参照百度百科,词法分析器又称扫描器,其作用为将编写的文本代码流解析成一个个记号(种别码),供后续语法分析使用。扫描器在其工作过程中,一般应完成下列的任务
(1)识别出源程序中的各个单词符号,并将其转换为内部编码形式;
(2)删除无用的空白字符、回车字符以及其它非实质性字符;
(3)删除注释;
(4)进行词法检查,报告所发现的错误。
大概花了一节课的时间思考了一下实现流程:首先,读到空格则略过,读下一个字符;若读到的是字母,就再接着读,直到读到的既不是字母也不是数字也不是下划线(终于知道为什么变量必须字母打头了),并将读到的写入到token数组;若读到的是数字,直到读到的不是数字或小数点,将读到的写入到token数组;若读到的是<|>|=,则再读入下一位,若为=,则该运算符为<=|>=|==,若为其他字符,则返回<|>|=的种别码;若读到的是/,则读下一位,若为*,则说明之后为注释内容,一直读入直到读入*,并判断下一位是否为/,若是则注释结束,不是继续往下一位读入;若读入n,则行数加一,若读入的字符与以上都不匹配,则报错,并输出出错行数
种别码:
| 单词符号 | 种别码 | 单词符号 | 种别码 |
| NUM | 1 | + | 22 |
| ID | 2 | - | 23 |
| main | 3 | * | 24 |
| if | 4 | / | 25 |
| else | 5 | = | 26 |
| while | 6 | >= | 27 |
| do | 7 | > | 28 |
| Int | 8 | <= | 29 |
| double | 9 | < | 30 |
| float | 10 | , | 31 |
| void | 11 | . | 32 |
| switch | 12 | % | 33 |
| case | 13 | : | 34 |
| for | 14 | ; | 35 |
| ( | 15 | “ | 36 |
| ) | 16 | ! | 37 |
| { | 17 | [ | 19 |
| } | 18 | ] | 20 |
| # | 0 | ++ | 38 |
| /* | 40 | -- | 39 |
| */ | 41 |
|
代码实现:
#include<iostream>
#include<string.h>
#include<stdlib.h>
#define token_size 10
#define code_size 100
const char *keyword[12]={"main","if","else","while","do","int","double","float","void","switch","case","for"};
using namespace std;
void input_code(char *code){
char ch;
int i;
for(i=0;cin.get(ch) && ch!='#';i++){
*(code+i)=ch;
}
*(code+i)='#';
}
void init_token(char *token){ //初始化token数组
for(int i=0;i<token_size;i++)
*(token+i)=NULL;
}
int judge_token(char *code, char *token, int *order){
init_token(token);
int token_num=0;
while( *(code+*order)==' ' )
(*order)++;
if( *(code+*order)>='0'&&*(code+*order)<='9' ){ //判断是否为数字
while( *(code+*order)>='0'&&*(code+*order)<='9'||*(code+*order)=='.' ){
*(token+token_num)=*(code+*order);
token_num++;(*order)++;
}
return 1;
}
else if( (*(code+*order)>='a'&&*(code+*order)<='z') || (*(code+*order)>='A'&&*(code+*order)<='Z') ){ //判断是否为标识符或变量名
while( (*(code+*order)>='0'&&*(code+*order)<='9') || (*(code+*order)>='a'&&*(code+*order)<='z') || (*(code+*order)>='A'&&*(code+*order)<='Z') || *(code+*order)=='_' ){
*(token+token_num)=*(code+*order);
token_num++;(*order)++;
}
*(token+token_num++)='�';
for(int i=0;i<12;i++){
if( strcmp(token,keyword[i]) )
return i+2;
}
return 2;
}
else { //判断是否为其他运算符
*(token+token_num++)=*(code+(*order));
switch( *(code+(*order)++) ){
case '(': return 15;
case ')': return 16;
case '{': return 17;
case '}': return 18;
case '[': return 19;
case ']': return 20;
case '#': return 0;
case '+':
if( *(code+(*order))=='+' ){
*(token+token_num++)=*(code+(*order)++);
return 22;
}
else {
return 38;
}
case '-':
if( *(code+(*order))=='-' ){
*(token+token_num++)=*(code+(*order)++);
return 23;
}
else {
return 39;
}
case '*':
if( *(code+(*order))!='/' )
return 24;
else {
*(token+token_num++)=*(code+(*order)++);
return 41;
}
case '/':
if( *(code+(*order))!='*' )
return 25;
else {
*(token+token_num++)=*(code+(*order)++);
return 40;
}
case '=': return 26;
case '>':
if( *(code+(*order))=='=' ){
*(token+token_num++)=*(code+(*order)++);
return 27;
}
else {
return 28;
}
case '<':
if( *(code+(*order))=='=' ){
*(token+token_num++)=*(code+(*order)++);
return 29;
}
else {
return 30;
}
case ',': return 31;
case '.': return 32;
case '%': return 33;
case ':': return 34;
case ';': return 35;
case '"': return 36;
case '!': return 37;
case 'n': init_token(token); return -2;
default: return -1;
}
}
}
void judge(char *code){
int order=0, row=1;
int symbol;
char token[token_size];
do{
symbol=judge_token(code, token, &order);
switch(symbol){
case -1: //返回未识别字符所在行数
cout << "第" << row << "行出现错误" << endl;
break;
case -2: //读到了回车键,进行换行,行数加一
row++;
break;
case 40:
cout << "<" << symbol << "," << token << ">" << endl; //读到注释开始符
cout << "这里有注释" << endl;
while( !(*(code+order)=='*'&&*(code+order+1)=='/') ) //忽略注释内容,直到读到注释结束符
order++;
break;
default:
cout << "<" << symbol << "," << token << ">" << endl;
}
}while(*(code+order)!='#');
}
int main(){
char code[code_size];
cout << "请输入程序段,回车换行,输入#完成输入" << endl;
input_code(code);
judge(code);
system("pause");
return 0;
}
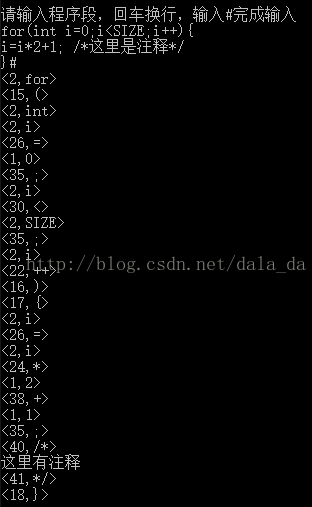
最后
以上就是昏睡金针菇最近收集整理的关于简单的词法分析器的实现的全部内容,更多相关简单内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复