提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
神经网络数学基础
- 介绍
- 一、初识神经网络
- 1.导入数据
- 2.网络架构
- 3.编译步骤
- 4.准备图像数据和标签
- 5.训练过程
- 二、神经网络的数据表示
- 1.什么是张量
- 2.张量关键属性
- 三、张量计算
- 1.逐个元素计算
- 2.广播计算
- 3.点积计算
- 4.张量变形
- 四、基于梯度的优化
- 1.神经网络优化过程
- 2.随机梯度下降
- 3.反向传播算法
- 总结
介绍
本章根据一个基础的神经网络示例,引出张量和梯度下降的概念,帮助初学者初步理解神经网络的工作原理
提示:以下是本篇文章正文内容,下面案例可供参考
一、初识神经网络
初识神经网络采用的例子是手识别手写数字,这个例子在神经网络中的经典程度相当于程序入门的hello world。这个例子中我们用的是mnist数据集,这是一个28像素X28像素的手写数字灰度数据集。这个数据集有6w张训练样本和1w张测试图像组成。
1.导入数据
keras需要tensorflow作为后端才能使用。我的安装包配tensorflow2.2.0+keras2.3.1+python3.7,推荐读者也采用这个配置,不然可能遇到版本不兼容问题。
keres中自带mnist数据集,可以通过代码下载
from keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images 和train_labels 组成了训练集(training set),模型将从这些数据中进行
学习。然后在测试集(test set,即test_images 和test_labels)上对模型进行测试。
图像被编码为Numpy 数组,而标签是数字数组,取值范围为0~9。图像和标签一一对应。
可以通过代码来查看数据,对数据有一个具体的认知
print(train_images.shape)
print(len(train_labels))
pritn(train_labels)
可以对测试集做同样的操作。
2.网络架构
这个项目的具体流程是:首先,将训练数据(train_images 和train_labels)输入神
经网络;其次,网络学习将图像和标签关联在一起;然后,网络对test_images 生成预测,最后验证这些预测与test_labels 中的标签是否匹配。
神经网络基础架构如下:
from keras import models
from keras import layers
network = models.Sequential()
network.add(layers.Dense(512, activation='relu', input_shape=(28 * 28,)))
network.add(layers.Dense(10, activation='softmax'))
keras用来构建神经网络最大的优点是足够简单,Sequential模型是典型的堆叠模型,我们可以把想要的对数据处理过程一层一层堆叠起来。每一层中都包含很多权重(参数),对输入数据根据权重转换,然后输出。
本例中的网络包含2 个Dense 层,它们是密集连接(也叫全连接)的神经层,也是最基础的神经网络层结构。第二层(也是最后一层)是一个10 路softmax 层,它将返回一个由10 个概率值(总和为1)组成的数组。每个概率值表示当前数字图像属于10 个数字类别中某一个的概率(softmax是个基础的概念,在机器学习经典的LR算法中就有用到)。
3.编译步骤
在搭好神经网络基础之后,还需要对模型进行编译
network.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
keras中的compile可以对模型进行编译,编译过程主要是设置三个参数项:优化器(optimizer)、损失函数(loss)、监控项(metrics)。keras中内置了很多的模块可以选择,熟悉神经网络之后可以按照数据特点进行挑选。我们这里只是用比较基础的编译设置做演示。
4.准备图像数据和标签
开始训练之前,我们要对数据做预处理,这么做的好处会在后面的内筒中提到。我们接下来的处理是将一个形状为(60000,28,28),取值为[0,255]的数组转换为(60000,28*28),取值范围了[0,1]的数组。
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape((10000, 28 * 28))
test_images = test_images.astype('float32') / 255
处理完图像之后我们还会对标签进行编码,下一章会详细讲述分类编码的内容
from keras.utils import to_categorical
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
5.训练过程
现在我们准备开始训练网络,在Keras 中这一步是通过调用网络的fit 方法来完成的——
我们在训练数据上拟合(fit)模型。
network.fit(train_images, train_labels, epochs=5, batch_size=128)
Epoch 1/5
60000/60000 [=============================] - 9s - loss: 0.2524 - acc: 0.9273
Epoch 2/5
51328/60000 [=======================>.....] - ETA: 1s - loss: 0.1035 - acc: 0.9692
训练过程中显示了两个数字:一个是网络在训练数据上的损失(loss),另一个是网络在
训练数据上的精度(acc)。
我们很快就在训练数据上达到了0.989(98.9%)的精度。现在我们来检查一下模型在测试
集上的性能。
>>> test_loss, test_acc = network.evaluate(test_images, test_labels)
>>> print('test_acc:', test_acc)
test_acc: 0.9785
在测试集上也达到了了97.8%的精度。
keras可以很方便的帮助初学者搭建神经网络。可能很多读者没有什么基础,但是通过调用keras中集成的各种框架,可以很容易的训练模型,实现想要的功能。在这个例子中我们只用了几行代码,就实现了97+%的精度。
二、神经网络的数据表示
1.什么是张量
上面讲的例子用的数据都是存储在numpy数组中,也叫作张量(tensor)。张量的概念在机器学习领域非常重要,谷歌的深度学习框架tensorflow就是以它来命名的。张量是一个数据容器,是矩阵向任意维度的推广(张量的维度通常叫做轴。矩阵是有两个轴x轴和y轴的张量,所以矩阵是二维张量)。
在numpy中,ndim属性可以查看一个numpy张量轴的个数。
import numpy as np
x = np.array([[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]])
print(x.ndim)
通过这段代码我们可以看到矩阵的张量轴确实有2个。
2.张量关键属性
张量的关键属性有如下三个:
轴的个数(阶)。例如,3D 张量有 3 个轴,矩阵有 2 个轴。这在 Numpy 等 Python 库中
也叫张量的ndim。
形状。这是一个整数元组,表示张量沿每个轴的维度大小(元素个数)。例如,3D 张量的形状可以是(3, 3, 5),向量的形状只包含一个元素,比如(5,),而标量的形状为空,即()。
数据类型(在 Python 库中通常叫作 dtype)。这是张量中所包含数据的类型,例如,张
量的类型可以是float32、uint8、float64 等。在极少数情况下,你可能会遇到字符
(char)张量。
在numpy中,我们可以通过查看张量的ndim、shape和dtype属性来得到具体的特征数据。以mnist数据集为例:
from keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
print(train_images.ndim)
print(train_images.shape)
print(train_images.dtype)
可以看出mnist数据集是一个3d张量,有6w个矩阵组成,每个矩阵有28*28个整数,每个数都是uint8格式。
张量的其他概念
通常来说,深度学习所有数据张量的第一个轴(0轴,因为索引都是从0开始)都是样本轴。在mnist的例子中,样本就是数字图像。
此外,深度学习模型不会同事处理整个数据集,而是将数据拆分开,分批进行训练。比如我们可以从mnist中获取一批数据
batch = train_images[:128]
对于这种批量的张量,0轴叫做批量轴,这个术语在深度学习教材中经常遇到。
三、张量计算
1.逐个元素计算
在深度学习当中,relu计算(relu函数是神经网络中经典的激活函数,公式为y = max(0,x))和加减法计算是典型的逐个元素计算,在numpy中可以直接实现逐个元素计算,经过内部优化,这类基础计算速度很快。
import numpy as np
z = x + y
z = np.maximum(z,0.)
2.广播计算
当两个张量的形状相同时,进行加减计算都是很容易的,但是有时候不同形状的张量也会遇到加减计算,这个时候,就要对小的张量进行广播,匹配大的张量的形状。
广播包含以下两部
向较小的张量添加轴,使其ndim与较大的张量相同。
将较小的张量沿着新轴重复,使其形状与较大的张量相同。
import numpy as np
x = np.random.random((64, 3, 32, 10))
y = np.random.random((32, 10))
z = np.maximum(x, y)
可见输出的z的形状与x的形状是相同的。
3.点积计算
点积运算,也叫张量积(tensor product,不要与逐元素的乘积弄混),是最常见也最有用的
张量运算。与逐元素的运算不同,它将输入张量的元素合并在一起。在Numpy 和Keras 中,都是用标准的dot 运算符来实现点积。
import numpy as np
z = np.dot(x, y)
最基础的点积是两个向量之间的点积,详细的运算过程如下:
def naive_vector_dot(x, y):
assert len(x.shape) == 1
assert len(y.shape) == 1
assert x.shape[0] == y.shape[0]
z = 0.
for i in range(x.shape[0]):
z += x[i] * y[i]
return z
当然了,张量点积也有不对称点积,比如矩阵x和向量y做点积,返回值将是一个向量,每个元素是y和x的每一行之间的点积。
import numpy as np
def naive_matrix_vector_dot(x, y):
assert len(x.shape) == 2
assert len(y.shape) == 1
assert x.shape[1] == y.shape[0]
z = np.zeros(x.shape[0])
for i in range(x.shape[0]):
for j in range(x.shape[1]):
z[i] += x[i, j] * y[j]
return z
4.张量变形
张量变形是改变张量的行和列,以得到想要的形状。变形之后的张量的元素个数和初始张量相同。
>>> x = np.array([[0., 1.],
[2., 3.],
[4., 5.]])
>>> print(x.shape)
(3, 2)
>>> x = x.reshape((6, 1))
>>> x
array([[ 0.],
[ 1.],
[ 2.],
[ 3.],
[ 4.],
[ 5.]])
>>> x = x.reshape((2, 3))
>>> x
array([[ 0., 1., 2.],
[ 3., 4., 5.]])
最常用的张量变形是转置,矩阵转置是矩阵操作中很常用的操作。对矩阵的转置是将行和列互换,使x[i, :]变为x[:, :i]。
>>> x = np.zeros((300, 20))
>>> x = np.transpose(x)
>>> print(x.shape)
(20, 300)
四、基于梯度的优化
1.神经网络优化过程
在上节的第一个神经网络示例中,每个神经层都用relu方法来对输入数据进行变换:
output = relu(dot(w,input)+ b)
w和b都是层的权重。一开始这些权重都是随机初始化的。权重初始化之后我们可以根据损失函数计算出预测值与实际值之间的距离,然后根据反向传播去优化权重。反向传播中,有两个重要的概念是可微和梯度。这些都是高等数学中最基本的概念,在书中作者花了很大篇幅来介绍这些东西。不了解的可以看原文或者搜资料了解,本文中不会做过多解释。
2.随机梯度下降
给一个可微函数,理论上是可以找到他的最小值:函数的最小值是导数为0的点。将这个理论用到神经网络当中,就是求出损失函数导数为0的点,这个点就是损失函数最小的点。这个点对应的权重就是神经网络的最优权重。
在神经网络中,通常用这五步来寻找最小值。
(1) 抽取训练样本x 和对应目标y 组成的数据批量。
(2) 在x 上运行网络,得到预测值y_pred。
(3) 计算网络在这批数据上的损失,用于衡量y_pred 和y 之间的距离。
(4) 计算损失相对于网络参数的梯度[一次反向传播(backward pass)]。
(5) 将参数沿着梯度的反方向移动一点,比如W -= step * gradient,从而使这批数据
上的损失减小一点
随机梯度下降的名字来源于随机获取样本,由于每次训练中只是用一些样本而不是所有的样本,所以梯度下降的计算由随机徐选取的样本决定(随机选取样本是为了节约计算资源,随机抽取对象理论上属性和全体数据的分布是一致的)。
实际上寻找最小值是一个很难的过程,一直以来也有很多的优化方法来进行寻找。因为除了全局最小值以外,还会有局部最小值,如何寻找到全局最小值而不是局部最小值是很有挑战性的工作。
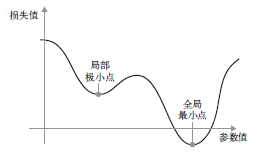
3.反向传播算法
在神经网络中,多层计算实质就是许多个连在一起的张量计算,每个运算都有导数。比如下面的三层计算
f(W1, W2, W3) = a(W1, b(W2, c(W3)))
根据微积分的链式法则:(f(g(x)))’ = f’(g(x)) * g’(x)。将链式法则应用到神经网络中就是返现传播算法。
tensorflow之类的现代框架实现神经网络,框架可以自动进行微分求导操作,对于神经网络计算可以很方便实现。
总结
本文介绍了神经网络的基本概念,实现了一个简单的神经网络,在此基础上引出并介绍了张量、梯度下降和反向传播等神经网络的概念,读完之后对于神经网络能有初步的概念和了解。
最后
以上就是羞涩红牛最近收集整理的关于keras之父《python深度学习》笔记 第二章介绍一、初识神经网络二、神经网络的数据表示三、张量计算四、基于梯度的优化总结的全部内容,更多相关keras之父《python深度学习》笔记内容请搜索靠谱客的其他文章。








发表评论 取消回复