PL/SQL, the Oracle procedural extension(程序上的扩展) of SQL, is a portable, high-performance transaction-processing language(是一种可移植、高性能事务处理语言。).
This chapter explains(说明) its advantages and briefly describes(简要描述) its main features and its architecture(体系结构).
Topics
■ Advantages of PL/SQL
■ Main Features of PL/SQL
■ Architecture of PL/SQL
Advantages of PL/SQL
PL/SQL has these advantages:
■ Tight Integration(高度集成) with SQL
■ High Performance
■ High Productivity(高生产力)
■ Portability(可移植性)
■ Scalability(可扩展性)
■ Manageability(可管理性)
■ Support for Object-Oriented Programming(面向对象程序设计)
Tight Integration with SQL
PL/SQL is tightly integrated with SQL, the most widely(广泛) used database manipulation language(数据库操纵语言).
For example:
■ PL/SQL lets you use all SQL data manipulation, cursor control, and transaction control statements, and all SQL functions, operators, and pseudocolumns.
■ PL/SQL fully supports(完全支持) SQL data types.
You need not convert between PL/SQL and SQL data types. For example, if your PL/SQL program retrieves(检索) a value from a column of the SQL type VARCHAR2, it can store that value in a PL/SQL variable of the type VARCHAR2.
You can give a PL/SQL data item(数据项) the data type of a column or row of a database table without explicitly specifying(显示指定) that data type (see “%TYPE Attribute” on page 1-7 and “%ROWTYPE Attribute” on page 1-7).
■ PL/SQL lets you run a SQL query and process the rows of the result set one at a time (see “Processing a Query Result Set One Row at a Time” on page 1-8).
■ PL/SQL functions can be declared and defined in the WITH clauses of SQL SELECT statements (see Oracle Database SQL Language Reference).
PL/SQL supports both static and dynamic SQL.
Static SQL is SQL whose full text is known at compile time(编译时刻).
Dynamic SQL is SQL whose full text is not known until run
time.
Dynamic SQL lets you make your applications more flexible and versatile(灵活性和通用性).
For more information, see Chapter 6, “PL/SQL Static SQL” and Chapter 7, “PL/SQL Dynamic SQL”.
High Performance
PL/SQL lets you send a block of statements to the database, significantly(显著地) reducing traffic(通信量) between the application and the database.
Bind Variables
When you embed(嵌入) a SQL INSERT, UPDATE, DELETE, MERGE, or SELECT statement directly(直接地) in your PL/SQL code, the PL/SQL compiler turns(转换) the variables in the WHERE and VALUES clauses into bind variables (for details, see “Resolution of Names in Static SQL Statements” on page B-5).
Oracle Database can reuse(再使用) these SQL statements each time the same code runs, which improves performance.
PL/SQL does not create bind variables automatically when you use dynamic SQL, but you can use them with dynamic SQL by specifying them explicitly(显示指定绑定变量) (for details, see “EXECUTE IMMEDIATE Statement” on page 7-2).
Subprograms
PL/SQL subprograms are stored in executable form(可执行格式), which can be invoked repeatedly(反复调用).
Because stored subprograms run in the database server, a single invocation over the network(通过网络调用) can start a large job.
This division(分工) of work reduces network traffic(减少网络流量) and improves response times(提高响应时间). Stored subprograms are cached and shared among users(在用户之间),
which lowers memory requirements(降低内存需求) and invocation overhead(调用开销).
For more information about subprograms, see “Subprograms” on page 1-5.
Optimizer(优化器)
The PL/SQL compiler has an optimizer that can rearrange code for better performance(重新整理代码为了较好的性能).
For more information about the optimizer, see “PL/SQL Optimizer” on page 12-1.
High Productivity
PL/SQL lets you write compact code(简洁代码) for manipulating data(操纵).
Just as a scripting language(脚本) like PERL can read, transform(转换), and write data in files, PL/SQL can query, transform, and update data in a database.
PL/SQL has many features that save designing and debugging time, and it is the same in all environments.
If you learn to use PL/SQL with one Oracle tool, you can transfer your knowledge to other Oracle tools.
For example, you can create a PL/SQL block in
SQL Developer and then use it in an Oracle Forms trigger.
For an overview of PL/SQL features, see “Main Features of PL/SQL” on page 1-3.
Portability
You can run PL/SQL applications on any operating system and platform where Oracle Database runs.
Scalability
PL/SQL stored subprograms increase scalability by centralizing application processing(集中应用程序处理) on the database server.
The shared memory facilities(共享存储设备) of the shared server let Oracle Database support thousands of concurrent users(并发用户数) on a single node(单一结点).
For more information about subprograms, see “Subprograms” on page 1-5.
For further scalability, you can use Oracle Connection Manager to multiplex network connections.
For information about Oracle Connection Manager, see Oracle Database Net Services Reference.
Manageability
PL/SQL stored subprograms increase manageability because you can maintain only one copy of a subprogram, on the database server, rather than one copy on each client system. Any number of(许多) applications can use the subprograms, and you can change the subprograms without affecting the applications that invoke them.
For more information about subprograms, see “Subprograms” on page 1-5.
Support for Object-Oriented Programming
PL/SQL supports object-oriented programming with “Abstract Data Types”(抽象数据类型) on page 1-7.
Main Features of PL/SQL
PL/SQL combines the data-manipulating power(数据操纵能力) of SQL with the processing power(处理能力) of procedural languages.
When you can solve a problem with SQL, you can issue SQL statements from your PL/SQL program(你可以从PL / SQL程序中发出SQL语句), without learning new APIs.
Like other procedural programming languages, PL/SQL lets you declare constants(常量) and variables, control program flow, define subprograms, and trap runtime errors(捕获运行时错误).
You can break complex problems(复杂问题) into easily understandable subprograms, which you can reuse in multiple applications.
Topics
■ Error Handling
■ Blocks
■ Variables and Constants
■ Subprograms
■ Packages
■ Triggers
■ Input and Output
■ Data Abstraction
■ Control Statements
■ Conditional Compilation(条件编译)
■ Processing a Query Result Set One Row at a Time
Error Handling
PL/SQL makes it easy to detect(发现) and handle errors. When an error occurs, PL/SQL raises an exception. Normal execution stops(正常性执行停止) and control transfers(控制传输) to the
exception-handling part of the PL/SQL block.
You do not have to check every operation to ensure that it succeeded, as in a C program.
For more information, see Chapter 11, “PL/SQL Error Handling”.
Blocks
The basic unit of a PL/SQL source program is the block, which groups related declarations and statements.
A PL/SQL block is defined by the keywords DECLARE, BEGIN, EXCEPTION, and END.
These keywords divide(划分) the block into a declarative part, an executable part, and an
exception-handling part.
Only the executable part is required.
A block can have a label.
Example 1–1 shows the basic structure of a PL/SQL block.
For syntax details, see “Block” on page 13-9.
Example 1–1 PL/SQL Block Structure
<< label >> (optional)
DECLARE -- Declarative part (optional)
-- Declarations of local types, variables, & subprograms
BEGIN -- Executable part (required)
-- Statements (which can use items declared in declarative part)
[EXCEPTION -- Exception-handling part (optional)
-- Exception handlers for exceptions (errors) raised in executable part]
END;Declarations are local(局部的) to the block and cease(停止) to exist when the block completes execution, helping to avoid cluttered namespaces(有助于避免凌乱的名称空间) for variables and subprograms.
Blocks can be nested(嵌套的): Because a block is an executable statement, it can appear in another block wherever an executable statement is allowed.
You can submit(提交) a block to an interactive tool(交互式工具) (such as SQL*Plus or Enterprise Manager) or embed(嵌入) it in an Oracle Precompiler(Oracle 预编译程序) or OCI program.
The interactive tool or program runs the block one time.
The block is not stored in the database, and for that reason(因此), it is called an anonymous block(匿名块) (even if it has a label).
An anonymous block is compiled each time it is loaded into(存入) memory, and its compilation has three stages(阶段):
1. Syntax checking: PL/SQL syntax is checked, and a parse tree is generated.
2. Semantic checking: Type checking and further processing(深加工) on the parse tree.
3. Code generation
Note: An anonymous block is a SQL statement.
Variables and Constants
PL/SQL lets you declare variables and constants, and then use them wherever you can use an expression.
As the program runs, the values of variables can change, but the values of constants cannot.
For more information, see “Declarations” on page 2-12 and
“Assigning Values to Variables” on page 2-21.
Subprograms
A PL/SQL subprogram is a named PL/SQL block that can be invoked repeatedly(重复调用).
If the subprogram has parameters, their values can differ for each invocation.
PL/SQL has two types of subprograms, procedures and functions.
A function returns a result.
For more information about PL/SQL subprograms, see Chapter 8, “PL/SQL Subprograms.”
PL/SQL also lets you invoke external programs(外部程序) written in other languages.
For more information, see “External Subprograms” on page 8-50.
Packages
A package is a schema object that groups logically related PL/SQL types, variables, constants, subprograms, cursors, and exceptions.
A package is compiled and stored in the database, where many applications can share its contents.
You can think of a package as an application.
You can write your own packages—for details, see Chapter 10, “PL/SQL Packages.”
You can also use the many product-specific packages that Oracle Database supplies.
For information about these, see Oracle Database PL/SQL Packages and Types Reference.
Triggers
A trigger is a named PL/SQL unit that is stored in the database and run in response(相应) to an event that occurs in the database.
You can specify the event, whether the trigger fires before or after the event, and whether the trigger runs for each event or for each row affected by the event.
For example, you can create a trigger that runs every time
an INSERT statement affects the EMPLOYEES table.
For more information about triggers, see Chapter 9, “PL/SQL Triggers.”
Input and Output
Most PL/SQL input and output (I/O) is done with SQL statements that store data in database tables or query those tables.
For information about SQL statements, see Oracle Database SQL Language Reference.
All other PL/SQL I/O is done with PL/SQL packages that Oracle Database supplies, which Table 1–1 summarizes.


To display output passed to DBMS_OUTPUT, you need another program, such as SQL*Plus. To see DBMS_OUTPUT output with SQL*Plus, you must first issue(发出) the SQL*Plus command SET SERVEROUTPUT ON.
Some subprograms in the packages in Table 1–1 can both accept input and display output, but they cannot accept data directly from the keyboard(从键盘上直接地接收数据).
To accept data directly from the keyboard, use the SQL*Plus commands PROMPT and ACCEPT.
See Also:
■ SQL*Plus User’s Guide and Reference for information about the SQL*Plus command SET SERVEROUTPUT ON
■ SQL*Plus User’s Guide and Reference for information about the SQL*Plus command PROMPT
■ SQL*Plus User’s Guide and Reference for information about the SQL*Plus command ACCEPT
Data Abstraction
Data abstraction lets you work with the essential properties(基本属性) of data without being too involved with details(不用涉及数据细节).
You can design a data structure first(先设计数据结构), and then design algorithms that manipulate it(后设计操作数据的算法).
Topics
■ Cursors
■ Composite Variables(复合变量)
■ %ROWTYPE Attribute(属性)
■ %TYPE Attribute
■ Abstract Data Types
Cursors
A cursor is a pointer to a private SQL area that stores information about processing a specific SQL statement or PL/SQL SELECT INTO statement.
You can use the cursor to retrieve(检索) the rows of the result set one at a time.
You can use cursor attributes(游标属性) to get information about the state of the cursor—for example, how many rows the statement has affected so far.
For more information about cursors, see “Cursors” on page 6-5.
Composite Variables
A composite variable has internal components(内部组件), which you can access individually(单独的).
You can pass entire(全部的) composite variables to subprograms as parameters.
PL/SQL has two kinds of composite variables, collections(集合) and records.
In a collection, the internal components are always of the same data type, and are called elements.
You access each element by its unique index.
Lists and arrays are classic examples(典型例子) of collections.
In a record, the internal components can be of different data types, and are called fields.
You access each field by its name.
A record variable can hold a table row, or some columns from a table row.
For more information about composite variables, see Chapter 5, “PL/SQL Collections and Records.”
%ROWTYPE Attribute
The %ROWTYPE attribute lets you declare a record that represents either a full or partial row of a database table or view.
For every column of the full or partial row, the record has a field with the same name and data type.
If the structure of the row changes, then the structure of the record changes accordingly.
For more information about %ROWTYPE, see “%ROWTYPE Attribute” on page 5-44.
%TYPE Attribute
The %TYPE attribute lets you declare a data item of the same data type as a previously(之前的) declared variable or column (without knowing what that type is).
If the declaration of the referenced item(引用项) changes, then the declaration of the referencing item changes accordingly(相应地).
The %TYPE attribute is particularly(特别地) useful when declaring variables to hold database values.
For more information about %TYPE, see “%TYPE Attribute” on
page 2-15.
Abstract Data Types
An Abstract Data Type (ADT) consists of a data structure and subprograms that manipulate the data.
The variables that form the data structure are called attributes.
The subprograms that manipulate the attributes are called methods.
ADTs are stored in the database.
Instances of ADTs can be stored in tables and used as
PL/SQL variables.
ADTs let you reduce complexity by separating(分离) a large system into logical components, which you can reuse.
In the static data dictionary view *_OBJECTS, the OBJECT_TYPE of an ADT is TYPE.
In the static data dictionary view *_TYPES, the TYPECODE of an ADT is OBJECT.
For more information about ADTs, see “CREATE TYPE Statement” on page 14-78.
Note: ADTs are also called user-defined types and object types.
See Also: Oracle Database Object-Relational Developer’s Guide for information about ADTs (which it calls object types)
Control Statements
Control statements are the most important PL/SQL extension(扩展) to SQL.
PL/SQL has three categories(类别) of control statements:
■ Conditional selection statements(条件选择语句), which let you run different statements for different data values.
For more information, see “Conditional Selection Statements” on page 4-1.
■ Loop statements, which let you repeat the same statements with a series of different data values.
For more information, see “LOOP Statements” on page 4-9.
■ Sequential control statements(顺序控制语句), which allow you to go to a specified, labeled statement, or to do nothing.
For more information, see “Sequential Control Statements” on page 4-21.
Conditional Compilation(条件编译)
Conditional compilation lets you customize(定做) the functionality(功能) in a PL/SQL application without removing source text.
For example, you can:
■ Use new features with the latest database release(最新数据库版本), and disable them when running the application in an older database release.
■ Activate debugging(激活调试) or tracing statements in the development environment, and hide them when running the application at a production site(生产环境).
For more information, see “Conditional Compilation” on page 2-42.
Processing a Query Result Set One Row at a Time
PL/SQL lets you issue(发出) a SQL query and process the rows of the result set one at a time.
You can use a basic loop, as in Example 1–2, or you can control the process precisely(精确地) by
using individual statements(自己的语句) to run the query, retrieve the results, and finish processing.
Example 1–2 Processing Query Result Rows One at a Time
BEGIN
FOR someone IN (
SELECT * FROM employees
WHERE employee_id < 120
ORDER BY employee_id
)
LOOP
DBMS_OUTPUT.PUT_LINE('First name = ' || someone.first_name ||
', Last name = ' || someone.last_name);
END LOOP;
END;
/Architecture of PL/SQL(PL/SQL体系结构)
Topics
■ PL/SQL Engine(引擎)
■ PL/SQL Units and Compilation Parameters(编译参数)
PL/SQL Engine
The PL/SQL compilation and runtime system is an engine that compiles and runs PL/SQL units.
The engine can be installed in the database or in an application development tool, such as Oracle Forms.
In either environment, the PL/SQL engine accepts as input any valid PL/SQL unit.
The engine runs procedural statements, but sends SQL statements to the SQL engine in the database, as shown in Figure 1–1.
Figure 1–1 PL/SQL Engine
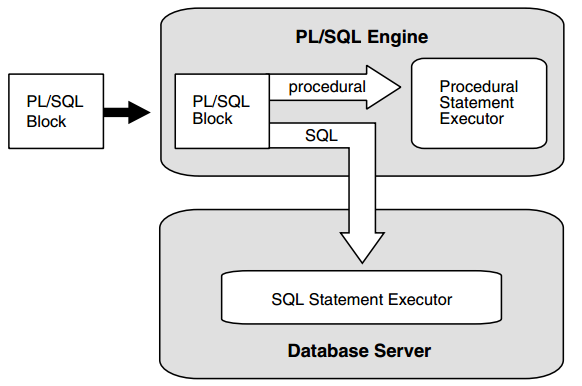
Typically, the database processes PL/SQL units.
When an application development tool processes PL/SQL units, it passes them to its local PL/SQL engine.
If a PL/SQL unit contains no SQL statements, the local engine
processes the entire PL/SQL unit.
This is useful if the application development tool can benefit(受益) from conditional and iterative control(条件和迭代控制).
For example, Oracle Forms applications frequently(频繁地) use SQL statements to test the values of field entries(字段条目) and do simple computations.
By using PL/SQL instead of SQL, these applications can avoid(避免) calls to the database.
PL/SQL Units and Compilation Parameters
A PL/SQL unit is one of these:
■ PL/SQL anonymous block(匿名块)
■ FUNCTION
■ LIBRARY
■ PACKAGE
■ PACKAGE BODY
■ PROCEDURE
■ TRIGGER
■ TYPE
■ TYPE BODY
PL/SQL units are affected by PL/SQL compilation parameters (a category(分类) of database initialization parameters).
Different PL/SQL units—for example, a package specification(说明) and its body—can have different compilation parameter settings.
Table 1–2 summarizes the PL/SQL compilation parameters.
To display the values of these parameters for specified or all PL/SQL units, query the static data dictionary view ALL_PLSQL_OBJECT_SETTINGS.
For information about this view, see Oracle Database Reference.
Table 1–2 PL/SQL Compilation Parameters



The compile-time values of the parameters in Table 1–2 are stored with the metadata of each stored PL/SQL unit, which means that you can reuse those values when you explicitly recompile the unit. (A stored PL/SQL unit is created with one of the “CREATE [ OR REPLACE ] Statements” on page 14-1. An anonymous block is not a stored PL/SQL unit.)
To explicitly recompile a stored PL/SQL unit and reuse its parameter values, you must use an ALTER statement with both the COMPILE clause and the REUSE SETTINGS clause.
For more information about REUSE SETTINGS, see “compiler_parameters_clause” on
page 14-4. (All ALTER statements have this clause. For a list of ALTER statements, see “ALTER Statements” on page 14-1.)
最后
以上就是自由草莓最近收集整理的关于Overview of PL/SQL的全部内容,更多相关Overview内容请搜索靠谱客的其他文章。








发表评论 取消回复