K最近邻(k-Nearest Neighbor,KNN)分类算法
1、KNN的基本思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
2、用处:KNN算法不仅可以用于分类,还可以用于回归。通过找出一个样本的k个最近邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本的属性。更有用的方法是将不同距离的邻居对该样本产生的影响给予不同的权值(weight),如权值与距离成正比(组合函数)。
3、缺点:该算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。 该算法只计算“最近的”邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。
可以采用权值的方法(和该样本距离小的邻居权值大)来改进。该方法的另一个不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。
目前常用的解决方法是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
4、形象表述
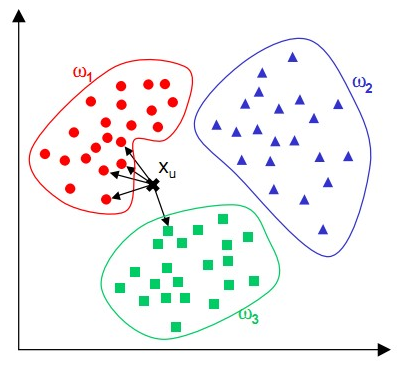
K-NN可以说是一种最直接的用来分类未知数据的方法。直白地说,有一堆已知分类的数据,然后当一个新数据进入的时候,就开始跟训练数据里的每个点求距离,然后挑出离这个训练数据最近的K个点,看看这几个点属于什么类型,然后用少数服从多数的原则,给新数据归类。这里所说的距离,一般最常用的就是多维空间的欧式距离。这里的维度指特征维度,即样本有几个特征就属于几维。如下图:
5、算法流程
(1)初始化距离为最大值;(2)计算未知样本和每个训练样本的距离dist;(3)得到目前K个最临近样本中的最大距离maxdist;(4)如果dist小于maxdist,则将该训练样本作为K-最近邻样本;(5)重复步骤2、3、4,直到未知样本和所有训练样本的距离都算完;(6)
统计K-最近邻样本中每个类标号出现的次数;(7)选择出现频率最大的类标号作为未知样本的类标号。
6、实现例程的链接
http://blog.csdn.net/queyuze/article/details/70195087
http://blog.csdn.net/xlm289348/article/details/8876353
cs231n 课程的课程作业
1、载入数据集
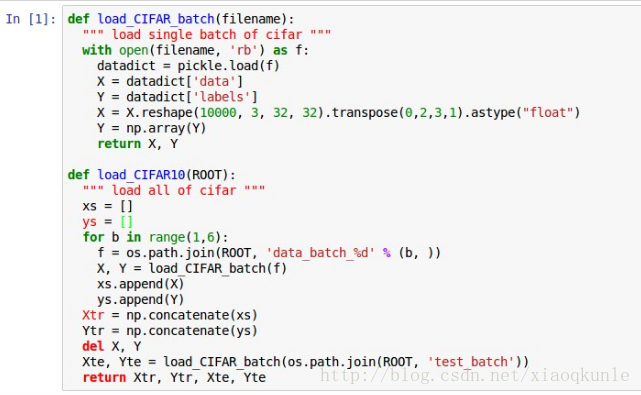
这里选用的数据集是 cifar-10 数据集,http://www.cs.toronto.edu/~kriz/cifar.html
输出相应的训练集和测试集数据 Xtr, Ytr, Xte, Yte
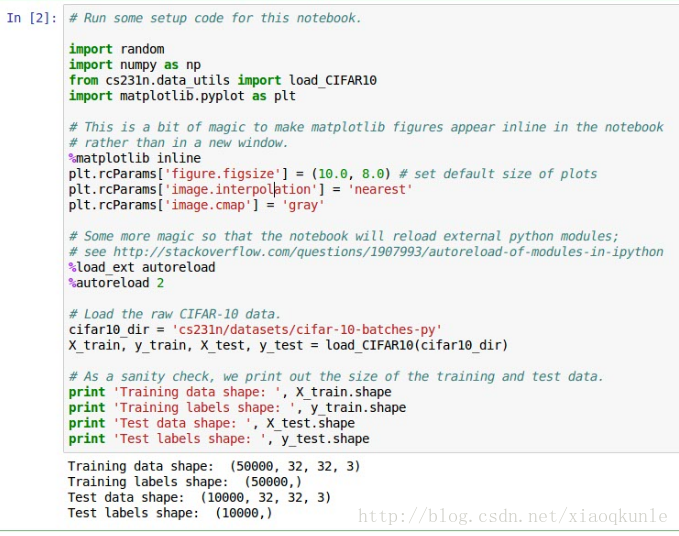
2、载入数据集的调用及结果显示
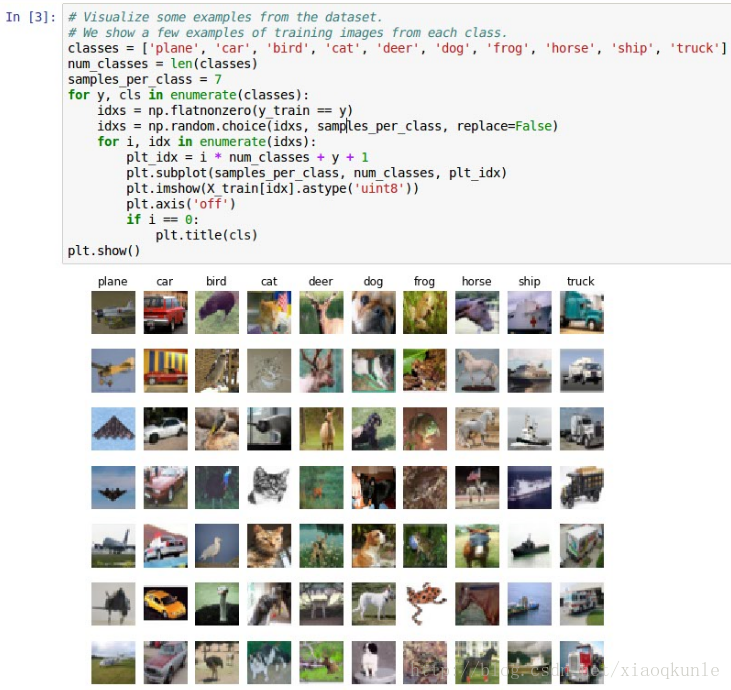
3、显示数据集的一部分信息
4、调整数据集大小
5、使用KNN
6、KNN本质实现部分代码分析
参考链接 http://blog.csdn.net/zhyh1435589631/article/details/54236643 的2.2.3部分
7、测试两层 for 循环对计算测试集与训练集数据之间的欧式距离
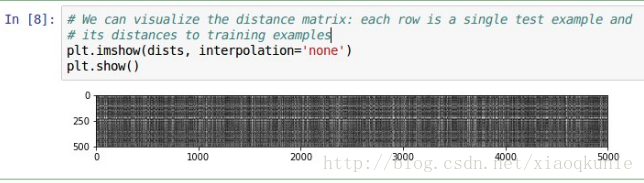
8、对步骤7的测试结果图形化显示
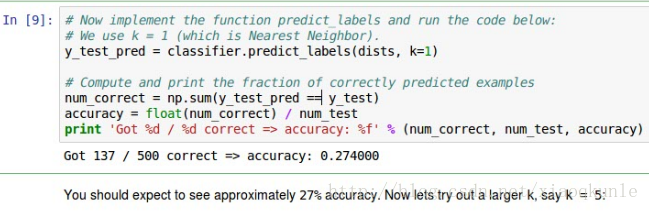
9、使用KNN进行训练,K=1
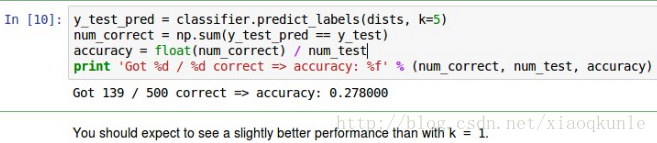
10、修改K的参数,再次进行训练,K=5
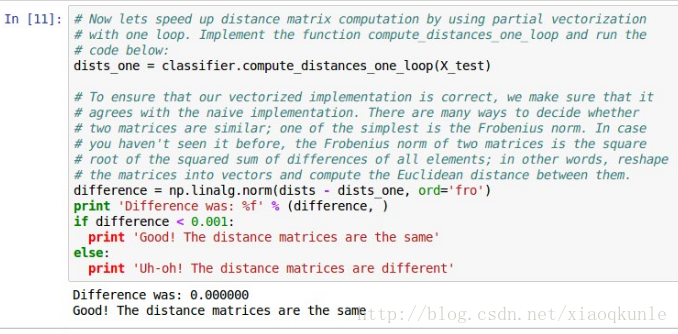
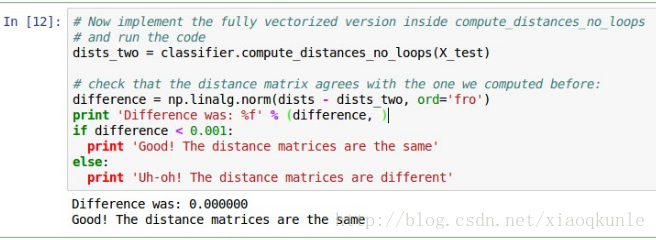
11、验证其他两种计算距离的方式——结果是一致的
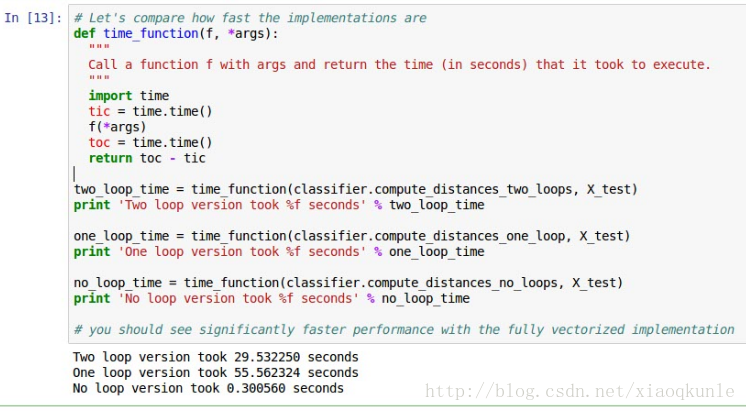
12、对比不同方式的运行时长——应使用矩阵减少运行时间
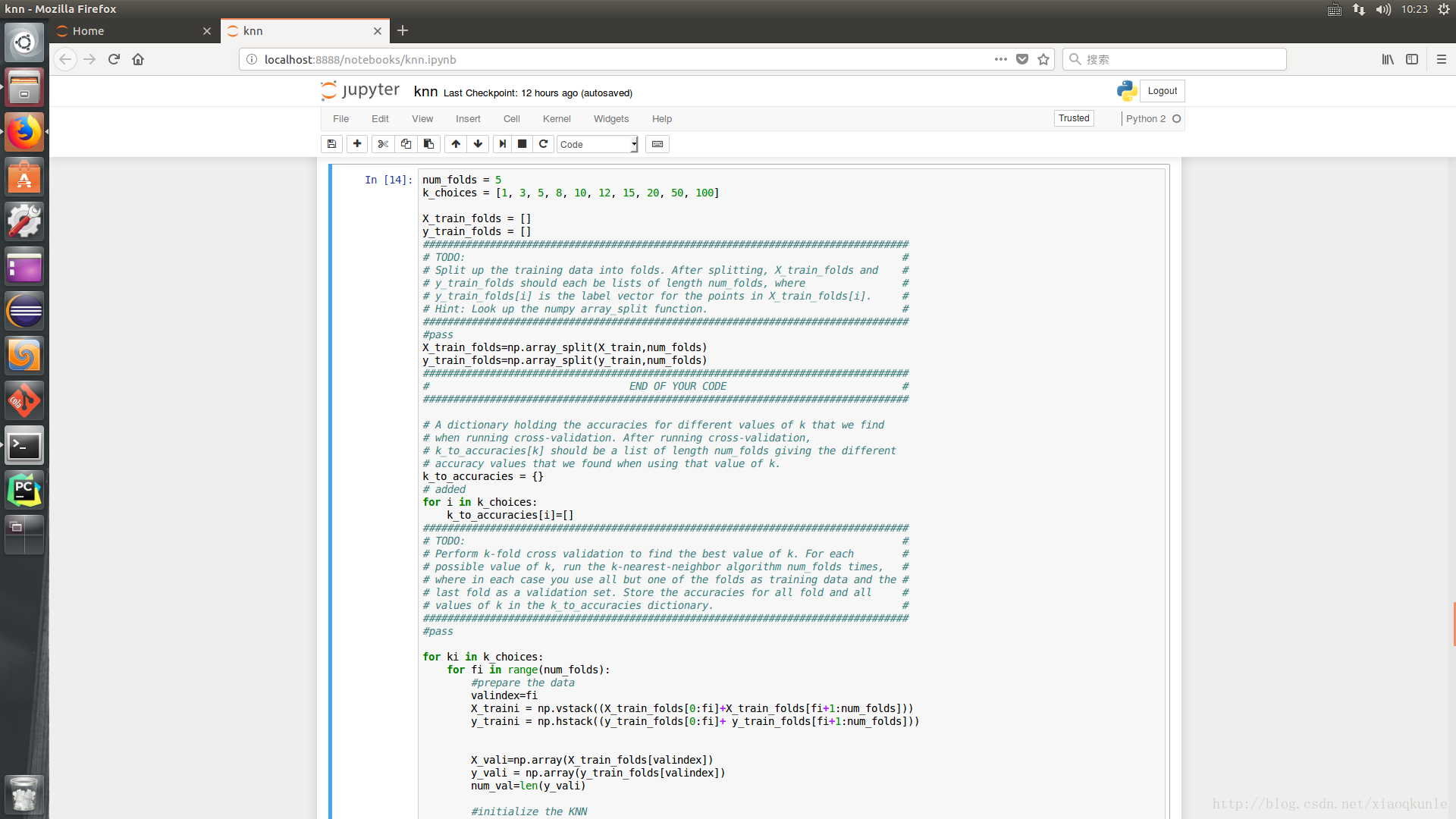
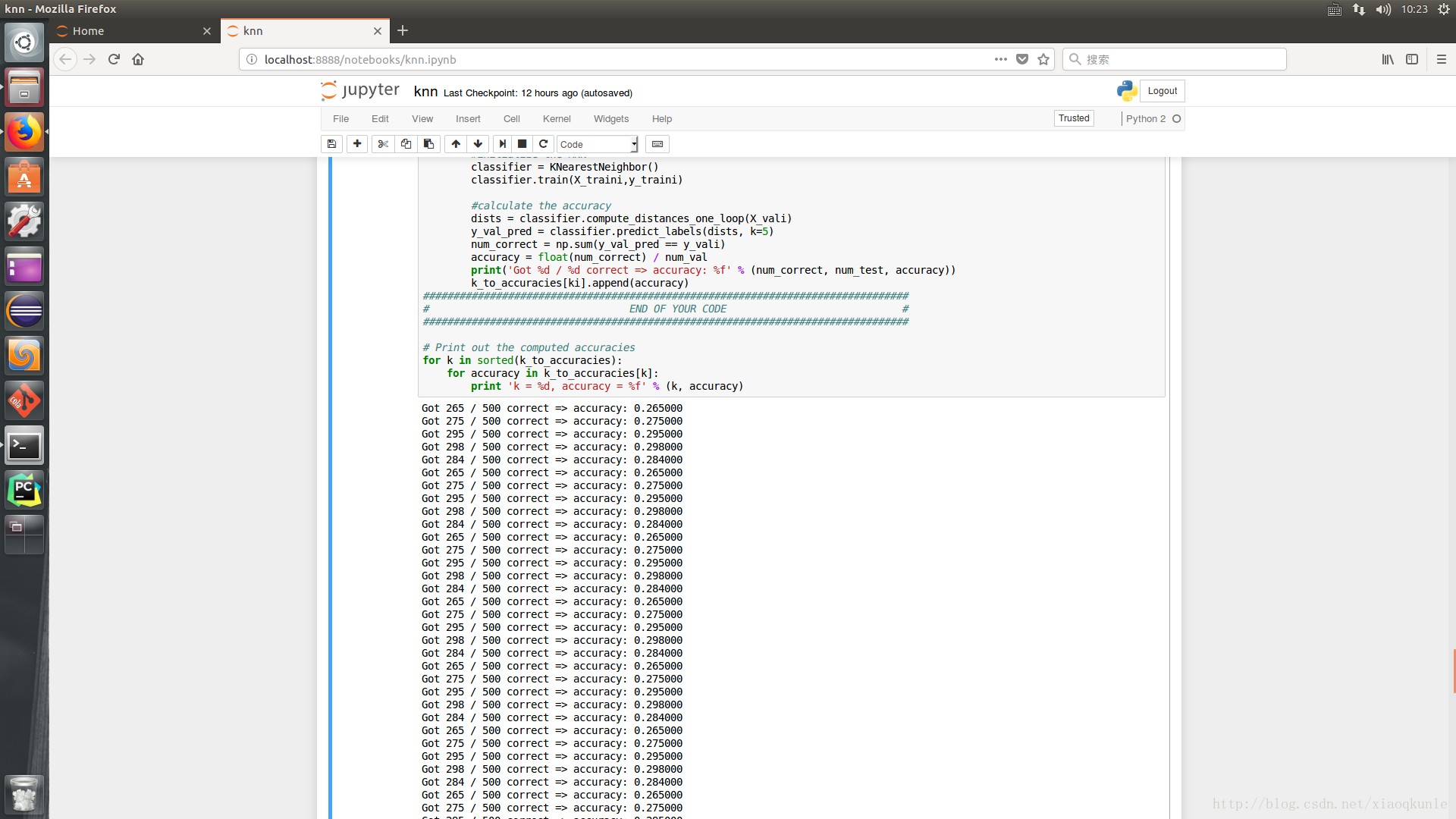
13、筛选不同的K
14、图形化显示
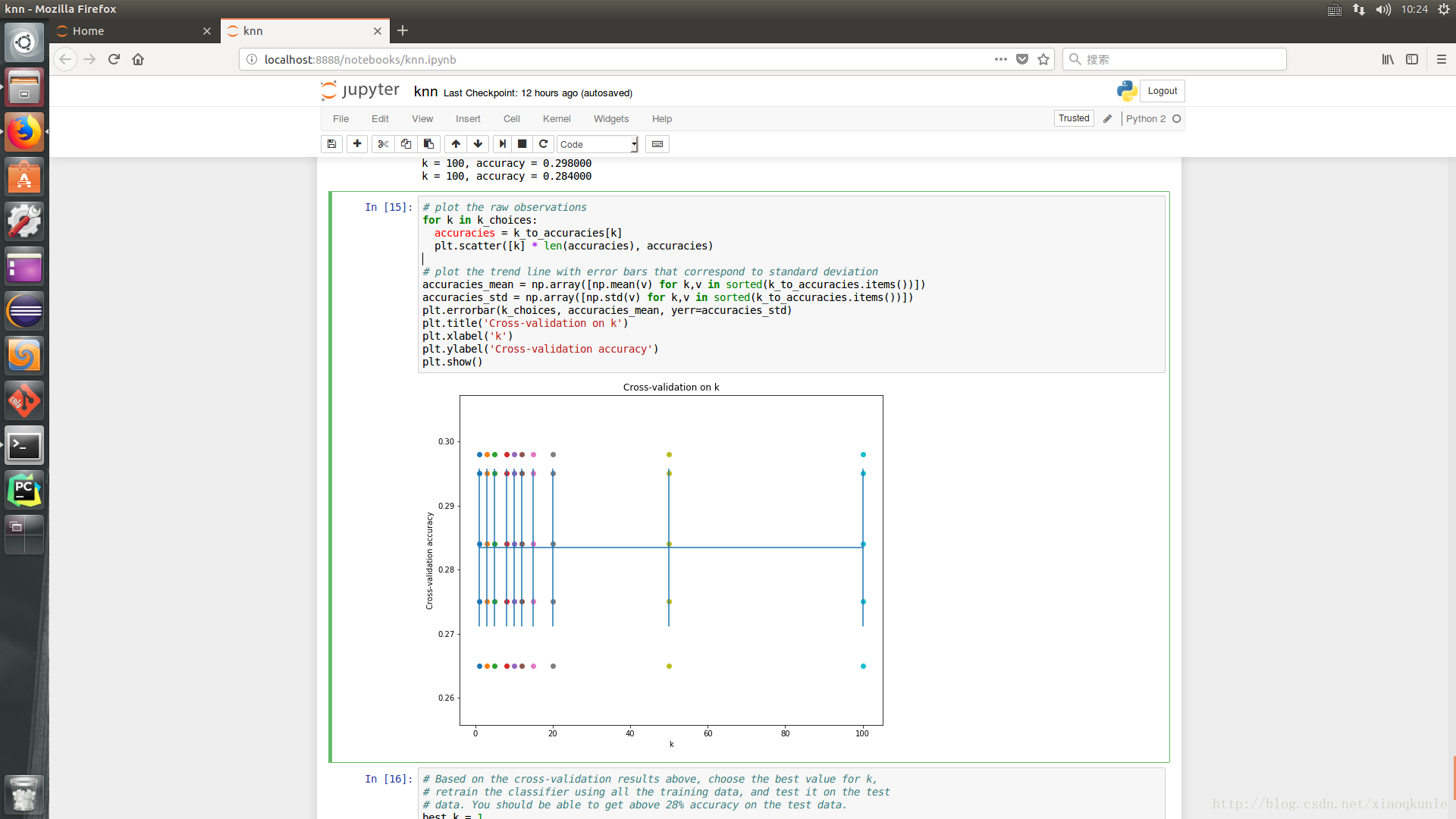
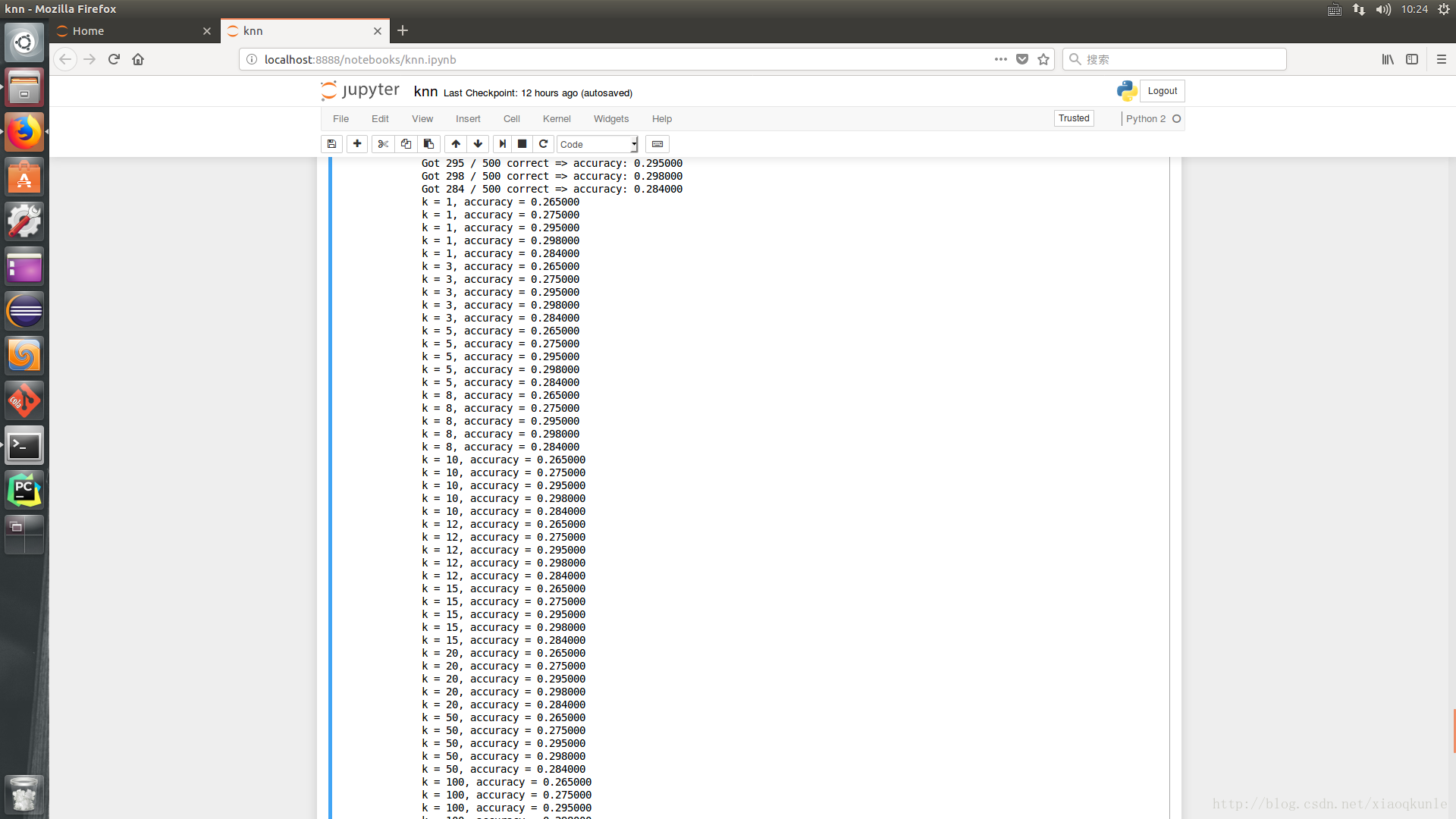
15、选取最优K值
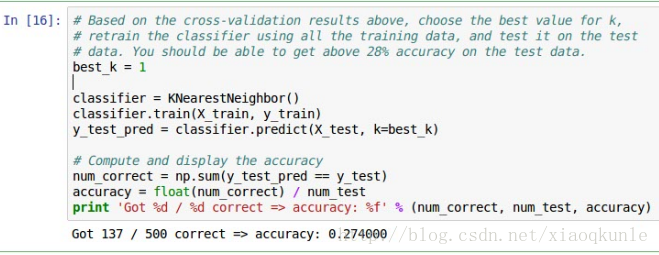
最后
以上就是默默水蜜桃最近收集整理的关于KNN最近邻分类算法 + cs231n assignment1的全部内容,更多相关KNN最近邻分类算法内容请搜索靠谱客的其他文章。








发表评论 取消回复