文章目录
- 前言
- 一、Spark Streaming概述
- 1、什么是Spark Streaming
- 2、为什么要学习Spark Streaming
- 1.易用
- 2.容错
- 3.易整合到Spark体系
- 3、Spark与Storm的对比
- 二、运行Spark Streaming
- 三、架构与抽象
- 四、Spark Streaming解析
- 1、初始化StreamingContext
- 2、什么是DStreams
- 3、DStreams输入
- (1)Spark对Kafka两种连接方式的对比
- (2)Receiver方式接收器模式
- (3)Direct方式直连模式
- 未完の
前言
你们好我是啊晨
今儿更新spark 技术Spark Streaming。
废话不多说,内容很多选择阅读,详细。
请:
一、Spark Streaming概述
1、什么是Spark Streaming
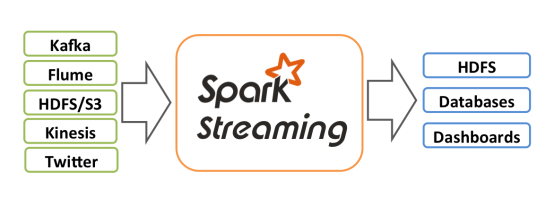
Spark Streaming类似于Apache Storm,用于流式数据的处理。根据其官方文档介绍,Spark Streaming有高吞吐量和容错能力强等特点。Spark Streaming支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ和简单的TCP套接字等等。数据输入后可以用Spark的高度抽象原语如:map、reduce、join、window等进行运算。而结果也能保存在很多地方,如HDFS,数据库等。另外Spark Streaming也能和MLlib(机器学习)以及Graphx完美融合。
和Spark基于RDD的概念很相似,Spark Streaming使用离散化流(discretized stream)作为抽象表示,叫作DStream。DStream 是随时间推移而收到的数据的序列。在内部,每个时间区间收到的数据都作为RDD 存在,而 DStream 是由这些 RDD 所组成的序列(因此 得名“离散化”)。
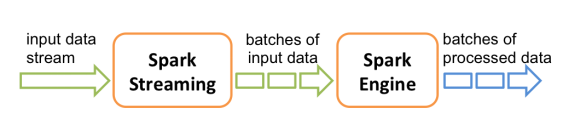
DStream 可以从各种输入源创建(简单数据源socket 复杂数据源kafka),比如 Flume、Kafka 或者 HDFS。创建出来的DStream 支持两种操作,一种是转化操作(transformation),会生成一个新的DStream,另一种是输出操作(output operation),可以把数据写入外部系统中,每个时间区间分别输出到不同的文件。DStream 提供了许多与 RDD 所支持的操作相类似的操作支持,还增加了与时间相关的新操作,比如滑动窗口。
2、为什么要学习Spark Streaming
1.易用
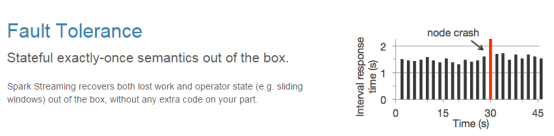
2.容错
3.易整合到Spark体系

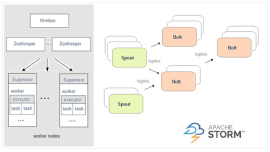
3、Spark与Storm的对比
| Spark | Storm |
|---|---|
 |  |
| 开发语言:Scala | 开发语言:Clojure |
| 编程模型:DStream | 编程模型:Spout/Bolt |
 |  |
目前流行的三种实时框架对比
| Apache | Flink | SparkSteaming | Storm |
|---|---|---|---|
| 架构 | 架构介于spark和storm之间,主从结构与sparkStreaming相似,DataFlow Grpah与storm相似,数据流可以被表示为一个有向图,每个顶点是一个定义的运算,每向边表示数据的流动 Native | 架构依赖Spark,主从模式,每个batch批次处理都依赖driver主,可以理解为时间维度上的spark DAG Micro-Batch | 主从模式,且依赖ZK,处理过程中对主的依赖不大 Native |
| 容错 | 基于Ghandy-Lamport distributed snapshots checkpoint机制 Medium | WAL及RDD血统机制 High(高) | Records Ack Medium(一般) |
| 处理模型与延时 | 单条时间处理亚秒级低延时 | 一个事件窗口内的所有事件 秒级低延时 | 每次传入的一个事件 亚秒级低延时 |
| 吞吐量 | High | High | Low(低) |
| 数据处理保证 | Exactly once High | Exactly once(实现架用Chandy-Lamport算法,即marker-checkpoint) High | At least once(实现架用record-level acknowledgments),Trident可以支持storm提供exactly once语义 Medium |
| 高级API | Flink,栈中提供了很多高级API和满足不同场景的类库:机器学习、图分析、关系式数据处理 High | 能够很容易的对接Spark生态圈里面的组件,同时额能够对接主流的消息传输组件及存储系统 High | 应用需要按照特定的storm定义的规模编写 Low |
| 易用性 | 支持SQL Streaming,Batch和Streaming采用统一编程框架 High | 支持SQL Streaming,Batch和Streaming采用统一编程框架 High | 不支持SQL Streaming Medium |
| 成熟性 | 新兴项目,处于发展阶段 Low 大家都在观望,用户量比较低 | 已经发展一段时间 Medium 用户量在逐渐增加 | 相对较早的流系统,比较稳定 High |
| 社区活动度 | 212 contributor 上升阶段 Medium | 937 contributor High | 216 contributor,活跃比较稳定 Medium |
| 部署性 | 部署相对简单,只依赖JRE环境 Low | 部署相对简单,只依赖JRE环境 Low | 依赖JRE环境和ZK High |
二、运行Spark Streaming
IDEA编写程序
Pom.xml 加入以下依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.1.1</version>
</dependency>
package com.bigdata.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object WorldCount {
def main(args: Array[String]) {
//注意运输模式为local的时候必须至少设置2个core, local[2]
//接收socket的数据,需要一个对应的接收器,这个接收器就会使用cpu核
//处理数据就需要一个执行器,这个执行器也会使用cpu核
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
//需要两个参数 第一个是 SparkConf 第二个是时间间隔,每个批次的数据的时间范围的长度
val ssc = new StreamingContext(conf, Seconds(1))
/接收一个socket端口的数据
//两个参数 第一参数:hostname或者是IP地址 第二个参数:端口号
// Create a DStream that will connect to hostname:port, like localhost:9999
val lines = ssc.socketTextStream("master01", 9999)
// Split each line into words
val words = lines.flatMap(_.split(" "))
//import org.apache.spark.streaming.StreamingContext._ // not necessary since Spark 1.3
// Count each word in each batch
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
// Print the first ten elements of each RDD generated in this DStream to the console
wordCounts.print()
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate
}
}
按照Spark Core中的方式进行打包,并将程序上传到Spark机器上。并运行:
bin/spark-submit --class com.bigdata.streaming.WorldCount ~/wordcount-jar-with-dependencies.jar
通过Netcat发送数据:(netcat是一个用于TCP/UDP连接和监听的linux工具, 主要用于网络传输及调试领域。百度自行下载)
# TERMINAL 1:
# Running Netcat
通过yum install -y nc 安装使用 nc -lk开启一个socket端口
通过解压netcat-0.7.1.tar.gz安装包的 nc -lp 9999
# nc -lk 9999
# 手动安装时 nc -lp 9999
hello world
如果程序运行时,log日志太多,可以将spark conf目录下的log4j文件里面的日志级别改成WARN。
三、架构与抽象
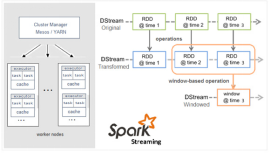
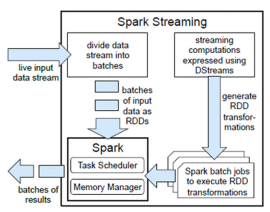
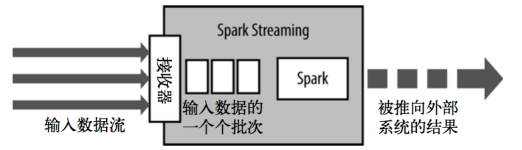
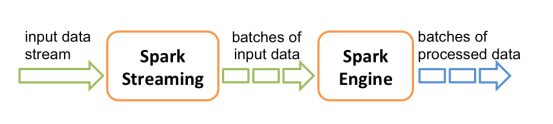
Spark Streaming使用“微批次”的架构,把流式计算当作一系列连续的小规模批处理来对待。Spark Streaming从各种输入源中读取数据,并把数据分组为小的批次。新的批次按均匀的时间间隔创建出来。在每个时间区间开始的时候,一个新的批次就创建出来,在该区间内收到的数据都会被添加到这个批次中。在时间区间结束时,批次停止增长。时间区间的大小是由批次间隔这个参数决定的。批次间隔一般设在500毫秒到几秒之间(根据自己的业务去设置),由应用开发者配置。每个输入批次都形成一个RDD,以 Spark 作业的方式处理并生成其他的 RDD。 处理的结果可以以批处理的方式传给外部系统。高层次的架构如图
Spark Streaming的编程抽象是离散化流,也就是DStream。它是一个 RDD 序列,每个RDD代表数据流中一个时间片内的数据。

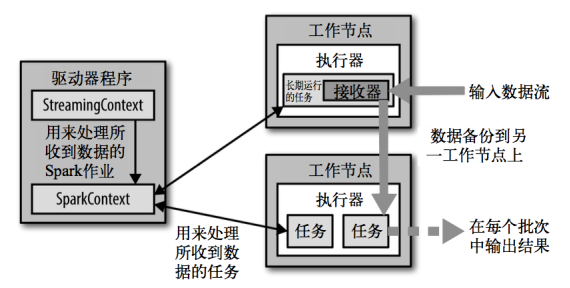
Spark Streaming在Spark的驱动器程序—工作节点的结构的执行过程如下图所示。
Spark Streaming为每个输入源启动对应的接收器。接收器以任务的形式运行在应用的执行器进程中,从输入源收集数据并保存为RDD。它们收集到输入数据后会把数据复制到另一个执行器进程来保障容错性(默认行为)。数据保存在执行器进程的内存中,和缓存 RDD的方式一样。驱动器程序中的 StreamingContext 会周期性地运行 Spark 作业来处理这些数据,把数据与之前时间区间中的 RDD 进行整合。
数据接收器是一个进程,数据执行器是一个进程。
一个接收器对应一个数据源,一个接收器就是一个进程,占用一个cpu。
由于处理是流式数,需要启动一个进程去监控我们的数据源接收数据,这个进程会一直存在,需要再开启一个数据执行器的进程,来处理数据,监控一个端口至少需要两个进程,监控5个端口需要6个进程,其中5个进程监控5个端口,一个进程去处理数据。
四、Spark Streaming解析
1、初始化StreamingContext
import org.apache.spark._
import org.apache.spark.streaming._
val conf = new SparkConf().setAppName(appName).setMaster(master)
val ssc = new StreamingContext(conf, Seconds(1))
// 可以通过ssc.sparkContext 来访问SparkContext
// 或者通过已经存在的SparkContext来创建StreamingContext
import org.apache.spark.streaming._
val sc = ... // existing SparkContext
val ssc = new StreamingContext(sc, Seconds(1))
初始化完Context之后:
1)定义消息输入源来创建DStreams.
2)定义DStreams的转化操作和输出操作。
3)通过 streamingContext.start()来启动消息采集和处理.
4)等待程序终止,可以通过streamingContext.awaitTermination()来设置
5)通过streamingContext.stop()来手动终止处理程序。
StreamingContext和SparkContext什么关系?
import org.apache.spark.streaming._
val sc = ... // existing SparkContext
val ssc = new StreamingContext(sc, Seconds(1))
注意:
StreamingContext一旦启动,对DStreams的操作就不能修改了。
在同一时间一个JVM中只有一个StreamingContext可以启动
stop() 方法将同时停止SparkContext,可以传入参数stopSparkContext用于只停止StreamingContext
在Spark1.4版本后,如何优雅的停止SparkStreaming而不丢失数据,通过设置sparkConf.set(“spark.streaming.stopGracefullyOnShutdown”,“true”) 即可。在StreamingContext的start方法中已经注册了Hook方法。
2、什么是DStreams
Discretized Stream是Spark Streaming的基础抽象,代表持续性的数据流和经过各种Spark原语操作后的结果数据流。在内部实现上,DStream是一系列连续的RDD来表示。每个RDD含有一段时间间隔内的数据,
Spark Streaming把一系列连续的批次称为Dstream。
Dstream的特点:
就是将流式计算分解成为一系列确定并且较小的批处理作业
可以将失败或者执行较慢的任务在其他节点上并行执行
有较强的的容错能力,基于lineage
Dstream内含high-level operations进行处理
Dstream内部实现为一个RDD序列
如下图:
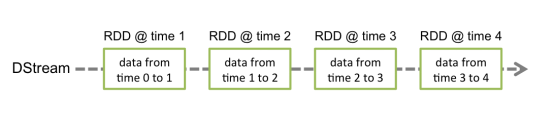
对数据的操作也是按照RDD为单位来进行的
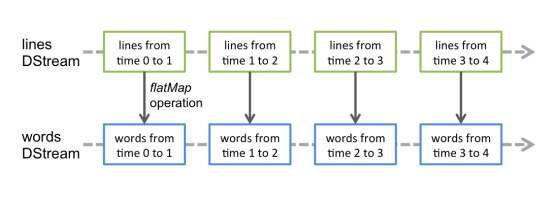
计算过程由Spark engine来完成
3、DStreams输入
Spark Streaming原生支持一些不同的数据源。一些“核心”数据源已经被打包到Spark Streaming 的 Maven 工件中,而其他的一些则可以通过 spark-streaming-kafka 等附加工件获取。
Steaming的数据源和接收器
数据源:基本数据源/高级数据源
基本数据源:socket、file,akka actoer。Steaming中自带了该数据源的读取API
高级数据源:kafka,flume,kinesis,Twitter等其他的数据。必须单独导入集成的JAR包
接收器:
Socket数据源,有一个接收器,用以接收Socket的数据。每一个接收器必须占用一个cores来接收数据。如果资源不足(有cpu接收数据,没有cpu处理数据。有多个数据,只有一个cpu用来接收数据),那么任务就会处于等待状态。
每个接收器都以 Spark 执行器程序中一个长期运行的任务的形式运行,因此会占据分配给应用的 CPU 核心。此外,我们还需要有可用的 CPU 核心来处理数据。这意味着如果要运行多个接收器,就必须至少有和接收器数目相同的核心数,还要加上用来完成计算所需要的核心数。例如,如果我们想要在流计算应用中运行 10 个接收器,那么至少需要为应用分配 11 个 CPU 核心(N+1,N代表接收器的个数,1代表处理数据的核数)。所以如果在本地模式运行,不要使用local或者local[1]。
除核心数据源外,还可以用附加数据源接收器来从一些系统中接收的数据,这些接收器都作为Spark Streaming的组件进行独立打包了。它们仍然是Spark的一部分,不过你需要在构建文件中添加额外的包才能使用它们。现有的接收器包括 Twitter、Apache Kafka、Amazon Kinesis、Apache Flume,以及ZeroMQ。可以通过添加与Spark版本匹配 的 Maven 工件 spark-streaming-[projectname]_2.10 来引入这些附加接收器。
(1)Spark对Kafka两种连接方式的对比
Kafka项目在版本0.8和0.10之间引入了一个新的消费者api,因此有两个独立的相应Spark Streaming包可用。请选择正确的包装; 请注意,0.8集成与后来的0.9和0.10代理兼容,但0.10集成与早期的代理不兼容。
| spark-streaming-kafka-0-8 | spark-streaming-kafka-0-10 | |
|---|---|---|
| Broker Version | 0.8.2.1或更高 | 0.10.0或更高 |
| Api Stability | 稳定 | 试验 |
| Language Support | Scala,Java,Python | Scala,Java |
| Receiver DStream | 是 | 没有 |
| Direct DStream | 是 | 是 |
| SSL / TLS Support | 没有 | 是 |
| Offset Commit Api | 没有 | 是 |
| Dynamic Topic Subscription | 没有 | 是 |
Spark对于Kafka的连接主要有两种方式,一种是Direct方式直连模式,另外一种是Receiver方式接收器模式。Direct方式只在 driver 端接收数据,所以继承了InputDStream,是没有 receivers 的。
主要通过KafkaUtils#createDirectStream以及KafkaUtils#createStream这两个 API 来创建,除了要传入的参数不同外,接收 kafka 数据的节点、拉取数据的时机也完全不同。
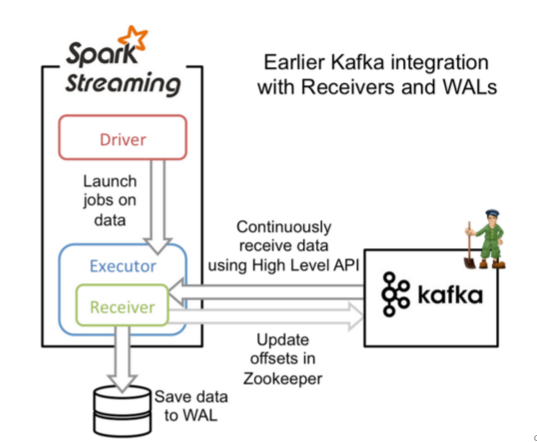
(2)Receiver方式接收器模式
Receiver:接收器模式是使用Kafka高级Consumer API实现的。与所有接收器一样,从Kafka通过Receiver接收的数据存储在Spark Executor的内存中(会出现两种问题),然后由Spark Streaming启动的job来处理数据。然而默认配置下,这种方式可能会因为底层的失败而丢失数据(请参阅接收器可靠性)。如果要启用高可靠机制,确保零数据丢失,要启用Spark Streaming的预写日志机制(Write Ahead Log,(已引入)在Spark 1.2)。该机制会同步地将接收到的Kafka数据保存到分布式文件系统(比如HDFS)上的预写日志中,以便底层节点在发生故障时也可以使用预写日志中的数据进行恢复(kafka就是副本机制,实现高可用,Receiver:接收器模式不是高可用,为了实现数据0丢失,需要将数据写入到磁盘,导致数据冗余)。
单点读数据,读到的数据会缓存到executor的cache里,增大了内存使用的压力,如果接收器接收数据的速度很快,但是executor消费数据的速度很慢吗,会导致数据积压。
在Receiver的方式中,使用的是Kafka的高阶API接口从Zookeeper中获取offset值,这也是传统的从Kafka中读取数据的方式,但由于Spark Streaming消费的数据和Zookeeper中记录的offset不同步,这种方式偶尔会造成数据重复消费(Receiver读取数据之后,但是Receiver挂掉了,没有将读取的数据写入Zookeeper中获取offset值,下次重启Receiver,再次从Zookeeper中获取offset值的位置读取数据,会出现重复消费)。
特点
在spark的executor中,启动一个接收器,专门用于读取kafka的数据,然后存入到内存中,供sparkStreaming消费
1、为了保证数据0丢失,WAL(预写日志机制Write Ahead Log),数据会保存2份,有冗余
2、Receiver是单点读数据,如果挂掉,程序不能运行
3、数据读到executor内存中,增大了内存使用的压力,如果消费不及时,会造成数据积压
如下图:
对于使用Maven项目定义的Scala / Java应用程序时,我们需要添加相应的依赖包:
<dependency><!-- Spark Streaming Kafka -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_2.11</artifactId>
<version>1.6.3</version>
</dependency>
在流应用程序代码中,导入KafkaUtils并创建输入DStream,如下所示。
import org.apache.spark.streaming.kafka._
val kafkaStream = KafkaUtils.createStream(streamingContext,
[ZK quorum], [consumer group id], [per-topic number of Kafka partitions to consume])
还有几个需要注意的点:
1、Kafka中topic的partition与Spark Streaming中生成的RDD的partition无关,因此,在KafkaUtils.createStream()中,增加某个topic的partition的数量,只会增加单个Receiver消费topic的线程数,也就是读取Kafka中topic partition的线程数量,它不会增加Spark在处理数据时的并行性。
2、可以使用不同的consumer group和topic创建多个Kafka输入DStream,以使用多个receiver并行接收数据。
3、如果已使用HDFS等复制文件系统启用了“预读日志”,则接收的数据已在日志中复制。因此,输入流的存储级别的存储级别StorageLevel.MEMORY_AND_DISK_SER(即,使用KafkaUtils.createStream(…, StorageLevel.MEMORY_AND_DISK_SER))。
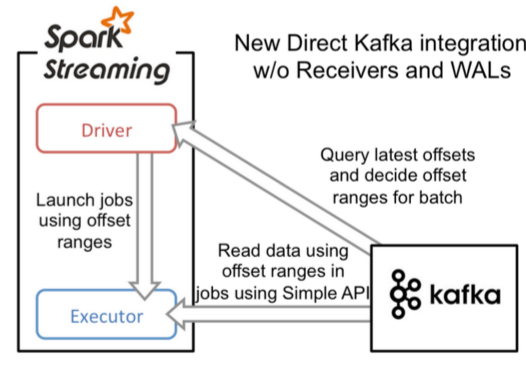
(3)Direct方式直连模式
Direct:直连模式,在spark1.3之后,引入了Direct方式。不同于Receiver的方式,Direct方式没有receiver这一层,其会周期性的获取Kafka中每个topic的每个partition中的最新offsets,并且相应的定义要在每个batch中处理偏移范围,当启动处理数据的作业时,kafka的简单的消费者api用于从kafka读取定义的偏移范围 。其形式如下图:
这种方法相较于Receiver方式的优势在于:
1、简化的并行:在Receiver的方式中我们提到创建多个Receiver之后利用union来合并成一个Dstream的方式提高数据传输并行度。而在Direct方式中,Kafka中的partition与RDD中的partition是一一对应的并行读取Kafka数据,这种映射关系也更利于理解和优化(增加某个topic的partition的数量,同时RDD中的partition也会增加,增加Spark在处理数据时的并行性)。
2、高效:在Receiver的方式中,为了达到0数据丢失需要将数据存入Write Ahead Log中,这样在Kafka和日志中就保存了两份数据,浪费!而第二种方式(Direct)不存在这个问题,只要我们Kafka的数据保留时间足够长,我们都能够从Kafka进行数据恢复(从Kafka中读取数据后直接消费)。
3、精确一次:在Receiver的方式中,使用的是Kafka的高阶API接口从Zookeeper中获取offset值,这也是传统的从Kafka中读取数据的方式,但由于Spark Streaming消费的数据和Zookeeper中记录的offset不同步,这种方式偶尔会造成数据重复消费。而第二种方式(Direct),直接使用了简单的低阶Kafka API,Offsets则利用Spark Streaming的checkpoints进行记录(Offsets和Zookeeper没有关系,有自己维护),消除了这种不一致性。
每个Executor既负责读数据,也负责处理数据,不存在单点问题,读取数据直接处理,不cache。
请注意,此方法的一个缺点是它不会更新Zookeeper中的偏移量,因此基于Zookeeper的Kafka监视工具将不会显示进度。但是,您可以在每个批处理中访问此方法处理的偏移量,并自行更新Zookeeper。
直连模式特点:batch time 每隔一段时间,去kafka读取一批数据,然后消费
简化并行度,rdd的分区数量=topic的分区数量
数据存储于kafka中,没有数据冗余
不存在单点问题
每个Executor既负责读数据,也负责处理数据,不存在单点问题,读取数据直接处理,不cache。
效率高
可以实现仅消费一次的语义exactly-once语义,不会重复消费
对于使用Maven项目定义的Scala / Java应用程序时,我们需要添加相应的依赖包:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.1.1</version>
</dependency>
请注意,导入的命名空间包括版本
org.apache.spark.streaming.kafka010
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
/*
auto.offset.reset
earliest 先去zookeeper获取offset,如果有直接使用,如果没有自从最开始的地方开始消费
latest 先去zookeeper获取offset,如果有直接使用,如果没有自从最新的偏移量开始
none 先去zookeeper获取offset,如果有直接使用,如果没有直接报错
*/
object KafkaDirectorDemo {
def main(args: Array[String]): Unit = {
//构建conf ssc 对象
val conf = new SparkConf().setAppName("Kafka_director").setMaster("local[*]")
val ssc = new StreamingContext(conf,Seconds(5))
//设置数据检查点进行累计计算
// ssc.checkpoint("hdfs://192.168.25.101:9000/checkpoint")
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "CentOS1:9092,CentOS2:9092,CentOS3:9092",//用于初始化链接到集群的地址
"key.deserializer" -> classOf[StringDeserializer],//key序列化
"value.deserializer" -> classOf[StringDeserializer],//value序列化
"group.id" -> "group1",//用于标识这个消费者属于哪个消费团体
"auto.offset.reset" -> "latest",//偏移量 latest自动重置偏移量为最新的偏移量
"enable.auto.commit" -> (false: java.lang.Boolean)//如果是true,则这个消费者的偏移量会在后台自动提交
)
//kafka 设置kafka读取topic
val topics = Array("first", "second")
//需要导入包
/*
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.3.1</version>
</dependency>
*/
//LocationStrategies.PreferConsistent任务尽量均匀分布在各个executor节点
// 创建DStream,返回接收到的输入数据
// LocationStrategies:根据给定的主题和集群地址创建consumer
// LocationStrategies.PreferConsistent:持续的在所有Executor之间分配分区
// ConsumerStrategies:选择如何在Driver和Executor上创建和配置Kafka Consumer
// ConsumerStrategies.Subscribe:订阅一系列主题
//createDirectStream[String,String] 指定消费kafka的message的key/value的类型
//ConsumerStrategies.Subscribe[String,String]指定key/value的类型
val dStreaming = KafkaUtils.createDirectStream(ssc,LocationStrategies.PreferConsistent,Subscribe[String, String](topics, kafkaParams))
val rdd = dStreaming.map(record => (record.key, record.value))
rdd.print()
rdd.count().print()
println("~~~~")
rdd.countByValue().print()
dStreaming.foreachRDD(rdd=>rdd.foreach(println(_)))
ssc.start()
ssc.awaitTermination()
}
}
未完の
这些先敲敲敲着去理解下,下篇继续更新,谢谢观看
最后
以上就是执着哈密瓜最近收集整理的关于Spark Streaming详细文本教学01前言一、Spark Streaming概述二、运行Spark Streaming三、架构与抽象四、Spark Streaming解析未完の的全部内容,更多相关Spark内容请搜索靠谱客的其他文章。








发表评论 取消回复