1 快速总结
若损失函数为 l o s s = m i n ∑ ( y i − w T x i ) 2 loss = minsum(y_i-w^Tx_i)^2 loss=min∑(yi−wTxi)2
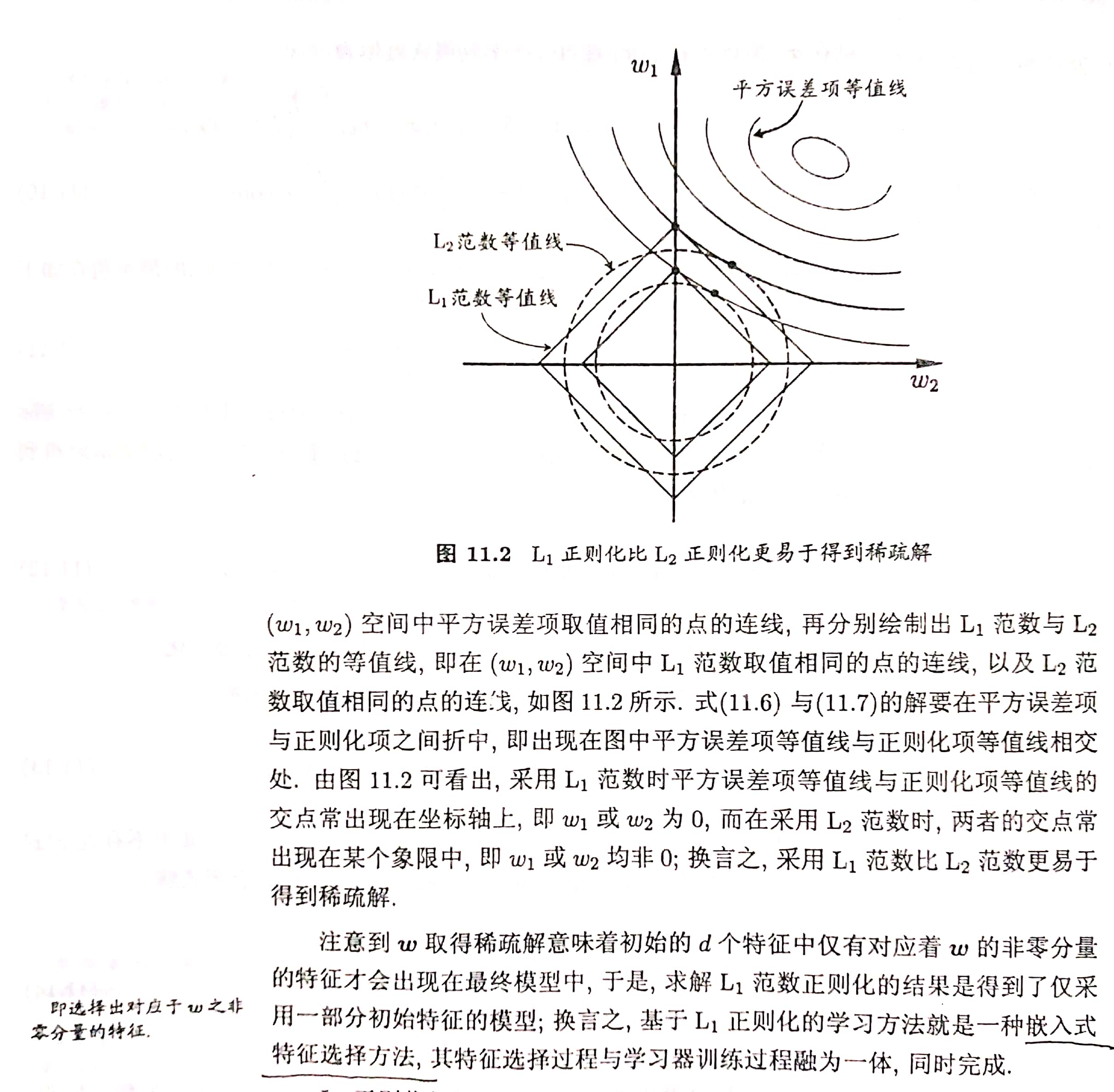
1.1 L1、L2正则化的原理。
- L1——> |w| ——>菱形
L1正则化的公式:
m i n ∑ ( y i − w T x i ) 2 + λ ∣ ∣ w ∣ ∣ 1 minsum(y_i-w^Tx_i)^2+lambda||w||_1 min∑(yi−wTxi)2+λ∣∣w∣∣1
即
n e w l o s s = l o s s + λ ∣ ∣ w ∣ ∣ 1 newloss = loss + lambda||w||_1 newloss=loss+λ∣∣w∣∣1 - L2——>w2——>圆形
L2正则化的公式:
m i n ∑ ( y i − w T x i ) 2 + λ ∣ ∣ w ∣ ∣ 2 2 minsum(y_i-w^Tx_i)^2+lambda||w||_2^2 min∑(yi−wTxi)2+λ∣∣w∣∣22
上式即“岭回归”。
即
n e w l o s s = l o s s + λ ∣ ∣ w ∣ ∣ 2 2 newloss = loss + lambda||w||_2^2 newloss=loss+λ∣∣w∣∣22
1.2 为什么要使用L1、L2正则化?
L1、L2都可以防止过拟合,L1还可以获得“稀疏”解。
- L1 正则化可以产生稀疏权值矩阵,用于特征选择,以及为什么?
L1 :|w| ——> 菱形——>在菱形的顶点上必然会有某些权值wi为0,某些权值wj不为0。 - L2正则化为什么可以(在一定程度上)防止过拟合?可参考文献[1]
lambda越小,C值越大,约束圈越大,越容易包含最优解位置,容易过拟合。
lambda越大,C值越小,约束圈越小,越可以防止过拟合。(注意:若C值过小,会导致欠拟合。)
C值即圆的半径,sklearn中的正则化参数C即此处的C值。
2 参考文献
详细内容参考下面两篇文献即可。建议:
- 文献[1]已经包括全部内容,建议先耐心看完文献[1]。
- 为了加深理解,再快速看一遍文献[2]。
- 上面两篇文献已经写地很棒了,若担心权威问题,可再看下面摘自《机器学习-周志华》的内容。
[1] 【通俗易懂】机器学习中 L1 和 L2 正则化的直观解释
[2] L1惩罚项和L2惩罚项
[3]《机器学习》周志华

最后
以上就是喜悦飞机最近收集整理的关于机器学习算法 之 L1、L2正则化1 快速总结2 参考文献的全部内容,更多相关机器学习算法内容请搜索靠谱客的其他文章。








发表评论 取消回复