第一篇:爬虫设计思路及原理
刚听说爬虫时,估计很多人觉得很神奇,是什么赋予了它生命力做到在网络上到处爬取的呢?等我说完你会恍然大悟,其实并没有多高深的技术,人人都可以写,爬虫也不是那么神奇的生命,也是基本的逻辑代码实现。
首先理一下思路,爬虫时怎么做到在网络上爬行的呢?
当我们访问一个网页时,可以看到里面有很多子链接,如果说我们把这些子链接捕获到并保存下来,那么就可以作为爬虫下一次要访问的目标,一层层下来,链接是无穷的,可以访问的互联网的每一个角落(有点夸张啊)。每访问一个链接我们都可以获取我们需要的内容,并获取下一次需要访问的链接,那么我们的爬虫功能就实现了。我们需要做的只是保存维护好这些链接资源以及利用好我们抓取的内容。
先看下效果,随便附上git资源,源码https://github.com/liwei128/lw_reptile.git 可直接运行文件https://github.com/liwei128/lw_reptile.git 具体怎么编译怎么运行,github中有详细说明

下面是我设计的window版本的爬虫流程图
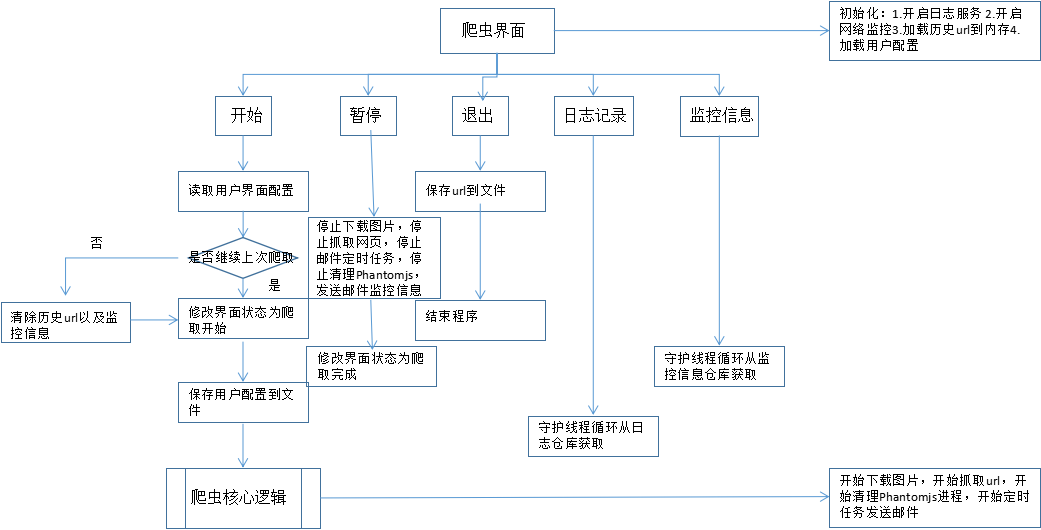
爬虫核心逻辑如下:
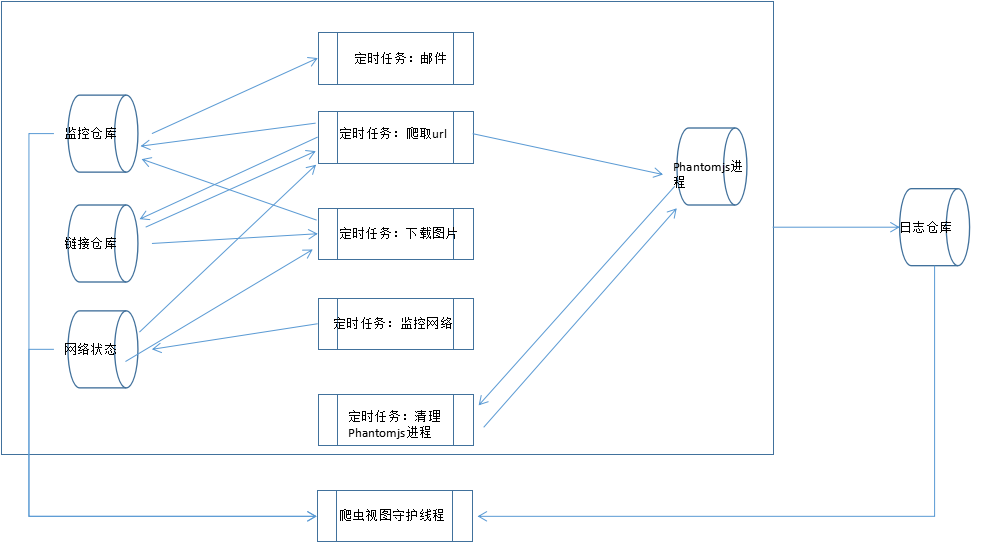
包含定时抓取维护url和定时下载图片以及附加功能(监控网络、日志打印、监控爬虫进度、邮件提醒等),两者功能进行了分离,数据共享。
定时任务抓取网页流程如下
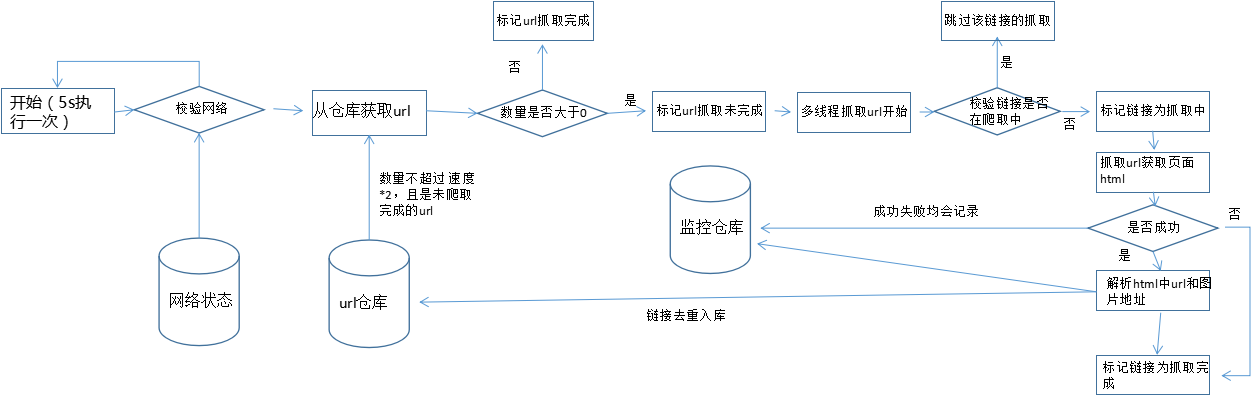
定时任务下载图片与此类似,每次获取图片地址数量为 速度*20
当标记url为爬取完成且标记图片为爬取完成时,爬虫视图守护线程会停止爬虫任务,与图1暂停按钮类似。
最后
以上就是魁梧帅哥最近收集整理的关于手把手教你实现window图片爬虫(一)的全部内容,更多相关手把手教你实现window图片爬虫(一)内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复