这一章详细讲解编码过程
那么接下来就是码代码了,GO
新建NetCore WebApi项目 空的就可以
NuGet安装
Install-Package AngleSharp
或者界面安装
using。。
默认本地装有mysql或者有远程开放的mysql数据库,如何安装mysql,园区有很多文章都详细说明。
配置文件添加mysql连接 appsettings.json
{"Logging": {"LogLevel": {"Default": "Warning"}
},"AllowedHosts": "*","ConnectionStrings": {"MySql": "server=localhost;user id=root;pwd=root;database=dreaminfo;"}
}
新建实体类,这里由于比较简单,所以创建到一起,实际工作中最好不要这样,可读性较差
usingSystem;usingSystem.Collections.Generic;usingSystem.ComponentModel.DataAnnotations;usingSystem.ComponentModel.DataAnnotations.Schema;usingSystem.Linq;usingSystem.Threading.Tasks;namespaceWebAPI.Models
{public classDream
{
[Key, DatabaseGenerated(DatabaseGeneratedOption.Identity)]public int Id { get; set; }public string Name { get; set; }public string Url { get; set; }public string Summary { get; set; }public string CateName { get; set; }public DateTime? CreateTime { get; set; }
}public classDreamInfo
{
[Key, DatabaseGenerated(DatabaseGeneratedOption.Identity)]public int Id { get; set; }public int FkDreamId { get; set; }public string DreamName { get; set; }public string Name { get; set; }public string Content { get; set; }public DateTime? CreateTime { get; set; }
}
}
安装,mysql的ef支持
Install-Package Pomelo.EntityFrameworkCore.MySql
创建DBContext
usingMicrosoft.EntityFrameworkCore;usingSystem;usingSystem.Collections.Generic;usingSystem.Linq;usingSystem.Threading.Tasks;namespaceWebAPI.Models
{public classMainDBContext : DbContext
{public MainDBContext(DbContextOptions options) : base(options)
{
}private stringconnection;public MainDBContext(string connection) => this.connection =connection;protected override voidOnConfiguring(DbContextOptionsBuilder optionsBuilder)
{if (!string.IsNullOrWhiteSpace(connection))
optionsBuilder.UseMySql(connection);
}public DbSet Dream { get; set; }public DbSet DreamInfo { get; set; }
}
}
配置服务
public voidConfigureServices(IServiceCollection services)
{var mysqlCon = Configuration.GetSection("ConnectionStrings:MySql").Value;
services.AddDbContext(l => l.UseMySql(mysqlCon, b => b.MigrationsAssembly("Dream"))); //跳转查看
services.AddMvc().SetCompatibilityVersion(CompatibilityVersion.Version_2_1);
}
然后是数据库迁移 ,这里使用的是codefirst,所以创建好实体类之后在实体类及EF存在的程序集执行Add-Migration命令,我这里做的比较简单,有的如果是按照框架来设计,可能实体类被设计在单独的类库里
这里是直接在webapi里面
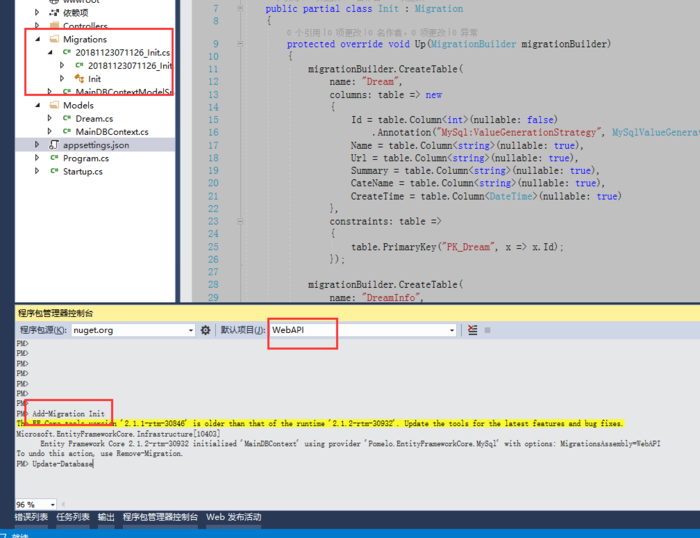
执行之后会多出来迁移的的文件,然后执行Update-Database就可以生成数据库拉。
后期如果数据库有变更还是同样的操作
工具》打开Nuget包管理器》程序包管理控制台 选中EF所在类库
Add-Migration Update-20181123
//然后等待变更文件生成之后执行
Update-Database
然后我们看下数据库
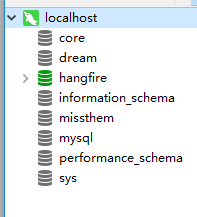
我们刷新下,数据库和对应的表都有了。
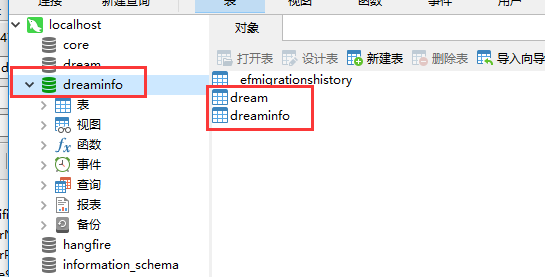
获取页面内容
新建一个空的API控制器DreamController
然后创建获取类别数据的方法
///
///定义一个获取列表数据的方法,需要传递一个列表页面的url地址///
///
public void GetData(stringurl)
{//这个跟我之前使用的浏览器驱动类似,也是通过选择器和xpath来爬取数据//区别在于那个是模拟真人操作,这个是通过通过HttpWebRequest直接请求
var html =GetHtml(url);//创建一个(可重用)解析器前端
var parser = newHtmlParser();var document =parser.Parse(html);//找到一个页面有多少个dream信息
var mengList = document.QuerySelectorAll("#list > div.main > div.l-item > ul > li");//循环获取梦的信息
for (var i = 0; i < mengList.Length; i++)
{var meng = newDream();
meng.CateName= "人物";//名称
meng.Name = mengList[i].QuerySelector("h3 > a").TextContent;//简介
meng.Summary = mengList[i].QuerySelector("p").TextContent;//连接
meng.Url = mengList[i].QuerySelector("h3 > a").GetAttribute("href");
meng.CreateTime=DateTime.Now;
_context.Dream.Add(meng);
_context.SaveChanges();//可以单个保存,也可以获取当前页数据之后保存一次,可优化的点有很多,这里不再详细描述
}
}
但是这里获取的都是单页的数据,我们继续上一章说的,使用选择器里面的.next来寻找翻页按钮附带的连接
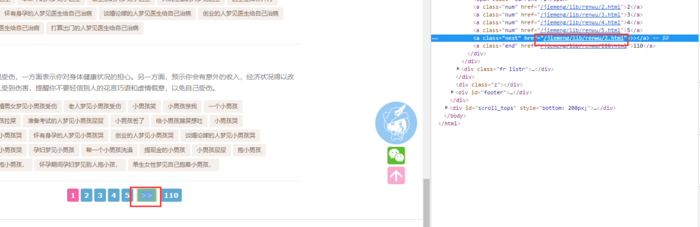
然后看看最后一页是什么样式
发现最后一页就没有下一页样式了,就获取不到值了,好的 那么我们开始翻页
至于翻页 还有第二种思路,就是直接获取这种类别下的最后一页的页码,然后循环就行了,似乎比较简单,我们就用这一种
完善后的方法
///
///定义一个获取列表数据的方法,需要传递一个列表页面的url地址///
///
public void GetData(string url, intpageIndex)
{var thisUrl = url + pageIndex + ".html";var html =GetHtml(thisUrl);//创建一个(可重用)解析器前端
var parser = newHtmlParser();var document =parser.Parse(html);var mengList = document.QuerySelectorAll("#list > div.main > div.l-item > ul > li");//#list > div.main > div.pagelist > a.end//获取最末页数据
if (!PageEnd.HasValue)
{var pageEnd = document.QuerySelector("#list > div.main > div.pagelist > a.end")?.TextContent;
PageEnd=Convert.ToInt32(pageEnd);
}var list = new List();for (var i = 0; i < mengList.Length; i++)
{var meng = newDream();
meng.CateName= "其他";//名称
meng.Name = mengList[i].QuerySelector("h3 > a").TextContent;//简介
meng.Summary = mengList[i].QuerySelector("p").TextContent;//连接
meng.Url = mengList[i].QuerySelector("h3 > a").GetAttribute("href");
meng.CreateTime=DateTime.Now;
_context.Dream.Add(meng);
_context.SaveChanges();
}//翻页记录页码
pageIndex++;if (pageIndex <=Convert.ToInt32(PageEnd))
{
Console.WriteLine(pageIndex+ "/" +PageEnd);//翻页完之前一直抓取
GetData(url, pageIndex);
}
}
定义接口,输出一下看看获取了多少页的数据
PageEnd是在控制器里面定义的
public classDreamController : ControllerBase
{static int? PageEnd = null;//other code
[HttpGet]public async TaskGetMengXinfo()
{
GetData("http://www.xzw.com/jiemeng/lib/renwu/", 1);returnOk(PageEnd);
}
调试走一波
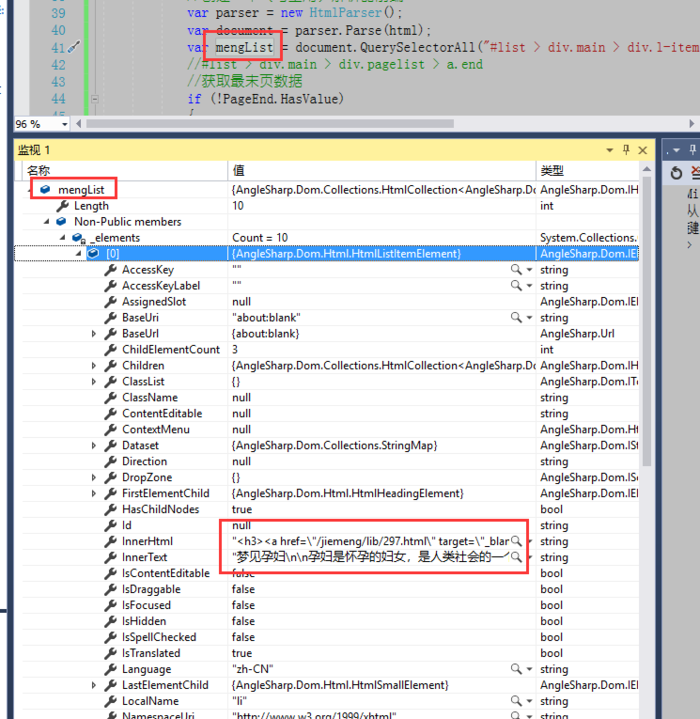
可以看到这里数据其实已经拿到了,那我们就开始往数据库保存
由于是演示,我们找一个数据量较少的分类来获取 使用“其他”分类获取,调用接口,看到返回值是45
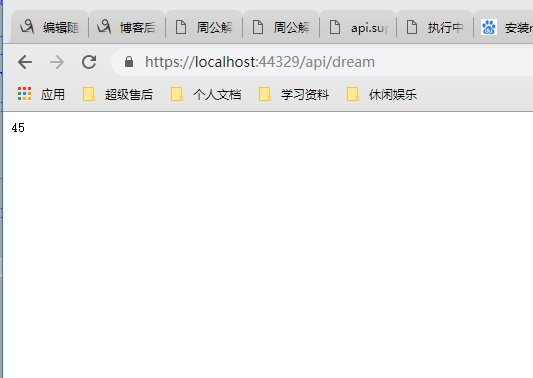
这个跟我们找到对应的数据是一样的

说明数据是ok的,我们看下数据库,dream表已经有数据了

到这里 分类数据就获取到了,其他几个分类 可以使用一个数组,循环数组拼连接获取,也可以放到后台任务慢慢执行,比如Hangfire
详细信息获取
详细信息的页面我们其实是有的,就是dream表里面的url字段,拼接上domain之后就成了详细页面的连接,我们又可以使用AngleSharp来获取数据拉。。
其实AngleSharp是对获取到的文档进行解析,里面构建了很多C#和js习惯的语法,比如
document.QuerySelector(选择器)//选择器查询单个符合条件的数据
document.QuerySelectorAll("#list > div.main > div.l-item > ul > li");获取复合条件的元素集合
获取详情页面内容,并给实体对象赋值,这里有很多可以试探的方法,大家可以尝试一下,我这个只是简单的为了完成我想要的功能。
///
///获取详情页的页面解析///
///
///
public void GetDetailData(int dreamId, stringurl)
{var html =GetHtml(url);var parser = newHtmlParser();var document =parser.Parse(html);//#wraper > div.main-wrap > div.pleft.fl > div.viewbox.box > div.sbody
var sbody = document.QuerySelector("#wraper > div.main-wrap > div.pleft.fl > div.viewbox.box > div.sbody");var dllist = sbody.QuerySelectorAll("dl");var title = sbody.QuerySelector("h2").TextContent;//标题
if (dllist.Length > 0)
{foreach (var detail indllist)
{//#wraper > div.main-wrap > div.pleft.fl > div.viewbox.box > div.sbody > dl:nth-child(4) > dt > strong
var info = newDreamInfo();
info.FkDreamId=dreamId;
info.DreamName=title;
info.Name= detail.QuerySelector("dt > strong").TextContent;
info.Content= detail.QuerySelector("dd").TextContent; ;
info.CreateTime=DateTime.Now;
_context.DreamInfo.Add(info);
_context.SaveChanges();
}
}
}
定义接口
[Route("detail")]
[HttpGet]public async TaskGetDreamInfo()
{var domain = "http://www.xzw.com";//查询出其他分类的梦数据来解析详细内容
var dreamList = _context.Dream.Where(l => l.CateName == "其他").ToList();foreach (var dream indreamList)
{
GetDetailData(dream.Id, domain+dream.Url);
}returnOk(PageEnd);
}
执行接口https://localhost:44329/api/dream/detail
这里不展示调试信息了,怕被说水内容
然后看数据库dreaminfo也有了数据

找到对应页面

到这里,数据基本都可以获取到了,其他分类可以做计划任务来获取数据
总结
对自己感兴趣的东西,可能下决心投入的时间会更长一点,共勉。
排版较乱可能影响阅读,不过内容还是能看到的。。
GitHub:https://github.com/ermpark/dream.git
最后
以上就是文艺饼干最近收集整理的关于database2sharp mysql_C# NetCore使用AngleSharp爬取周公解梦数据 MySql数据库的自动创建和页面数据抓取...的全部内容,更多相关database2sharp内容请搜索靠谱客的其他文章。








发表评论 取消回复