多任务学习(Multi-task learning)简介
多任务学习(Multi-task learning)是迁移学习(Transfer Learning)的一种,而迁移学习指的是将从源领域的知识(source domin)学到的知识用于目标领域(target domin),提升目标领域的学习效果。 而多任务学习也是希望模型同时做多个任务时,能将其他任务学到的知识,用于目标任务中,从而提升目标任务效果。
如果我们换个角度理解,其实多任务学习,其实是对目标任务做了一定的约束,或者叫做regularization。我们不希望模型只局限于目标任务的学习,而是能够适应多个任务场景,这样可以大大的增加模型的泛函能力(generalization)。
举个形象的例子,单人多任务学习模型就像一个一门心思只做一样事情的匠人,在他自己的领域,他可能可以做一百分,如果换个任务也许他就会做的不是特别好,而多任务学习模型就像一个什么任务都做得还算优秀但是不完美的人。可是在实际深度学习任务中,测试集和训练集的分布还是会有一定的偏差,那测试集可能就意味给让模型做一个目标微调后任务。所以在测试集上,多任务模型大概率是表现优异那一个。
这里需要强调一点,这里的多任务的各个任务之间一定要有强相关性,如果任务之间本身的关联性就不大,多任务学习并不会对模型的提升并不一定会有用。
多任务学习(Multi-task learning)的两种模式
深度学习中两种多任务学习模式:隐层参数的硬共享与软共享。 + 隐层参数硬共享,指的是多个任务之间共享网络的同几层隐藏层,只不过在网络的靠近输出部分开始分叉去做不同的任务。 + 隐层参数软共享,不同的任务使用不同的网络,但是不同任务的网络参数,采用距离(L1,L2)等作为约束,鼓励参数相似化。
而本次的代码实现采用的是隐层参数硬共享,也就是两个任务共享网络浅层的参数。
多任务学习keras实现
这里笔者简单的介绍一下如何通过keras简单的搭建一个多任务学习网络。
这里笔者的目标任务是一个10分类的关系分类任务,对关系分类任务不是很了解的同学可以移步到笔者之前的文章中去了解一下,而我将训练文本中两个存在关系的实体(entity)标了出来,在模型中加了一个命名体识别(NER)任务构成了多任务学习模型。 笔者的网络架构如下图所示: + 句子向量和位置向量拼接构成模型的输入, + 经过一层共享的LSTM编码层,后模型开始分叉, + 其中一条路径是经过一层MaxPooling和以及全连接层后输出文本分类的预测输出, + 另外一条路径是经过一层CRF层后输出命名实体识别的预测输出。
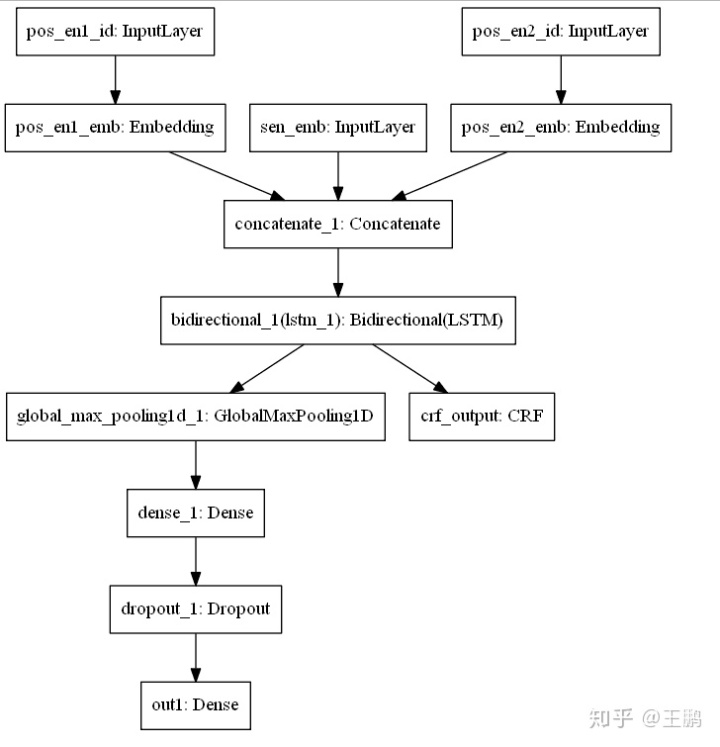
模型代码部分
这里模型构建不需要注意,笔者这里强调的是: + 各个任务的输出层一定要命名,比如笔者这个模型的文本分类任务的输出层Dense(10, activation='softmax',name = "out1")(out1)中的name ="out1",以及NER的输出层crf = CRF(2, sparse_target=True,name ="crf_output")中的name ="crf_output"不能省略。
- 第二个就是model.compile中的loss和loss的权重需要和任务输出层的name进行对应,如下: loss={'out1': 'categorical_crossentropy','crf_output': crf.loss_function} loss_weights={'out1':1, 'crf_output': 1}
下面是实现代码,发现没有,Keras搭建多任务学习模型是不是So easy。
from keras.layers import Input,LSTM,Bidirectional,Dense,Dropout,Concatenate,Embedding,GlobalMaxPool1D
from keras.models import Model
from keras_contrib.layers import CRF
import keras.backend as K
from keras.utils import plot_model
K.clear_session()
maxlen = 40
###输入
inputs = Input(shape=(maxlen,768),name="sen_emb")
pos1_en = Input(shape=(maxlen,),name="pos_en1_id")
pos2_en = Input(shape=(maxlen,),name="pos_en2_id")
pos1_emb = Embedding(maxlen,8,input_length=maxlen,name = "pos_en1_emb")(pos1_en)
pos2_emb = Embedding(maxlen,8,input_length=maxlen,name = "pos_en2_emb")(pos2_en)
x = Concatenate(axis=2)([inputs,pos1_emb,pos2_emb])
###参数共享部分
x = Bidirectional(LSTM(128,return_sequences=True))(x)
###任务一,10分类的文本分类任务
out1 = GlobalMaxPool1D()(x)
out1 = Dense(64, activation='relu')(out1)
out1 = Dropout(0.5)(out1)
out1 = Dense(10, activation='softmax',name = "out1")(out1)
###任务二,实体识别任务
crf = CRF(2, sparse_target=True,name ="crf_output")
crf_output = crf(x)
###模型有两个输出out1,crf_output
model = Model(inputs=[inputs,pos1_en,pos2_en], outputs=[out1,crf_output])
model.summary()
###模型有两个loss,categorical_crossentropy和crf.loss_function
model.compile(optimizer='adam',
loss={'out1': 'categorical_crossentropy','crf_output': crf.loss_function},
loss_weights={'out1':1, 'crf_output': 1},
metrics=["acc"])
plot_model(model,to_file="model.png")结语
笔者利用这个多任务学习的模型和去掉CRF实体识别分支的单任务模型做了对比实验,确实多任务学习模型比单任务模型在测试集上的F1得分要好2个百分点左右。多任务训练模型的泛化能力确实很强。如果你的深度学习模型遇到瓶颈了,可以尝试一下多任务学习模型哦。
参考文献
https://blog.csdn.net/xuluohongshang/article/details/79044325
最后
以上就是单纯路人最近收集整理的关于crf的实现 keras_深度学习中的多任务学习(Multi-task-learning)——keras实现的全部内容,更多相关crf的实现内容请搜索靠谱客的其他文章。
![Keras 实现细节——dropout在训练阶段与测试阶段的使用分析0. 写作目的1. Dropout 的实现方式2. 实验验证Dropout的实现(也可以通过源码查看)3. 实验结果4. 实验结论[Reference]](https://www.shuijiaxian.com/files_image/reation/bcimg13.png)




![[论文笔记] Fine-Grained Head Pose Estimation Without KeypointsFine-Grained Head Pose Estimation Without Keypoints](https://www.shuijiaxian.com/files_image/reation/bcimg18.png)


发表评论 取消回复