如图所示我们要计算每年中每个月气温倒序排行,在这个例子中我们输入文件中的年份只有3个,所以例子中的reduceTask个数是3个。如果不确定年份的个数,就不能使用年份维度作为reduceTask个数。
首先,上传weather文件到/usr/input下:
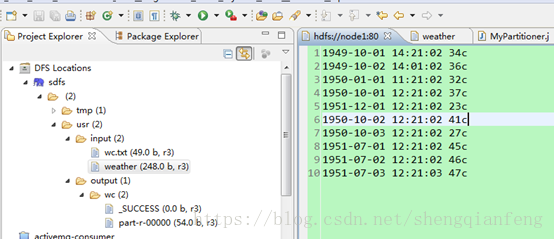
执行任务:
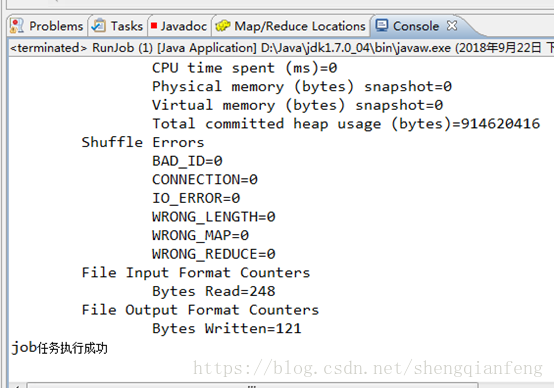
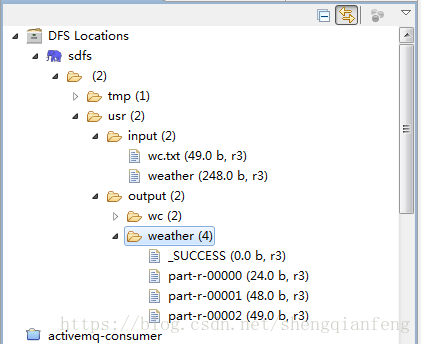
分别查看/usr/output/weather下的三个文件内容:
1949年:
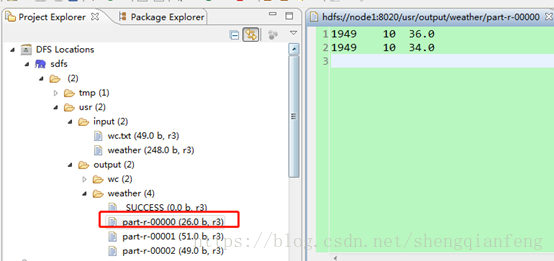
1950年:
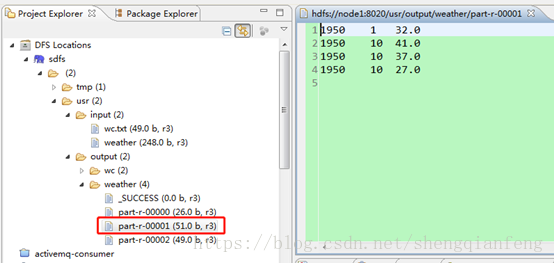
1951年:
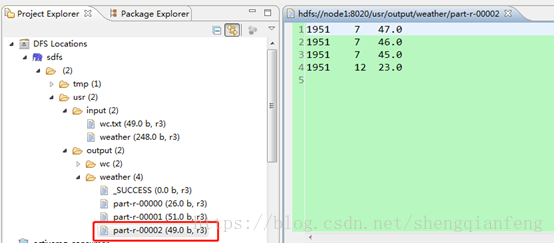
上代码:
package com.jeff.mr.weather;
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.Calendar;
import java.util.Date;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* 定义Map Task的输入输出类型:
* Mapper<Text, Text, MyKey, DoubleWritable>
*
* @author jeffSheng
* 2018年9月22日
*/
public class WeatherMapper extends Mapper<Text, Text, MyKey, DoubleWritable> {
SimpleDateFormat sdf =new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
// NullWritable v =NullWritable.get();
/**
* 1949-10-01 14:21:02 34c
* 每行第一个分割符(文件中制表符tab)左边为key,右边为value,
* key:
* 对应下边的记录key就是1949-10-01 14:21:02
*
* value:
* 就是34c
*
*/
protected void map(Text key, Text value,Context context)
throws IOException, InterruptedException {
try {
//将key即文件中每行的时间字符串转为日期类型
Date date =sdf.parse(key.toString());
//使用Calendar获取年月
Calendar c =Calendar.getInstance();
c.setTime(date);
int year =c.get(Calendar.YEAR);
int month =c.get(Calendar.MONTH);
//拆分value获得温度
double hot =Double.parseDouble(value.toString().substring(0, value.toString().lastIndexOf("c")));
//创建输出数据的key,即我们自定义的MyKey
MyKey k =new MyKey();
k.setYear(year);
k.setMonth(month+1);
k.setHot(hot);
//输出数据类型:MyKey, DoubleWritable
context.write(k, new DoubleWritable(hot));
} catch (Exception e) {
e.printStackTrace();
}
}
}
package com.jeff.mr.weather;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
/**
* 自定义key:
* 1 实现WritableComparable接口,用于实现序列化和比较两个key是否相等
* @author jeffSheng
* 2018年9月22日
*/
public class MyKey implements WritableComparable<MyKey>{
private int year;
private int month;
//温度
private double hot;
public int getYear() {
return year;
}
public void setYear(int year) {
this.year = year;
}
public int getMonth() {
return month;
}
public void setMonth(int month) {
this.month = month;
}
public double getHot() {
return hot;
}
public void setHot(double hot) {
this.hot = hot;
}
/**
* 判断对象是否是同一个对象,当该对象作为输出的key:
* 比较规则:依次判断年月日是否相等
*/
@Override
public int compareTo(MyKey o) {
int r1 =Integer.compare(this.year, o.getYear());
if(r1==0){
int r2 =Integer.compare(this.month, o.getMonth());
if(r2==0){
return Double.compare(this.hot, o.getHot());
}else{
return r2;
}
}else{
return r1;
}
}
//进行反序列化
@Override
public void readFields(DataInput arg0) throws IOException {
this.year=arg0.readInt();
this.month=arg0.readInt();
this.hot=arg0.readDouble();
}
//进行序列化
@Override
public void write(DataOutput arg0) throws IOException {
arg0.writeInt(year);
arg0.writeInt(month);
arg0.writeDouble(hot);
}
@Override
public String toString() {
return "MyKey [year=" + year + ", month=" + month + ", hot=" + hot
+ "]";
}
}
package com.jeff.mr.weather;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
/**
* <MapTask端的分区Partition操作>
*
* 使用多个Reduce Task,将每一年的数据分区到每一个Reduce task,默认的分区算法HashPartitioner是根据key的hashcode对分区数取模,
* 但是我们的Mykey的hashcode是对象的hashcode不能这么使用,所以我们自定义分区算法MyPartitioner
*
* Tips:继承默认的HashPartitioner
* @author jeffSheng
* 2018年9月22日
*/
public class MyPartitioner extends HashPartitioner<MyKey, DoubleWritable>{
/**
* 计算输出数据的分区号:
* getPartition这个方法的调用时机是:mapTask每当输出一个数据的时候就会调用一次,调用频繁,所以执行时间越短越好。
* @param MyKey mapTask输出的key
* @param DoubleWritable mapTask输出的value
* @param numReduceTasks 分区数
*
* 需求:一年一个reduce分区,所以根据年份个数就可以确定分区数numReduceTasks
* 1949年是年份最小的年,不知道年份直接取模就好
*/
public int getPartition(MyKey key, DoubleWritable value, int numReduceTasks) {
return (key.getYear() - 1949) % numReduceTasks;
}
}
package com.jeff.mr.weather;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
/**
* <MapTask输出数据进行Sort排序>
*
* MyKey自定义排序
* 继承默认的排序方法WritableComparator,算法是根据key的ASCII码排序,字典排序。
* 排序完溢写到磁盘spill to disk,然后reduceTask端phase抓取数据进行第二次排序,还是调用MySort程序,
* 然后进行分组,我们自定义分组。
*
* @author jeffSheng
* 2018年9月22日
*/
public class MySort extends WritableComparator{
//在构造方法中指定比较类型是MyKey并创建MyKey对象
public MySort(){
super(MyKey.class,true);
}
/**
*
* 重写org.apache.hadoop.io.WritableComparator的compare方法,比较排序
*
* 需求:比较每一年的每一个月的温度降序,即年月相同的情况下再比较温度,温度降序排列
*/
@Override
public int compare(WritableComparable a, WritableComparable b) {
MyKey k1 =(MyKey) a;
MyKey k2 =(MyKey) b;
System.out.println("【比较排序】:"+k1+"------"+k2);
int r1 =Integer.compare(k1.getYear(), k2.getYear());
if(r1==0){
int r2 =Integer.compare(k1.getMonth(), k2.getMonth());
if(r2==0){
//降序-,其他情况年月不等
return -Double.compare(k1.getHot(), k2.getHot());
}else{
return r2;
}
}else{
return r1;
}
}
}
package com.jeff.mr.weather;
import java.io.IOException;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
* 计算每年每月中气温最高的前三个温度
*
* @author jeffSheng
* 2018年9月22日
*/
public class WeatherReducer extends Reducer<MyKey, DoubleWritable, Text, NullWritable>{
/**
* 需求:输出每年每月中气温最高的前三个温度
*/
protected void reduce(MyKey arg0, Iterable<DoubleWritable> arg1,
Context context)
throws IOException, InterruptedException {
int i=0;
/**
* @desc 迭代二次排序后分好组的温度列表
* 循环调用此方法,每组调用一次
*
*/
for(DoubleWritable hot :arg1){
i++;
String msg = arg0.getYear() + "t" + arg0.getMonth() + "t" + hot.get();
context.write(new Text(msg), NullWritable.get());
if(i==3){
break;
}
}
}
}
package com.jeff.mr.weather;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
/**
* <ReduceTask端二次排序后的分组操作>
* reduceTask端phase抓取数据进行第二次排序,还是调用MySort程序,
* 然后进行分组,我们自定义分组。
*
* @author jeffSheng
* 2018年9月22日
*/
public class MyGroup extends WritableComparator{
public MyGroup(){
super(MyKey.class,true);
}
/**
* 需求:年和月相同则是一组
*/
public int compare(WritableComparable a, WritableComparable b) {
MyKey k1 =(MyKey) a;
MyKey k2 =(MyKey) b;
int r1 =Integer.compare(k1.getYear(), k2.getYear());
if(r1==0){
return Integer.compare(k1.getMonth(), k2.getMonth());
}else{
return r1;
}
}
}
package com.jeff.mr.weather;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class RunJob {
public static void main(String[] args) {
Configuration config =new Configuration();
config.set("fs.defaultFS", "hdfs://node1:8020");
config.set("yarn.resourcemanager.hostname", "node1");
// config.set("mapred.jar", "C:\Users\Administrator\Desktop\wc.jar");
//可以自定义key和value的分隔符
// config.set("mapreduce.input.keyvaluelinerecordreader.key.value.separator", ",");
try {
FileSystem fs =FileSystem.get(config);
Job job =Job.getInstance(config);
job.setJarByClass(RunJob.class);
job.setJobName("weather");
job.setMapperClass(WeatherMapper.class);
job.setReducerClass(WeatherReducer.class);
job.setMapOutputKeyClass(MyKey.class);
job.setMapOutputValueClass(DoubleWritable.class);
//设置自定义分区器
job.setPartitionerClass(MyPartitioner.class);
//设置自定义排序器
job.setSortComparatorClass(MySort.class);
//设置自定义分组器
job.setGroupingComparatorClass(MyGroup.class);
//设置分区个数,默认不写则是1,例子中有3年,当然了,如果不知道多少年就不应该按照年分区,知道那就可以
job.setNumReduceTasks(3);
//默认是按照行的下标作为key,设置以下代码可以使得key和value分隔符为制表符t
job.setInputFormatClass(KeyValueTextInputFormat.class);
FileInputFormat.addInputPath(job, new Path("/usr/input/weather"));
Path outpath =new Path("/usr/output/weather");
if(fs.exists(outpath)){
fs.delete(outpath, true);
}
FileOutputFormat.setOutputPath(job, outpath);
boolean f= job.waitForCompletion(true);
if(f){
System.out.println("job任务执行成功");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
需要注意的是在这个例子中输入文件MapTask执行的时候,我们是把时间当做输入key,把温度当做输入value,跟我们之前的把行的下标做输入key不一样,需要设置:
//默认是按照行的下标作为key,设置以下代码可以使得key和value分隔符为制表符t
job.setInputFormatClass(KeyValueTextInputFormat.class);如果不想使用制表符作为输入文件行的输入Key和输入Value之间的分隔符,可以自定义比如逗号:
//可以自定义key和value的分隔符
config.set("mapreduce.input.keyvaluelinerecordreader.key.value.separator", ",");
最后
以上就是高高小懒虫最近收集整理的关于案例2-mapreduce统计每年中每个月气温排行的全部内容,更多相关案例2-mapreduce统计每年中每个月气温排行内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复