对于图像分类问题,我们可以采用函数的方式来解决。函数的输入是图像个像素的值,输出是每个每个类别可能的值。所以我们有多少个类别就有多少个函数,函数我们采用线性函数,同时在每个函数上增加一个偏置项,也就是常数,函数的形式便为:f(x) = wx + b ,我们每个类别的函数整合在一起,使用矩阵的方式来表示: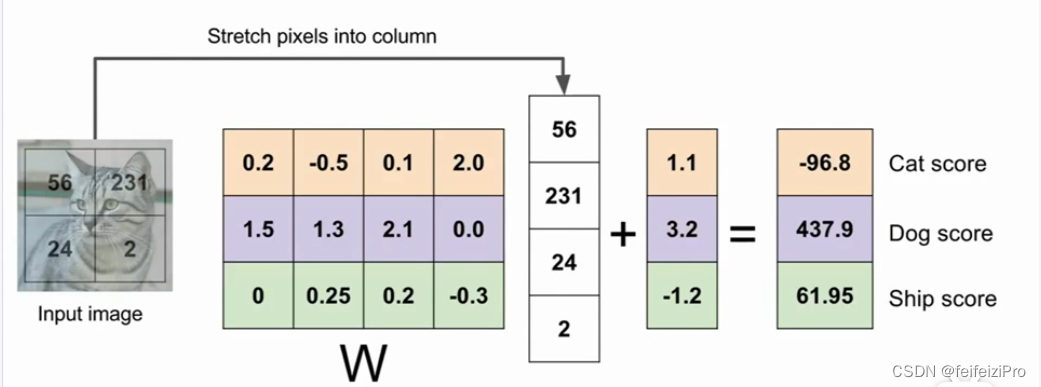
这就是一个图像的线性分类器。
那我这个权值w我们要取多少呢?我们的最终目的是得到输入图像的正确类别,所以我要设置一个损失函数L,去计算我们现在的w和目标之间的差距,差距越大,代表w越不好,通过损失函数L去调整w,得到一个L值最小的w。
这里我们使用SVM损失函数,对于一个3类别3样本的训练集来说,损失函数L=(第一个样本通过线性分类器得到了3个值,取这个样本真实类别对应的值Yi与另外两个值Yj和Yk比较,如果Yi >= Yj + 1(1可以取其他值,代表运行的误差范围)则加0,否则加Yi-Yj+1,Yi和Yk也一样比较 + 第二个样本······)/ 样本数

还有一种损失函数是softmax,它是通过求正确类别占总共类别的权重得到正确类别的概率,概率越大,损失函数越小,为1,softmax为0;概率越小,损失函数越大,为0,softmax为正无穷(概率为1和为0在实际计算中不可能出现)。
同时,为了避免过拟合,我们会在损失函数后面再加一项正则项 ,常见的是L2范数,将所有权重开平方求和,还有L1范数,将所有权重取绝对值求和。
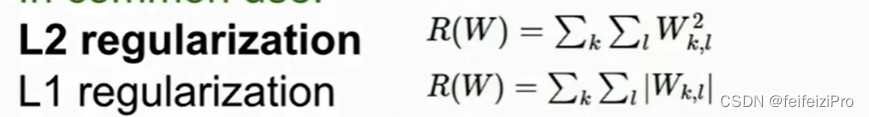
因为要让损失函数最小化,所以范数也要很小,从而避免权重w过大,得到函数f(x)也会相对简单。L2范数因为开平方,会导致w中大的数会更大,所以L2范数倾向于选择普遍都较小的数,而L1范数则会选择0较多的w。例如,w1=(5,0,0),w2=(2,2,2),L1会选择w1,L2则会选择w2。
更新权重w的方法,我们采用梯度下降的算法,通过对w中的每一个元素求梯度,再向梯度的逆方向更新(梯度的正方向是增加,逆方向减少)。每次更新的值=学习率x梯度,学习率是自己手动设置的一个参数,设置过大,一次更新太多直接跳过了最低点,设置过小,一次更新太少到达最低点又很慢,要选择一个适中的值。
最后
以上就是想人陪发卡最近收集整理的关于斯坦福cs231n计算机视觉笔记(2)线性分类器的全部内容,更多相关斯坦福cs231n计算机视觉笔记(2)线性分类器内容请搜索靠谱客的其他文章。








发表评论 取消回复