作者:tiandi,小米AI实验室,智能问答、智能客服方向。
专栏地址:
http://www.52nlp.cn/author/tiandiweizun
中文分词工具评估项目地址:
https://github.com/tiandiweizun/chinese-segmentation-evaluation
最近我们分享了一些关于分词的事情,对于琳琅满目的分词工具,我们到底该选择哪个呢?
这里有一个Java开源项目cws_evaluation,对中文分词做了评比,但有几点不足:(1). 只有java版本,但是机器学习主要是基于python的 (2).效果指标为行完美率和字完美率,该指标不妥,特别是句子越长,越无意义,(3). 每种分词工具评测的算法太多了,这里仅评比了默认的分词算法。
基于此,我做了一个java和python版本中文分词工具评比项目chinese-segmentation-evaluation。
项目简介
测试了java和python常见中文分词工具的效果和效率
java
Requirement
java8
步骤
git clone https://github.com/tiandiweizun/nlp-evaluation.gitcd nlp-evaluation/java(windows)
.gradlew.bat build(linux)./gradlew buildjava -Dfile.encoding=utf-8 -jar build/libs/nlp-evaluation-java-1.0.0.jar
说明
java -jar nlp-evaluation-java-1.0.0.jar 有3个参数,可以执行 java -jar nlp-evaluation-java-1.0.0.jar -h 查看-i 分词文件,默认为data/seg.data_big文件,每行一个句子,每个词用空格分开,可以指定自己的测试集-o 分词结果存储路径,默认不存储-n 最大读取分词文件行数-c 需要评估的分词器名称,用英文逗号隔开,默认HanLP,jieba,thulac,示例: -c=HanLP
由于斯坦福分词效果一般,速度极慢,且模型巨大,在打包的时候已经排除(不影响在IDE里面测试), 打包如果要包含斯坦福分词,修改build.gradle,注释掉exclude(dependency('edu.stanford.nlp:stanford-corenlp'))
由于Word、Ansj、Jcseg、MMSeg4j存在bug(把词语拼接起来和原始句子不一样),在代码里面已经注释掉了,不进行测试。
依赖的库均存在于maven中心仓库,像庖丁、复旦分词等找不到的,这里没有测试
测试效果
总行数:2533709 总字符数:28374490
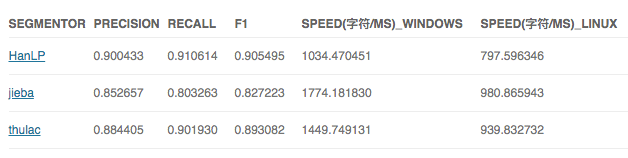
经过多次测试发现,thulac在linux上速度不是特别稳定,最快与jiba差不多
开发者
建议使用idea打开或者导入java目录,把data目录拷贝到java目录,直接可以运行SegEvaluation调试。
可以打开stanford和其他分词器
评测自定义分词器:继承Seg类并实现segment方法,添加到evaluators即可。
python
Requirement
Python:3
其他参见 requirements.txt
步骤
1. git clone https://github.com/tiandiweizun/nlp-evaluation.git
2. cd nlp-evaluation
3. pip3 install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
4. cd python/indi.tiandi.nlp.evaluation
5. python3 SegEvaluation.py
说明
python3 SegEvaluation.py 有3个参数,可以执行 python3 SegEvaluation.py -h 查看-i 分词文件,默认为data/seg.data_big文件,每行一个句子,每个词用空格分开,可以指定自己的测试集-o 分词结果存储路径,默认不存储-n 最大读取分词文件行数,由于python速度太慢,建议设置-c 需要评估的分词器名称,用英文逗号隔开,默认pkuseg,jieba_fast,thulac
pynlpir存在bug(把词语拼接起来和原始句子不一样),pyltp在windows上不易安装,这里都没有进行测试,比较慢的也没有测试
测试效果
总行数:2533709 总字符数:28374490
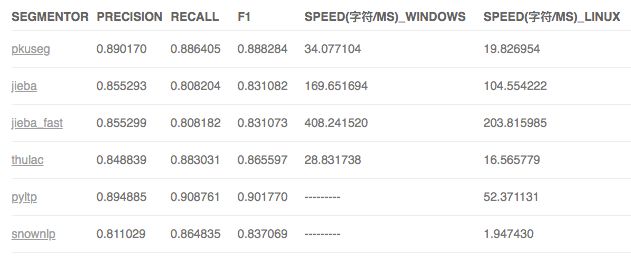
开发者
建议使用pycharm打开python目录,即可运行
如果需要使用pynlpir,需要修改pynlpir_path的安装目录
如果需要使用pyltp,需要修改ltp_data_dir的模型分词目录
评测自定义分词器:只要实现segment方法和向evaluators追加即可。
总结
性能:java 远高于python,至少差了一个数量级。
效果:对于jieba和thulac,在python和java上表现的不同,需要更多的时间去寻找原因,且java的thulac4j非官方提供。
数据:默认数据集来源于cws_evaluation,该项目为评估中文分词的性能与效果,对于效果该项目采用的是行完美率这个指标,但是对于长句,这个指标会变的不合适,如果不同算法的错误率不一样,但是如果有一个错的词,会导致整个句子都是错的,不能很好的区分算法的precision
相关文章:
Python中文分词工具大合集:安装、使用和测试
中文分词工具在线PK新增:FoolNLTK、LTP、StanfordCoreNLP
五款中文分词工具在线PK: Jieba, SnowNLP, PkuSeg, THULAC, HanLP
中文分词文章索引和分词数据资源分享
最后
以上就是和谐铃铛最近收集整理的关于中文分词_中文分词工具评估:chinesesegmentationevaluation的全部内容,更多相关中文分词_中文分词工具评估内容请搜索靠谱客的其他文章。








发表评论 取消回复