微信公众平台的开发者文档
https://www.w3cschool.cn/weixinkaifawendang/
python,flask,SAE(新浪云),搭建开发微信公众账号
http://www.oschina.net/code/snippet_1768500_36580
从零开始 Python 微信公众号开发
https://zhuanlan.zhihu.com/p/21354943
新浪云应用
http://www.sinacloud.com/doc/sae/python/
SAE Python如何搭建本地开发环境
https://www.liaoxuefeng.com/article/00137389260145256f699d538ae4fd3910be06d2753b192000
从零开始这篇文章讲得很清楚,新建好一个python应用后,就可以在上面搭建跟微信公众号的接口了。
使用文章的wxpytest代码,会出现not found错误,不知道什么原因,后来重新找了个文章的例子就可以了。
用get方法验证,用post方法接受发送XML格式的信息
config.yaml
name: wxpy
version: 1
libraries:
- name: webpy
version: "0.36"
- name: lxml
version: "2.3.4"
index.wsgi
import sae
sae.add_vendor_dir('vendor')
from meishidaren import app
application = sae.create_wsgi_app(app)
meishidaren.py
#encoding=utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf8')
import time
from flask import Flask, request,make_response
import hashlib
import xml.etree.ElementTree as ET
'''
import sys
sys.path.append("utils")
'''
from utils import timehelper
from utils import travelhelper
app = Flask(__name__)
app.debug=True
@app.route('/',methods=['GET','POST'])
def wechat_auth():
if request.method == 'GET':
token='weixintest'
data = request.args
print "Get data:",data
signature = data.get('signature','')
timestamp = data.get('timestamp','')
nonce = data.get('nonce','')
echostr = data.get('echostr','')
s = [timestamp,nonce,token]
s.sort()
s = ''.join(s)
if (hashlib.sha1(s).hexdigest() == signature):
return make_response(echostr)
else:
return make_response(echostr)
else:
rec = request.stream.read()
print "Post data:",rec
xml_rec = ET.fromstring(rec)
msgType=xml_rec.find("MsgType").text
tou = xml_rec.find('ToUserName').text
fromu = xml_rec.find('FromUserName').text
content = xml_rec.find('Content').text.strip()
content = get_response(msgType,xml_rec,content)
xml_rep = "<xml><ToUserName><![CDATA[%s]]></ToUserName><FromUserName><![CDATA[%s]]></FromUserName><CreateTime>%s</CreateTime><MsgType><![CDATA[text]]></MsgType><Content><![CDATA[%s]]></Content><FuncFlag>0</FuncFlag></xml>"
response = make_response(xml_rep % (fromu,tou,str(int(time.time())),content))
response.content_type='application/xml'
return response
def get_response(msgType,xml_rec,content):
#try:
if msgType == 'image':
picurl = xml_rec.find('PicUrl').text
content = "图片地址是:"+picurl
else:
print content
if content == "1": #旅游
t = travelhelper.TravelHelper()
content = t.GetZhuhaiHuWai()
elif content == '2':
content = '未开发'
else:
content = "收到的内容是:"+ content+"<br/>参考1.旅游"
'''except Exception,e:
content = 'Error:'+e.message
finally:'''
return content
配置微信公众号的时候又出现验证失败,从日志中找到url用浏览器打开,发现提示实名认证未通过,看来这就是原因了。果然,在拍身份证上传后,配置微信公众号就成功了。
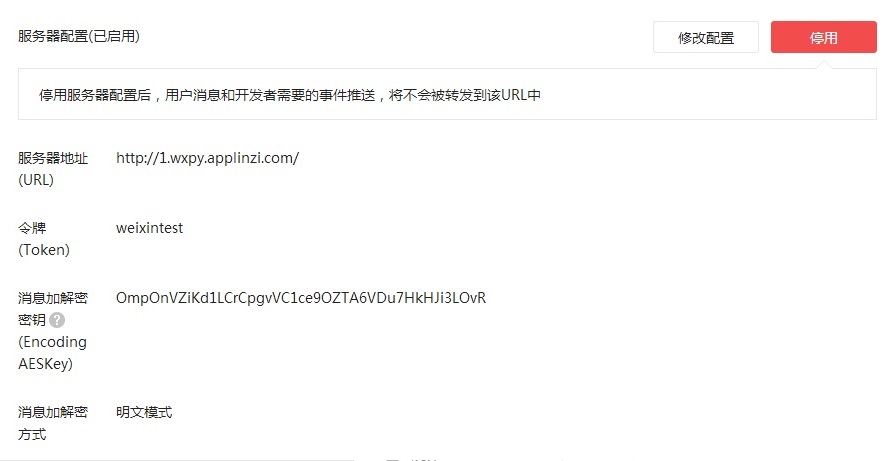
接着搭建本地SAE环境,注意必须运行在该目录的git bash下,我之前不知道,在命令行运行dev_server.py总是打开文本,纳闷了好久
$ git clone https://github.com/sinacloud/sae-python-dev-guide.git
$ cd sae-python-dev-guide/dev_server
$ python setup.py install
$ dev_server.py
MySQL config not found: app.py
Start development server on http://localhost:8080
改端口:$ dev_server.py -p 8090
看到廖雪峰文章说本地和SAE上环境代码有些不一样,但我这里用的代码都是可以不用修改
本地代码deploy到新浪上也是通过git bash命令行,刚开始先clone,后来每次都是无脑输入下面三个命令
● 在你应用代码目录里,克隆git远程仓库
● $ git clone https://git.sinacloud.com/wxpy
● 输入您的安全邮箱和密码。
● $ cd wxpy
● 编辑代码并将代码部署到 `origin` 的版本1。
● $ git add .
或者git add . --ignoreremoval
● $ git commit -m 'Init my first app'
● $ git push origin 1
push的时候次次都要输入用户名密码,好烦,我还不知怎么搞,下面这些命令无效啊
$git config --global credential.helper wincred
$git config --global user.email "you@example.com"
$git config --global user.name "Your Name"
有时候报错,是因为我在代码代理上自己编辑了代码,要求用git pull,才能继续deploy
● ![rejected] master->master(fetch first)
● error:failed to push some refs to 'https://github.com/xxx/xxx.git'
git pull
本地上的测试代码,用到reqhelper.py里面的 SavePostResponse function ,其它是不用理会
reqhelper.py
#encoding=utf-8
import time
import traceback
import requests
import json
import confhelper
import os
from bs4 import BeautifulSoup #__version__ = 4.3.2
from urlparse import urljoin
import threadpool
import sys
class ReqHelper(object):
def __init__(self, url=r'http://www.baidu.com',headers={}, outfile=r'd:templog.txt',proxies={},timeout=3):
self.confile = r"..conftest.conf"
if os.path.exists(self.confile):
self.conf=confhelper.ConfHelper(self.confile)
self.confs = self.conf.GetAllConfig()
if not(url.startswith('http://')) and not(url.startswith('https://')):
url = 'http://'+url
#代理格式 http://user:password@host/
if len(proxies)==0 and self.confs.has_key("username") and self.confs.has_key("password") and self.confs.has_key("httpserver"):
proxies['http'] ="http://%s:%s@%s"%(self.confs["username"],self.confs["password"],self.confs["httpserver"])
proxies['https'] ="http://%s:%s@%s"%(self.confs["username"],self.confs["password"],self.confs["httpsserver"])
self.proxies = proxies
#SOCKS 代理格式 socks5://user:pass@host:port
'''proxies = {
'http': 'socks5://user:pass@host:port',
'https': 'socks5://user:pass@host:port'
}'''
if len(headers)==0:
headers={'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'
,'Accept-Encoding':'gzip,deflate,sdch'
,'Accept-Language':'zh-CN,zh;q=0.8'
,'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'
,'Content-Type':'application/x-www-form-urlencoded'}
self.headers = headers
self.url = url
if outfile=="" and self.confs.has_key("logpath"):
outfile=self.confs["logpath"]
self.outfile = outfile
self.session = requests.session()
self.session.proxies=self.proxies
if self.confs.has_key("theadnum") and self.confs["theadnum"].isdigit():
self.theadnum = int(self.confs["theadnum"])
else :
self.theadnum = 10
#下载文件到本地
def DownloadFile(self,sourceurl,destdir):
try:
with requests.Session() as s:
s = requests.Session()
r = s.get(sourceurl,headers=self.headers)
destfile = os.path.join(destdir,os.path.basename(sourceurl))
with open(destfile,"wb") as file:
file.write(r.content)
print time.ctime(), 'Download :',sourceurl,'nTo :',destfile
except Exception,e:
print time.ctime(), 'Error :',e.message,'n',traceback.format_exc()
# 如果目录不存在就新建
def GetDownloadPath(self,dp=""):
if dp=="":
dp=self.confs["downloadpath"]
if not os.path.exists(dp):
os.mkdir(dp)
return dp
# 按条件取出网页上所有href地址
def GetHrefs(self,func, url):
r = requests.get(url, proxies=self.proxies,headers=self.headers,timeout=3)
bs = BeautifulSoup(r.text) #解析获取的网页
links=bs.find_all('a')
newls=filter(func,links)
durls=[]
for link in newls:
hrefstr = link['href']
if not hrefstr.startswith('http'):
if not url.endswith('/'):
url = url + '/'
durls.append(urljoin(url,hrefstr))
#去重
durls = list(set(durls))
return durls
# 下载网页上所有文件
def DownloadUrlFiles(self,func=None,url="",dp=""):
#func=lambda x:x['href'].endswith('.ipk')
#func=None
dp = self.GetDownloadPath(dp)
data=[]
if len(url) > 0:
durls=self.GetHrefs(func,url)
for durl in durls:
data.append(((durl,dp), None))
else:
urls = self.conf.GetSectionConfig("downloadurlfiles")
for (dkey,durl) in urls.items():
destdir = os.path.join(dp,dkey)
destdir = self.GetDownloadPath(destdir)
durls = self.GetHrefs(func,durl)
for durl in durls:
data.append(((durl,destdir), None))
#for durl in durls:
# self.DownloadFile(durl,dp)
#用多线程下载
pool = threadpool.ThreadPool(self.theadnum)
reqs = threadpool.makeRequests(self.DownloadFile, data)
[pool.putRequest(req) for req in reqs]
pool.wait()
# 下载单个文件链接
def DownloadUrlFile(self,url="",dp=""):
dp = self.GetDownloadPath(dp)
if len(url) > 0:
self.DownloadFile(url,dp)
else:
urls = self.conf.GetSectionConfig("downloadurlfile")
for (dkey,durl) in urls.items():
#dfname = os.path.join(dp,fkey)
self.DownloadFile(durl,dp)
# 保存网页内容
def SaveHtmlContent(self,r,outfile="",writemode='a'):
if outfile == "" and writemode == 'a' and self.confs.has_key("logpath"):
outfile = self.confs["logpath"]
if outfile == "" and writemode == 'w' and self.confs.has_key("htmlpath"):
outfile = self.confs["htmlpath"]
f = file(outfile, writemode)
if writemode=='a':
lines=[r.request.method,'n',r.request.url,'n',str(r.headers),'n',str(r.request.body),'n',r.url,'n',str(r.status_code),'n', str(r.headers),'n',r.text.encode('utf-8','ignore')]
print lines
f.writelines(lines)
if writemode=='w':
f.write(r.text.encode('utf8'))
f.close()
# 测试网址是否能打开
def TestUrls(self,save=False):
httpurls=self.conf.GetSectionConfig("httpurl")
httpsurls=self.conf.GetSectionConfig("httpsurl")
urls=dict(httpurls,**httpsurls)
for (urlkey,url) in urls.items():
try:
if not(url.startswith('http://')) and not(url.startswith('https://')):
url = 'http://'+url
r = requests.get(url, proxies=self.proxies,headers=self.headers,timeout=3)
print time.ctime(),r.url," Reponse status code :",r.status_code
if save == True:
self.SaveHtmlContent(r,self.outfile,'a')
except Exception,e:
print time.ctime(), 'Error:',e.message,'n',traceback.format_exc()
def SaveHtml(self, user='', password = '', outfile=''):
r = requests.get(self.url, auth=(user, password))
self.SaveHtmlContent(r,outfile,'w')
# 用同一个会话打开链接
def SaveHtmlAfterLogin(self, geturl, user='', password = '',outfile=''):
r = requests.get(self.url, auth=(user, password))
s = requests.Session()
r = s.get(geturl)
self.SaveHtmlContent(r,outfile,'w')
def SavePostResponse(self, data={}, cookies={} , outfile=''):
r = requests.post(self.url,data=data, cookies=cookies)
self.SaveHtmlContent(r,outfile,'w')
def SaveResponseWithCookie(self, headers={'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'
,'Accept-Encoding':'gzip,deflate,sdch'
,'Accept-Language':'zh-CN,zh;q=0.8'
,'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'
,'Content-Type':'application/x-www-form-urlencoded'}
, cookies={}):
r = requests.get(self.url, headers=headers,cookies=cookies);
f = file(self.outfile, 'w')
f.write(json.dumps(r.headers.__dict__))
f.write('n')
f.write(r.text.encode('utf8'))
f.close()
def GetCookies(self, user='', password = ''):
r = requests.get(self.url, auth=(user, password))
return r.headers["Set-Cookie"]
if __name__ == '__main__':
''' test.conf
#reqhelper
[httpurl]
baidu=http://www.baidu.com
openwrt=http://downloads.openwrt.org/barrier_breaker/14.07/ramips/mt7620a/packages/base
json=https://api.github.com/repositories/1362490/git/commits/a050faf084662f3a352dd1a941f2c7c9f886d4ad
[httpsurl]
[downloadurlfiles]
#baseipk=http://downloads.openwrt.org/barrier_breaker/14.07/ramips/mt7620a/packages/base/
luciipk=http://downloads.openwrt.org/barrier_breaker/14.07/ramips/mt7620a/packages/luci/
managementipk=http://downloads.openwrt.org/barrier_breaker/14.07/ramips/mt7620a/packages/management/
oldpackagesipk=http://downloads.openwrt.org/barrier_breaker/14.07/ramips/mt7620a/packages/oldpackages/
routing=http://downloads.openwrt.org/barrier_breaker/14.07/ramips/mt7620a/packages/routing/
telephony=http://downloads.openwrt.org/barrier_breaker/14.07/ramips/mt7620a/packages/telephony/
[downloadurlfile]
ipk1=http://downloads.openwrt.org/barrier_breaker/14.07/ramips/mt7620a/packages/base/6in4_17-1_all.ipk
ipk2=http://downloads.openwrt.org/barrier_breaker/14.07/ramips/mt7620a/packages/base/agetty_2.24.1-1_ramips_24kec.ipk
'''
url="http://www.sobaidupan.com/search.asp?wd=pyspider&so_md5key=7db75ceb9f6873de9fb027aa3a7cd7"
req = ReqHelper(url=url)
#保存某个网页
req.SaveHtml(url,outfile=r"d:temptest.html")
#测试网址
req.TestUrls()
if len(sys.argv) > 1 and sys.argv[1]=="download":
#下载文件
req.DownloadUrlFiles(func=lambda x:x['href'].endswith('.ipk'),url="",dp="")
>>> wxlink="http://1.wxpy.applinzi.com/"
>>> req2=reqhelper.ReqHelper(wxlink)
>>> textdata=
'<xml>n<ToUserName>n<![CDATA[fromUser]]>n</ToUserName>n<FromUserName>n<![CDATA[toUser]]>
n</FromUserName>n<CreateTime>1503586446</CreateTime>n<MsgType>n<![CDATA[text]]>n</MsgType>
n<Content>n<![CDATA[this is a test]]>n</Content>n<FuncFlag>0</FuncFlag>n</xml>'
>>> req2.SavePostResponse(data=textdata)
总结下SAE遇到的坑:
1.一个应用扣了10个云豆,刚开始觉得好乐观,一进账户送了200个,实名认证又送了300个,后来才知道是每天扣10个云豆。。。这样也一个应用只能用一个月而已
2.mysql数据库要收费我预料到,想着自己玩下用sqlite就好了,但自带的sqlite它居然不支持。。。真绝
3.好吧,我不用数据库了,用pandas把取到的数据处理下吧,毕竟官方也说可以在vendor目录下放第三方包的,可是比方说pyquery require lxml库,pandas require numpy,six,pytz,无论我全部拷进vendor目录还是用pip install -t vendor pandas
当把代码deploy去sae后,总是import module报错。
4.这些第三方包太大,上传着居然说我达到限额了,应用空间的5G size实在给了我太乐观的假象。


5.代码管理是可以在线编辑代码的,虽然慢点,但有时候懒得敲命令。可是,原来这样修改应用不生效的,一定要用git bash来deploy.
也没有个手动重启应用的功能,而且这样改还会需要再pull一次才行。
6.sae上使用logging没有用,可以直接用print打印出信息,在日志那里可以看到
写了个travelhelper.py文件用来拿珠海户外网发布的活动,代码在git上,本地测试Ok,无奈SAE上import module错误不知怎样fix
代码放在github上
https://github.com/sui84/sae
转载于:https://www.cnblogs.com/sui84/p/7435225.html
最后
以上就是优雅歌曲最近收集整理的关于在新浪SAE上搭建微信公众号的python应用的全部内容,更多相关在新浪SAE上搭建微信公众号内容请搜索靠谱客的其他文章。








发表评论 取消回复