最近一直在使用各种Embedding的方法,于是好奇的看到了NNLM,总结一下自己的理解。
Forward
首先,我们假设一句话由 w = ( w 1 , w 2 , . . . , w t ) w=(w_1,w_2,...,w_t) w=(w1,w2,...,wt)组成( w i w_i wi为单词),在语言模型中计算一句话的概率,我们用 w 1 , w 2 , . . . , w t w_1,w_2,...,w_t w1,w2,...,wt的联合概率来表示一句话的概率。如下:
p ( w ) = p = ( w 1 , w 2 , . . . , w t ) (1) bm{p(w)=p=(w_1,w_2,...,w_t)}tag1 p(w)=p=(w1,w2,...,wt)(1)
也可以来判断一句话是否通顺,都是一个意思,通过条件概率得到如下变形:
P
(
w
1
,
w
2
,
…
,
w
t
)
=
P
(
w
t
∣
w
t
−
1
,
…
,
w
2
,
w
1
)
∗
P
(
w
t
−
1
,
…
,
w
2
,
w
1
)
=
p
(
w
1
)
∗
p
(
w
2
∣
w
1
)
∗
p
(
w
3
∣
w
1
,
w
2
)
∗
.
.
.
.
.
.
∗
p
(
w
n
∣
w
1
,
.
.
.
.
.
.
,
w
n
−
1
)
(2)
begin{array}{ll} P(w_1, w_2, … , w_t)& = P(w_t | w_{t-1}, … , w_2, w_1) * P(w_{t-1}, … , w_2, w_1)tag2 \\ & = p(w_1)*p(w_2|w_1)*p(w_3|w_1,w_2)*......*p(w_n|w_1,......,w_{n-1}) end{array}
P(w1,w2,…,wt)=P(wt∣wt−1,…,w2,w1)∗P(wt−1,…,w2,w1)=p(w1)∗p(w2∣w1)∗p(w3∣w1,w2)∗......∗p(wn∣w1,......,wn−1)(2)
根据马尔可夫假设,我们可以类似的认为离t最近n-1个词和它相关,从而可以得到:
P
(
w
t
∣
w
t
−
1
,
…
,
w
2
,
w
1
)
=
P
(
w
t
∣
w
t
−
1
,
w
t
−
2
,
…
,
w
t
−
n
+
1
)
(3)
bm{P(w_t | w_{t-1}, … , w_2, w_1)=P(w_t | w_{t-1}, w_{t-2}, … , w_{t-n+1})tag3}
P(wt∣wt−1,…,w2,w1)=P(wt∣wt−1,wt−2,…,wt−n+1)(3)
另外,插一点题外话,若我们这里认为只和最近的1个词相关,便成了2-gram,同时我们可以把公式(2)变形如下:
P
(
w
1
,
w
2
,
…
,
w
t
)
=
P
(
w
t
∣
w
t
−
1
,
…
,
w
2
,
w
1
)
∗
P
(
w
t
−
1
,
…
,
w
2
,
w
1
)
=
p
(
w
1
)
∗
p
(
w
2
∣
w
1
)
∗
p
(
w
3
∣
w
1
,
w
2
)
∗
.
.
.
.
.
.
∗
p
(
w
n
∣
w
1
,
.
.
.
.
.
.
,
w
n
−
1
)
=
p
(
w
1
)
∗
p
(
w
2
∣
w
1
)
∗
p
(
w
3
∣
w
2
)
∗
.
.
.
.
.
.
∗
p
(
w
n
∣
w
n
−
1
)
(2*)
begin{array}{ll} P(w_1, w_2, … , w_t)& = P(w_t | w_{t-1}, … , w_2, w_1) * P(w_{t-1}, … , w_2, w_1)tag{2*} \\ & = p(w_1)*p(w_2|w_1)*p(w_3|w_1,w_2)*......*p(w_n|w_1,......,w_{n-1})\\ & = p(w_1)*p(w_2|w_1)*p(w_3|w_2)*......*p(w_n|w_{n-1}) end{array}
P(w1,w2,…,wt)=P(wt∣wt−1,…,w2,w1)∗P(wt−1,…,w2,w1)=p(w1)∗p(w2∣w1)∗p(w3∣w1,w2)∗......∗p(wn∣w1,......,wn−1)=p(w1)∗p(w2∣w1)∗p(w3∣w2)∗......∗p(wn∣wn−1)(2*)
回归正题,我们这里假设词典为10000个词。分别对语料中的词进行one-hot编码(词典为语料中不重复的单词)。
一般来说,这个n是一个比较小的值。我们这里假设n=6,那么n-1=5.那么,我们可以认为输入是5个one-hot向量,我们把这个向量拼成一个[5 * 10000]的矩阵,由于向量的维度通常比较高,我们进行降维处理:右乘一个[10000 *100]的权重矩阵得到一个[5 * 100]的矩阵(这里不一定是100,只是举个例子)。
上面的这一段在原文里面其实是没有的,这样讲解是为了更好的理解,论文里面是通过index在C中进行一个查表操作。其实道理是一样的。
这个过程我们也可以理解为从one-hot到distributed representation的转化过程。这样就得到了特征向量。根据论文 Nerual Network Language Model写道:
a function g maps an input sequence of feature vectors for words in context, ( C ( w t − n + 1 ) , ⋅ ⋅ ⋅ , C ( w t − 1 ) ) (C(w_{t−n+1}),··· ,C(w_{t−1})) (C(wt−n+1),⋅⋅⋅,C(wt−1)), to a conditional probability distribution over words in V for the next word w t w_t wt
上面的 ( C ( w t − n + 1 ) , ⋅ ⋅ ⋅ , C ( w t − 1 ) ) (C(w_{t−n+1}),··· ,C(w_{t−1})) (C(wt−n+1),⋅⋅⋅,C(wt−1))就是我们得到的特征向量,作者通过一个映射g来得到对 w t w_t wt.的预测,
这个映射的设计结构如下图:
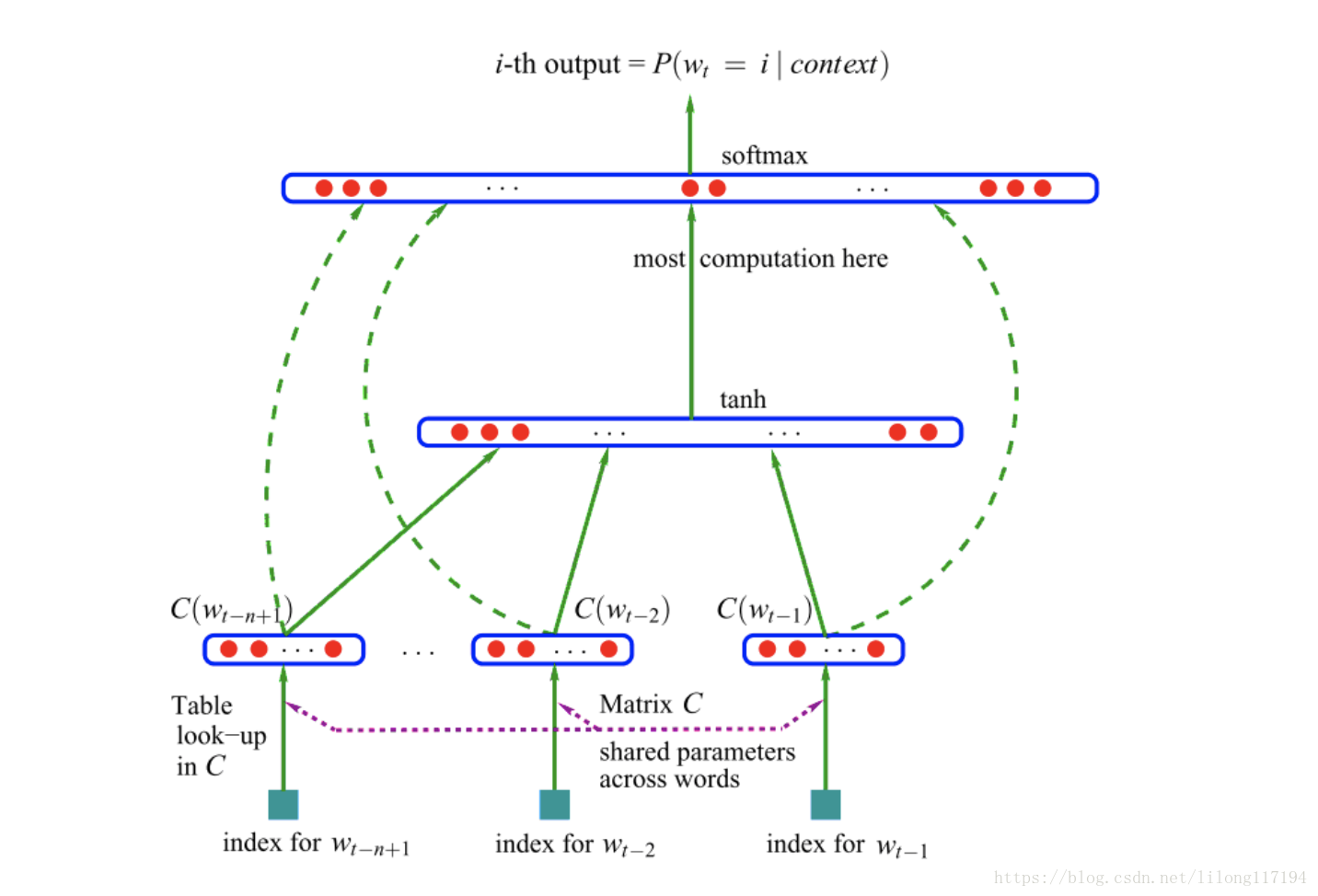
先是将特征向量进行拼接,也就是5*100的矩阵,拼接成一个500维的向量( x x x),然后将这个向量( x x x)
经过 (4) 线性变换之后,再经过tanh处理得到一个100维的向量,如(5):
y 1 = U t a n h ( d + H x ) (4) bm{y_1=U tanh(d+Hx)}tag4 y1=Utanh(d+Hx)(4)
[ 100 ∗ 500 ] ∗ [ 500 ∗ 1 ] = [ 100 ∗ 1 ] (5) bm{[100*500]*[500*1]=[100*1]}tag5 [100∗500]∗[500∗1]=[100∗1](5)
然后左乘U得到 一个10000维的向量
y
1
y_1
y1,如(6):
[
10000
∗
100
]
∗
[
100
∗
1
]
=
[
10000
∗
1
]
(6)
bm{[10000*100]*[100*1]=[10000*1]tag6}
[10000∗100]∗[100∗1]=[10000∗1](6)
接下来是对输入特征向量(
x
x
x)的处理 ,(
x
x
x)左乘一个[10000 * 500]的矩阵得到一个[10000 * 1]的向量:
y
2
=
b
+
W
x
(7)
bm{y_2 = b+Wxtag7}
y2=b+Wx(7)
[ 10000 ∗ 500 ] ∗ [ 500 ∗ 1 ] = [ 10000 ∗ 1 ] (8) bm{[10000*500]*[500*1]=[10000*1]tag8} [10000∗500]∗[500∗1]=[10000∗1](8)
将上面
y
1
和
y
2
y_1和y_2
y1和y2相加就得到了最终的向量
y
=
y
1
+
y
2
(9)
bm{y=y_1+y_2tag9}
y=y1+y2(9)
y
=
b
+
W
x
+
U
t
a
n
h
(
d
+
H
x
)
(10)
bm{y = b+Wx+U tanh(d+Hx)tag{10}}
y=b+Wx+Utanh(d+Hx)(10)
y
y
y是一个10000的向量,这里的x为特征向量,
W
,
U
,
H
都
为
权
重
,
b
,
d
为
b
i
a
s
W,U, H都为权重,b, d为bias
W,U,H都为权重,b,d为bias。然后通过softmax得到对
w
t
w_t
wt的预测:
P
(
w
t
∣
w
t
−
1
,
⋅
⋅
⋅
w
t
−
n
+
1
)
=
e
y
w
,
i
∑
i
N
e
y
w
,
i
(11)
bm{P(w _t |w_{t−1} ,···w_{t−n+1} ) =frac{e ^{y{_w}{_,}{_i}}}{∑_ i^N e ^{y_w{_,}_i}}tag{11}}
P(wt∣wt−1,⋅⋅⋅wt−n+1)=∑iNeyw,ieyw,i(11)
也就是当上下文为content(
w
w
w)时,
w
t
w_t
wt为字典中第i个词的概率。
Back propagation
损失函数: L = ∑ w ∈ c l o g p ( w ∣ c o n t e x t ( w ) ) (12) bm{L =∑_{w in c}log p(w|context(w))tag{12}} L=w∈c∑logp(w∣context(w))(12)
接下来对目标函数进行梯度上升求解即可。
最后
以上就是悲凉康乃馨最近收集整理的关于浅谈神经网络语言模型(NNLM)的理解的全部内容,更多相关浅谈神经网络语言模型(NNLM)内容请搜索靠谱客的其他文章。








发表评论 取消回复