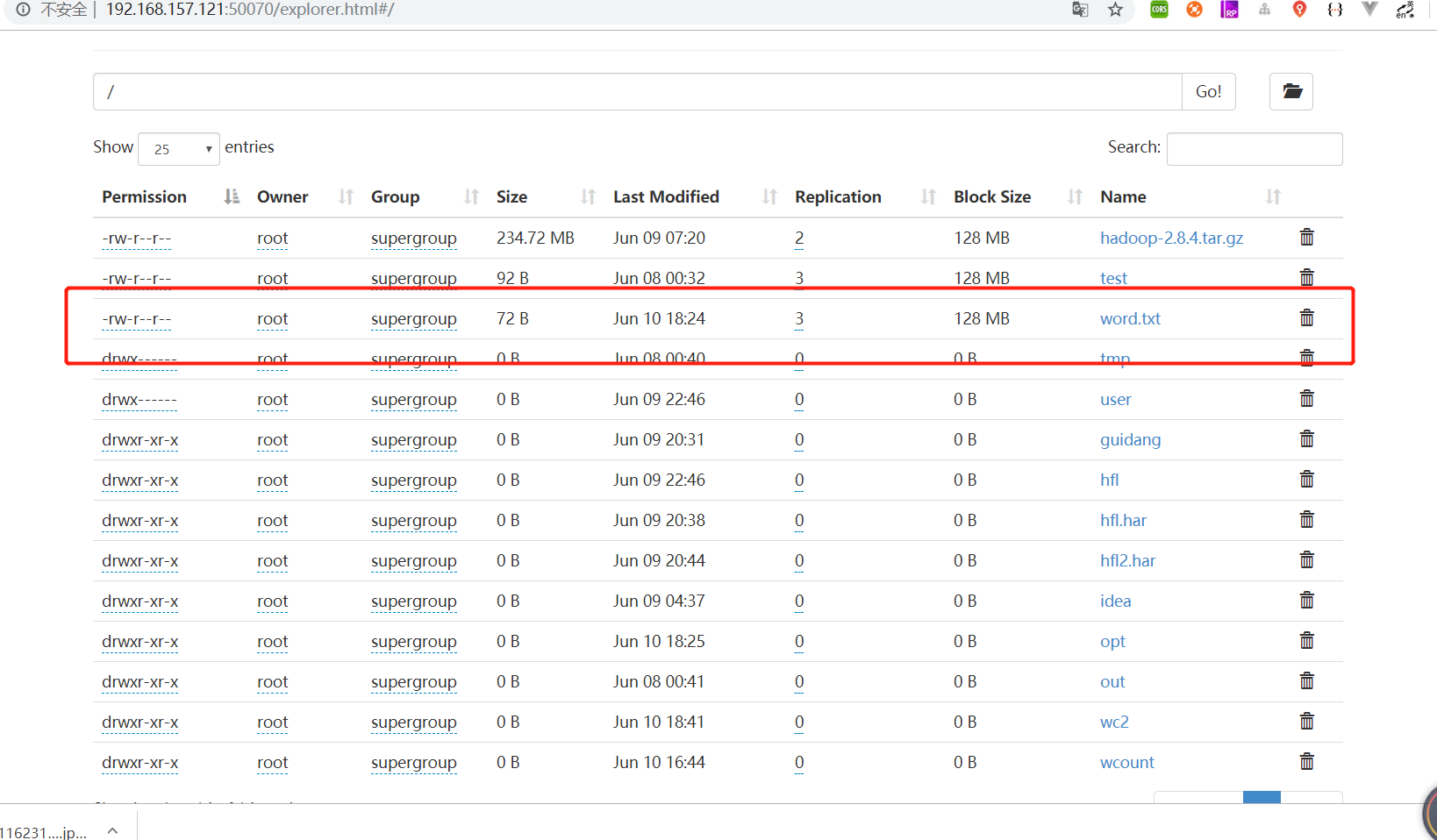
1.准备个word.txt文件
[root@bigdata121 mod]# ls
a aa b bbb c d fsimage.xml hadoop-2.8.4 hdfs-demo-1.0-SNAPSHOT.jar hfl.sh jdk1.8.0_144 test word.txt
[root@bigdata121 mod]# cat word.txt
java java
hadoop
linux
centos
jsp tomcat hadoop mpareduce hdfs apache
然后执行上传,上传到hdfs
hadoop fs -put /opt/mod/word.txt /word.txt
2.切换到mapreduce下
[root@bigdata121 mapreduce]# pwd
/opt/mod/hadoop-2.8.4/share/hadoop/mapreduce
[root@bigdata121 mapreduce]# ls
hadoop-mapreduce-client-app-2.8.4.jar hadoop-mapreduce-client-hs-2.8.4.jar hadoop-mapreduce-client-jobclient-2.8.4-tests.jar jdiff sources
hadoop-mapreduce-client-common-2.8.4.jar hadoop-mapreduce-client-hs-plugins-2.8.4.jar hadoop-mapreduce-client-shuffle-2.8.4.jar lib
hadoop-mapreduce-client-core-2.8.4.jar hadoop-mapreduce-client-jobclient-2.8.4.jar hadoop-mapreduce-examples-2.8.4.jar lib-examples
[root@bigdata121 mapreduce]#
3.执行命令
hadoop jar hadoop-mapreduce-examples-2.8.4.jar wordcount /word.txt /wcount
运行完毕看下,结果
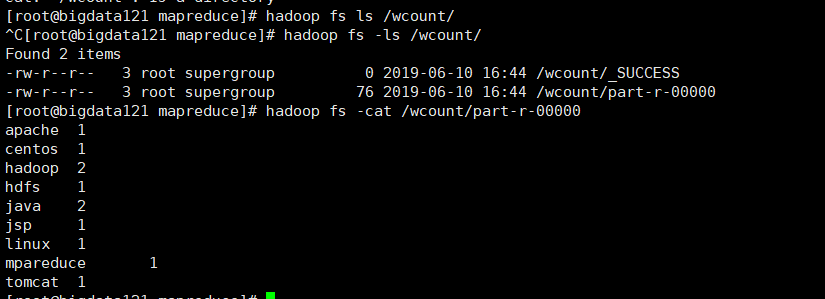
完美!!
四、自己写个wordcount程序
WordCountMap
package com.hfl.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
//坑,自动导包Text很容易导成java
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMap extends Mapper<LongWritable, Text, Text, IntWritable> {
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//拿到数据,进行数据转换Text=》String
String line = value.toString();
//按照空格切分
String[] split = line.split(" ");
//输出数据KEYOUT, VALUEOUT
for (String s : split) {
//数据转换String=》Text int=》IntWritable
context.write(new Text(s), new IntWritable(1));
}
}
}
WordCountReduce
package com.hfl.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Iterator;
public class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable>{
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count=0;
// //方法1:初始化一个计数器
//开始计数
// for (IntWritable value:values) {
// count=count+value.get();
// }
//方法2: 重写源代码方法
Iterator i$ = values.iterator();
while(i$.hasNext()) {
IntWritable value = (IntWritable) i$.next();
count += count + value.get();
}
context.write(key, new IntWritable(count));
}
}
WordCountMain
package com.hfl.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountMain {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//args=new String[]{"F:\input\wcword.txt","F:\input\wcword1"};
//获取配置文件
Configuration conf = new Configuration();
//创建job任务
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountMain.class);
//指定Map类和map的输出类型 Text, IntWritable
job.setMapperClass(WordCountMap.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//指定Reducer类和reduce的输出数据类型 Text,IntWritable
job.setReducerClass(WordCountReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//指定数据输入的路径和输出的路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//提交任务
// job.setJar("WordCount.jar");
job.waitForCompletion(true);
}
}
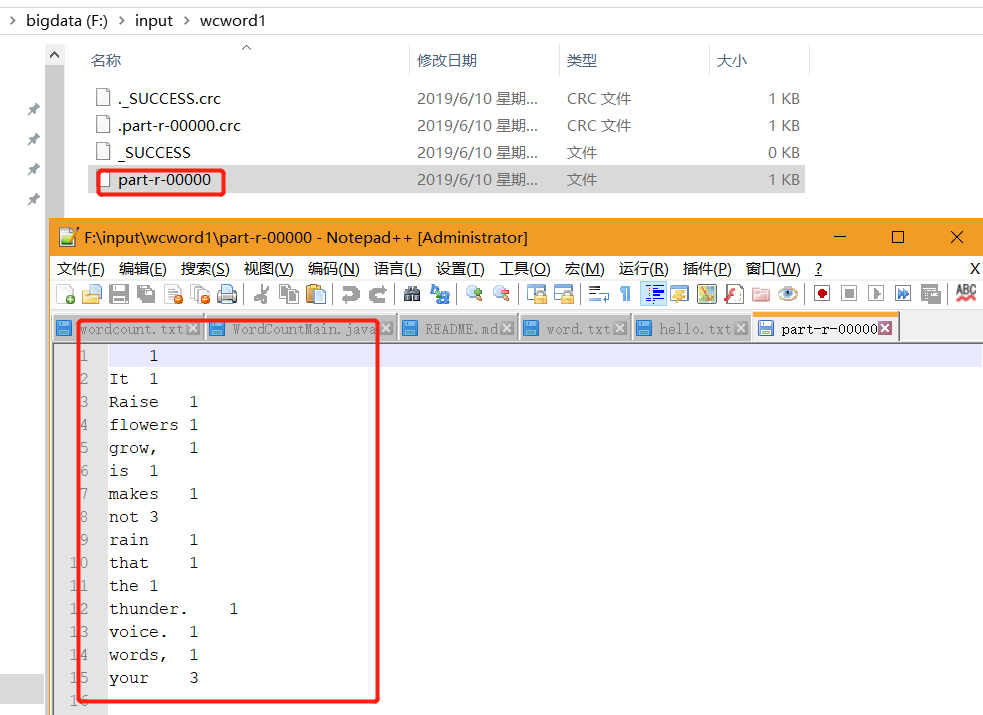
F:inputwcword.txt
Raise your words, not your voice.
It is rain that makes the flowers grow, not thunder.
运行结果
部署到hadoop集群上测试
打个jar包
放在集群的一个目录上
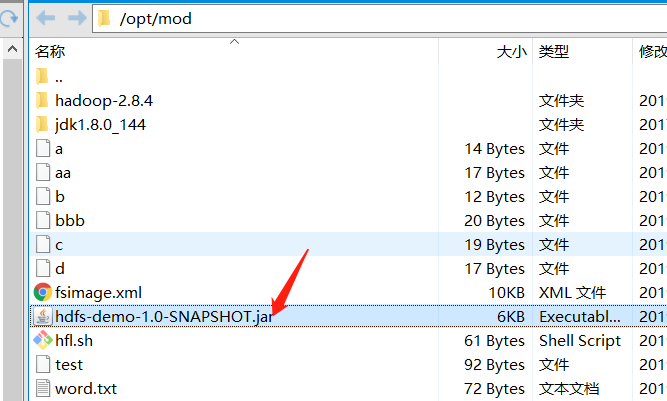
将测试文件上传到hadoop工作目录上
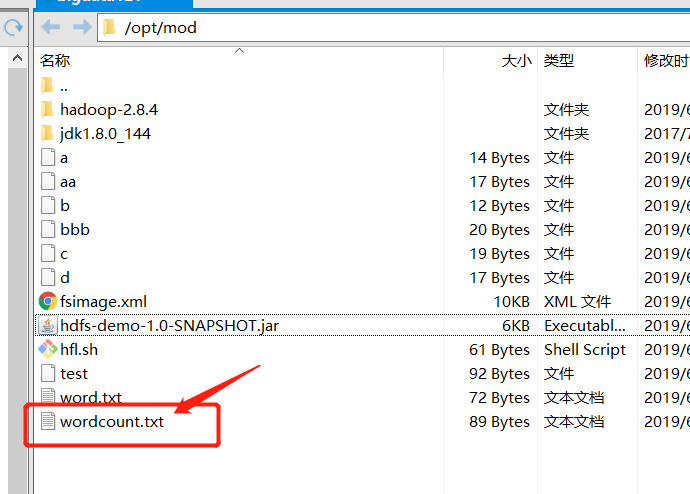
hadoop fs -put /opt/mod/wordcount.txt /wordcount3
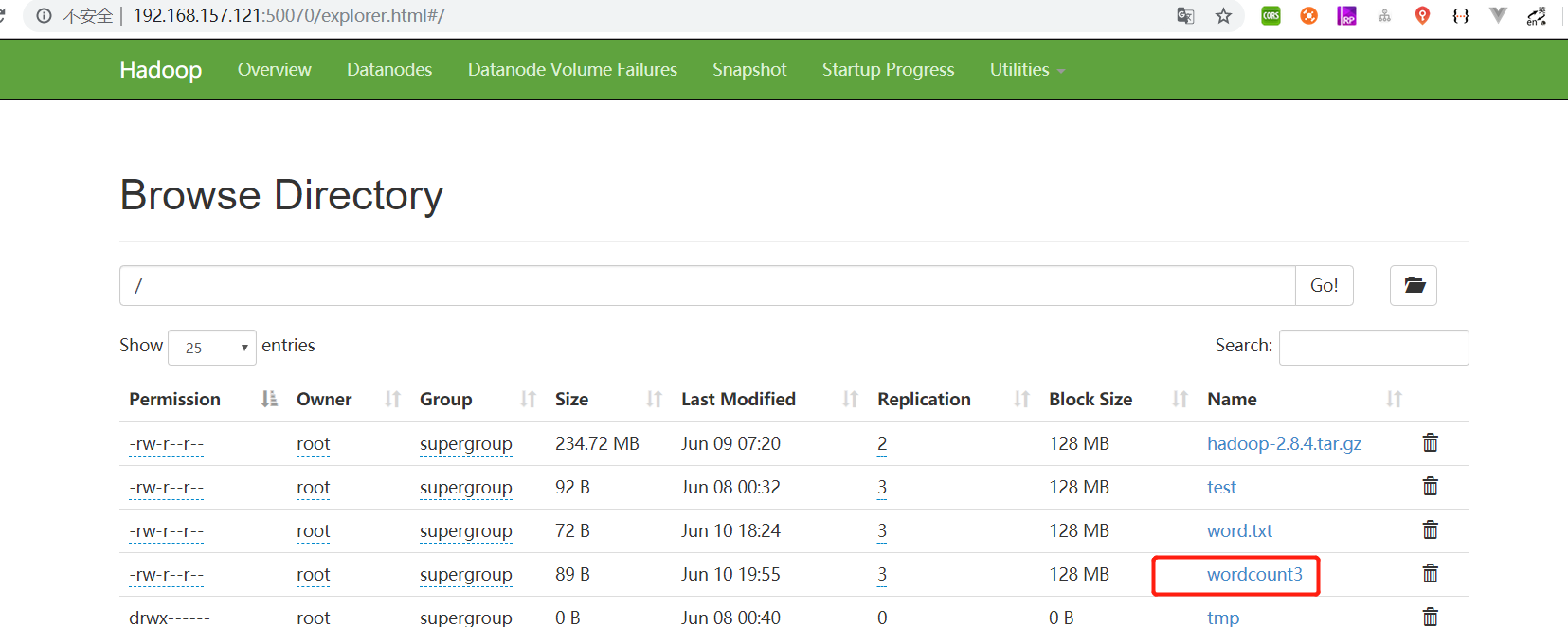
执行命令测试
hadoop jar /opt/mod/hdfs-demo-1.0-SNAPSHOT.jar com.hfl.wordcount.WordCountMain /wordcount3 /wordcount3-reslut
查看结果:
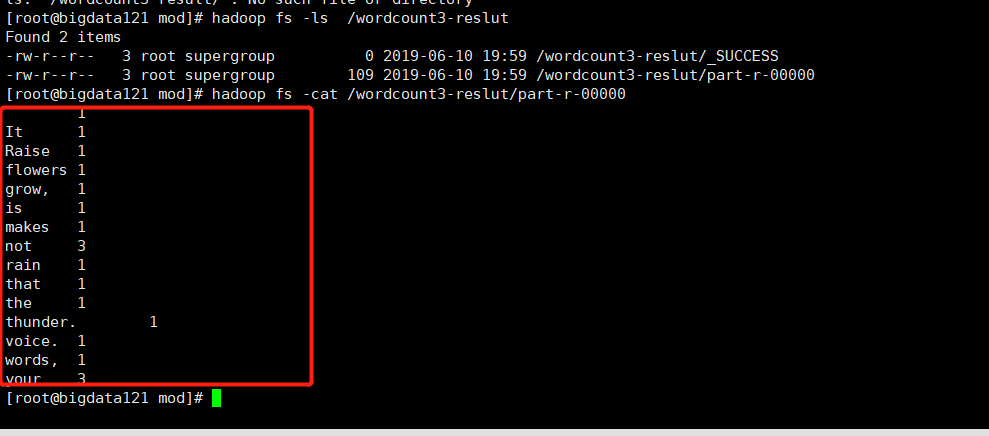
大功告成!!收工。
最后
以上就是壮观春天最近收集整理的关于hadoop之mapreduce的wordcount程序(10)一、MapReduce入门二、Hadoop序列化三、执行hadoop自带wordcount程序四、自己写个wordcount程序的全部内容,更多相关hadoop之mapreduce内容请搜索靠谱客的其他文章。








发表评论 取消回复