一 Hbase 读写 WAL--Write Ahead Log
Region是HBase数据存储和管理的基本单位。在HBase的一个表中,可以包含一个或多个region。对于一个region,每个列族都会对应一个store,用来存储该列族的数据。每个store都有一个写缓存memstore,用于缓存写入的数据。
【写过程】
1、客户端向RegionServer发送写入数据请求。Client先从缓存中定位region,如果没有缓存则需访问zookeeper,从.META.表获取要写入的region信息
2、定位写入region。找到小于rowkey并且最接近rowkey的startkey对应的region
3、WAL。RegionServer先将数据写入HLog,即WAL,再将数据写入MemStore。将更新写入WAL中。当客户端发起put/delete请求时,考虑到写入内存会有丢失数据的风险,因此在写入缓存前,HBase会先写入到Write Ahead Log(WAL)中(WAL存储在HDFS中),那么即使发生宕机,也可以通过WAL还原初始数据。
4、memstore fulsh到 HDFS storefile。将更新写入memstore中,当增加到一定大小,达到预设的Flush size阈值时,会触发flush memstore,把memstore中的数据写出到hdfs上,生成一个storefile。
5、compact触发storefile合并操作。随着Storefile文件的不断增多,当增长到一定阈值后,触发compact合并操作,将多个storefile合并成一个,同时进行版本合并和数据删除。storefile通过不断compact合并操作,逐步形成越来越大的storefile。
6、storefile触发split,切分region。单个stroefile大小超过一定阈值后,触发split操作,把当前region拆分成两个,新拆分的2个region会被hbase master分配到相应的2个regionserver上。
【读过程】
1.客户端访问zookeeper获取meta表(主要记录表的元信息),然后从meta中获取想要操作的region位置。并将meta缓存在客户端(将保存着regionserver位置信息的元数据表.META.进行缓存),用于后续的操作(当一个RegionServer宕机后,客户端需要重新获取meta信息进行缓存);
2.应的RegionServer建立连接并发起读取数据请求;
3.RegionServer会先到MemStore中查数据,如果查不到就会到BlockCache中查,再查不到就会访问磁盘中HFile读取数据。
二 LSM树 日志结构合并树 (Log-Structured Merge-Tree)
Hbase 读取速度快原因分析
B+树的应用场景:主要用在传统的行数据库中,因为查询速度快。但是如有有大量的数据需要查询时就暴露出其弊端。
LSM的优点:能快速进行数据的合并和拆分。
LSM树的应用场景:Hbase就是使用了LSM树。
主要的实现方式:写数据时,
1.写到预写日志中,目的是防止数据在写入时丢失;
2.将数据放入到内存中。
3.当内存的大小超过指定值,会把内存中的数据写入到磁盘上。
关键点:磁盘的数据是有序的,这是利用预写日志和内存把随机写数据进行排序后写入,因此也能保证稳定的数据插入速率。
知道hbase的存储形式,接下来讲下hbase为什么能快速的读写删除。
读功能:
读取内容的顺序是先到内存中去寻找,再到磁盘中查找。我们都清楚的一点是:磁盘的查询速度是非常慢的。
问题来了,为什么kafka和hbase的速度非常快的?
这个需要认识到磁盘的一些小知识。我们在查找数据时,首先是去磁盘寻道。这个才是最耗时的。
所以,使用Hbase的范围查询,假如有五个存储文件,最多也就进行五次的磁盘寻道。所以读功能的性能瓶颈也就得到了提升。
删除功能:
删除数据不是进行实质上的删除,也就是磁盘上仍然存在此条数据。只不过是对删除的数据打上了墓碑标记。利用墓碑标记,读数据会忽略此条数据。
当进行小文件合并时,才会进行实质上删除。
推荐一篇文章读读
https://blog.csdn.net/keda8997110/article/details/50916800
关于B+树 LSM树 估计要读几篇博客消化了
https://blog.csdn.net/u010853261/article/details/78217823
https://www.cnblogs.com/aspirant/p/9214485.html
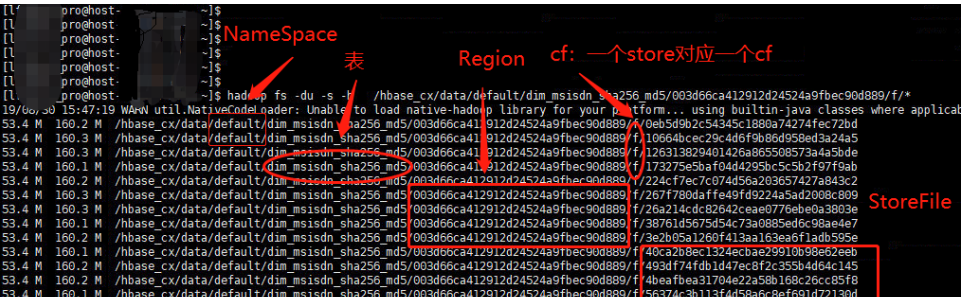
三 存储目录分析
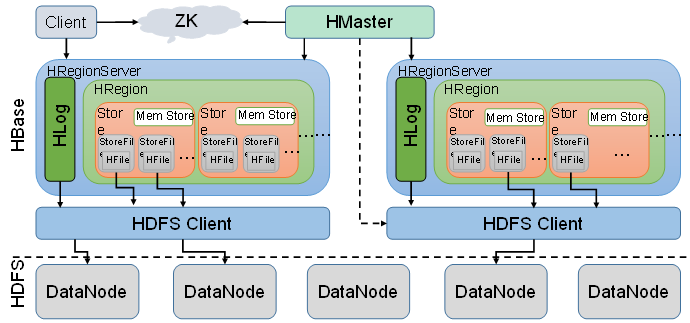
Client
Client包含了访问Hbase的接口,另外Client还维护了对应的cache来加速Hbase的访问,比如cache的.META.元数据的信息。
Zookeeper
HBase通过Zookeeper来做master的高可用、RegionServer的监控、元数据的入口以及集群配置的维护等工作。具体工作如下:
通过Zoopkeeper来保证集群中只有1个master在运行,如果master异常,会通过竞争机制产生新的master提供服务
通过Zoopkeeper来监控RegionServer的状态,当RegionSevrer有异常的时候,通过回调的形式通知Master RegionServer上下线的信息
通过Zoopkeeper存储元数据的统一入口地址
master节点:
为RegionServer分配Region
维护整个集群的负载均衡
维护集群的元数据信息
发现失效的Region,并将失效的Region分配到正常的RegionServer上
当RegionSever失效的时候,协调对应Hlog的拆分
HregionServer
HregionServer直接对接用户的读写请求,是真正的“干活”的节点。它的功能概括如下:
管理master为其分配的Region
处理来自客户端的读写请求
负责和底层HDFS的交互,存储数据到HDFS
负责Region变大以后的拆分
负责Storefile的合并工作
HFile存储在Store中,一个Store对应HBase表中的一个列族(列簇, Column Family)。
聊一下compact
minorcompact
选一些小的相邻的storeFile合并成一个更大的storeFile,是合并多个更大的storeFile,更大,数量更少。
majorcompact
将所有storeFile合并成一个storeFile。时间长,先生业务改为手动。清理3类数据
1.被删除的数据,keytype类型为delete类型
2.TTL过期的数据,f列族设置TTL
3.版本号超过设定版本号的数据
最后
以上就是缥缈心情最近收集整理的关于Hbase 读写流程一 Hbase 读写 WAL--Write Ahead Log二 LSM树 日志结构合并树 (Log-Structured Merge-Tree)Hbase 读取速度快原因分析三 存储目录分析的全部内容,更多相关Hbase内容请搜索靠谱客的其他文章。








发表评论 取消回复