最近在多个关键词(小数据集,无监督半监督,图像分割,SOTA模型)的范畴内,都看到了这样的一个概念,孪生网络,所以今天有空大概翻看了一下相关的经典论文和博文,之后做了一个简单的案例来强化理解。如果需要交流的话欢迎联系我,WX:cyx645016617。
所以这个孪生网络入门,我想着分成上下两篇,上篇也就是这一篇讲解模型理论、基础知识和孪生网络独特的损失函数;下篇讲解一下如何用代码来复线一个简单的孪生网络。
1 名字的由来
孪生网络的别名就会死Siamese Net,而Siam是古代泰国的称呼,所以Siamese其实是“泰国人”的古代的称呼。 为什么Siamese现在在英文中是“孪生”“连体”的意思呢?这源自一个典故:
十九世纪泰国出生了一对连体婴儿,当时的医学技术无法使两人分离出来,于是两人顽强地生活了一生,1829年被英国商人发现,进入马戏团,在全世界各地表演,1839年他们访问美国北卡罗莱那州后来成为“玲玲马戏团” 的台柱,最后成为美国公民。1843年4月13日跟英国一对姐妹结婚,恩生了10个小孩,昌生了12个,姐妹吵架时,兄弟就要轮流到每个老婆家住三天。1874年恩因肺病去世,另一位不久也去世,两人均于63岁离开人间。两人的肝至今仍保存在费城的马特博物馆内。从此之后“暹罗双胞胎”(Siamese twins)就成了连体人的代名词,也因为这对双胞胎让全世界都重视到这项特殊疾病。

2 模型结构
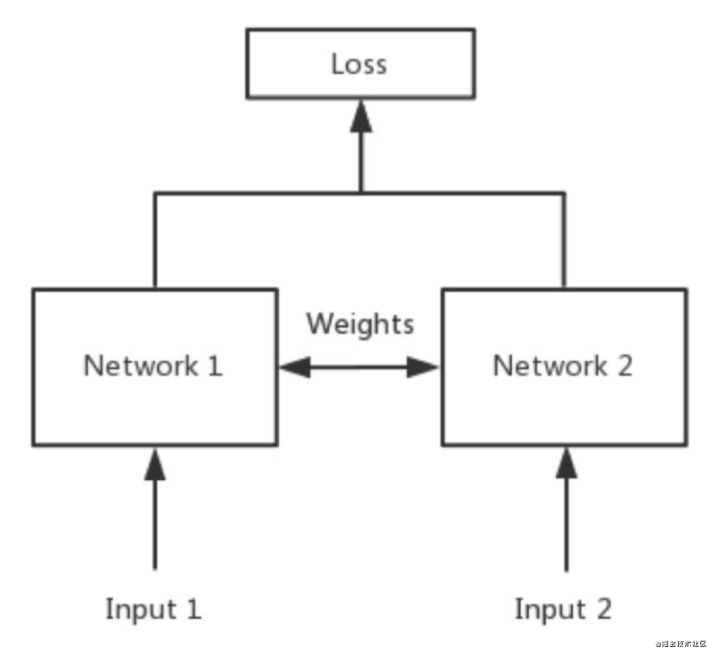
这个图有这几个点来理解:
- 其中的Network1和Network2按照专业的话来说就是共享权制,说白了这两个网络其实就是一个网络,在代码中就构建一个网络就行了;
- 一般的任务,每一个样本经过模型得到一个模型的pred,然后这个pred和ground truth进行损失函数的计算,然后得到梯度;这个孪生网络则改变了这种结构,假设是图片分类的任务,把图片A输入到模型中得到了一个输出pred1,然后我再把图片B输入到模型中,得到了另外一个输出pred2,然后我这个损失函数是从pred1和pred2之间计算出来的。 就是一般情况下,模型运行一次,给出一个loss,但是在siamese net中,模型要运行两次才能得到一个loss。
- 我个人感觉,一般的任务像是衡量一种绝对的距离,样本到标签的一个距离;但是孪生网络衡量的是样本到样本之间的一个距离。
2.1 孪生网络的用途
Siamese net衡量的是两个输入的关系,也就是两个样本相似还是不相似。
有这样的一个任务,在NIPS上,在1993年发表了文章《Signature Verification using a ‘Siamese’ Time Delay Neural Network》用于美国支票上的签名验证,检验支票上的签名和银行预留的签名是否一致。当时论文中就已经用卷积网络来做验证了…当时我还没出生。
之后,2010年Hinton在ICML上发表了《Rectified Linear Units Improve Restricted Boltzmann Machines》,用来做人脸验证,效果很好。输入就是两个人脸,输出就是same or different。

可想而知,孪生网络可以做分类任务。在我看来,孪生网络不是一种网络结构,不是resnet那种的网络结构,而是一种网络的框架,我可以把resnet当成孪生网络的主干网络这样的。
既然孪生网络的backbone(我们暂且这样叫,应该可以理解的把)可以是CNN,那么也自然可以是LSTM,这样可以实现词汇的语义的相似度分析。
之前Kaggle上有一个question pair的比赛,衡量两个问题是否提问的是同一个问题这样的比赛,TOP1的方案就是这个孪生网络的结构Siamese net。
后来好像还有基于Siamese网络的视觉跟踪算法,这个我还没有了解,以后有机会的话我看一看这个论文。《Fully-convolutional siamese networks for object tracking》。先挖一个坑。
2.2 伪孪生网络
问题来了,孪生网络中看似两个网络,实则共享权制为一个网络,假设我们真的给他弄两个网络,那样不就可以一个是LSTM,一个CNN实现不同模态的相似度比较了?
没错,这个叫做pseudo-siamese network 伪孪生网络。一个输入是文字,一个输入是图片,判断文字描述是否是图片内容;一个是短标题,一个是长文章,判断文章内容是否是标题。(高中语文作文常年跑题选手的救星,以后给老师说这个算法说我的文章没有跑题,您要不再看看?老师会打死我吗)
不过本文和下一篇的代码都是以siamese network为核心,backbone也以CNN卷积网络和图像展开。
2.3 三胞胎
既然有了二胞胎的网络,当然也有三胞胎,叫做Triplet network《Deep metric learning using Triplet network》。据说效果已经好过Siamese network了,不知道有没有四胞胎和五胞胎。
3 损失函数
分类任务常规使用softmax加上交叉熵,但是有人提出了,这种方法训练的模型,在“类间”区分性上表现的并不好,使用对抗样本攻击就立刻不行了。后续有空讲解一下对抗样本攻击,再挖个坑。 简单的说就是,假设是人脸识别,那么每个人就是一个类别,那么你让一个模型做一个几千分类的任务,每一个类别的数据又很少的情况下,想想也会感觉到这个训练的难度。
针对这样的问题,孪生网络有两个损失函数比较近经典:
- Contrastive Loss
- Triplte Loss
3.1 Contrastive Loss
- 提出论文:《Dimensionality Reduction by Learning an Invariant Mapping》
现在我们已知: - 图片1 经过模型 得到pred1
- 图片2 经过模型 得到pred2
- pred1和pred2计算得到loss
论文中给出了这样的一个计算公式:

首先呢,这个经过模型得到的pred1和pred2都是向量,过程相当于图片经过CNN提取特征,然后得到了一个隐含向量,是一个Encoder的感觉。
然后计算这两个向量的欧氏距离,这个距离(如果模型训练的正确的话),就可以反应两个输入图像的相关性。我们每次输入两个图片,我们需要事先确定这两个图像是一类的,还是不同的,这个类似一个标签,也就是上图公式中的Y。如果是一类的,那么Y为0,如果不是,Y=1
类似于二值交叉熵损失函数,我们需要注意的是:
- Y=0的时候,损失为: ( 1 − Y ) L S ( D W i ) (1-Y)L_S(D_W^i) (1−Y)LS(DWi)
- Y=1的时候,损失为: Y L D ( D W i ) YL_D(D_W^i) YLD(DWi).
- 其中论文中 L D , L S L_D,L_S LD,LS是常数,论文中默认取0.5
- i是一个次方的含义,论文中和常用的contrastive loss中,都是默认i=2,也就是欧氏距离的平方。
- 对于类别是1(different类别的),我们自然是希望pred1和pred2的欧氏距离越大越好。那么这个大到什么程度是个头呢?损失函数是往小的方向移动,那么需要做什么呢?增加一个margin,当作最大的距离。如果pred1和pred2的距离大于margin,那么就认为这两个样本距离足够大,就当其的损失为0。所以写的方法就是: m a x ( m a r g i n − d i s t a n c e , 0 ) max(margin-distance,0) max(margin−distance,0).
- 上图中的W我理解为神经网络的weight,然后 X ⃗ 1 vec X_1 X1,表示要输入的原图片。
所以损失函数就变成这个样子:
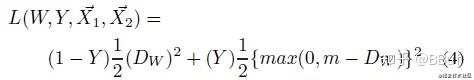
总结一下,这里面需要注意的应该就是对于different的两个图片,需要设置一个margin,然后小于margin的计算损失,大于margin的损失为0.
3.2 Contrastive Loss pytorch
# Custom Contrastive Loss
class ContrastiveLoss(torch.nn.Module):
"""
Contrastive loss function.
Based on: http://yann.lecun.com/exdb/publis/pdf/hadsell-chopra-lecun-06.pdf
"""
def __init__(self, margin=2.0):
super(ContrastiveLoss, self).__init__()
self.margin = margin
def forward(self, output1, output2, label):
euclidean_distance = F.pairwise_distance(output1, output2)
loss_contrastive = torch.mean((1-label) * torch.pow(euclidean_distance, 2) + # calmp夹断用法
(label) * torch.pow(torch.clamp(self.margin - euclidean_distance, min=0.0), 2))
return loss_contrastive
其中唯一需要谈一下的可能就是torch.nn.functional.pariwise_distance,
这个就是计算对应元素的欧氏距离,举个例子:
import torch
import torch.nn.functional as F
a = torch.Tensor([[1,2],[3,4]])
b = torch.Tensor([[10,20],[30,40]])
F.pairwise_distance(a,b)
输出为:
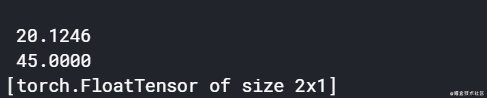
然后看一下这个数字是不是欧氏距离:
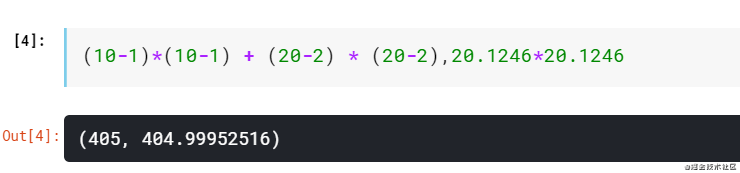
没问题的啊
3.3 Triplte Loss
- 提出论文:《FaceNet: A Unified Embedding for Face Recognition and Clustering》
这个论文提出了FactNet,然后使用了Triplte Loss。Triplet Loss即三元组损失,我们详细来介绍一下。
- Triplet Loss定义:最小化锚点和具有相同身份的正样本之间的距离,最小化锚点和具有不同身份的负样本之间的距离。这个其实应该是三胞胎网络的损失函数,同时输入三个样本,一个图片,然后一个same类别的图片和一个different图片。
- Triplet Loss的目标:Triplet Loss的目标是使得相同标签的特征在空间位置上尽量靠近,同时不同标签的特征在空间位置上尽量远离,同时为了不让样本的特征聚合到一个非常小的空间中要求对于同一类的两个正例和一个负例,负例应该比正例的距离至少远margin。如下图所示:
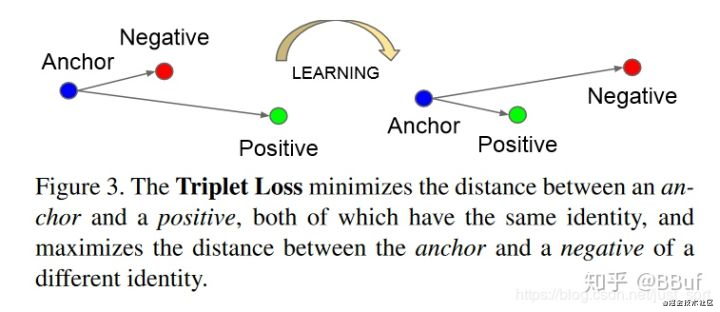
这个的话我们要如何构建损失函数呢?已知我们想要的:
- 让anchor和positive得到的向量的欧氏距离越小越好;
- 让anchor和negative得到的向量的欧氏距离越大越好;
所以期望下面这个公式成立:
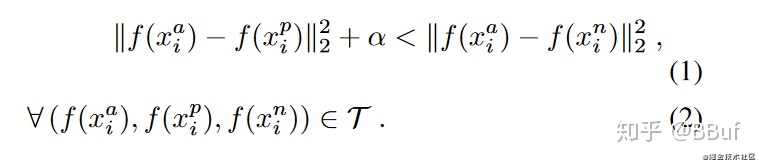
- 简单的说就是anchor和positive的距离要比anchor和negative的距离小,而且这个差距要至少要大于 α alpha α。个人的思考是,这里的T,是三元组的集合。对于一个数据集,往往可以构建出非常多的三元组,因此我个人感觉这种任务一般用在类别多,数据量较少的任务中,不然三元组数量爆炸了
3.4 Triplte Loss keras
这里有一个keras的triplte loss的代码
def triplet_loss(y_true, y_pred):
"""
Triplet Loss的损失函数
"""
anc, pos, neg = y_pred[:, 0:128], y_pred[:, 128:256], y_pred[:, 256:]
# 欧式距离
pos_dist = K.sum(K.square(anc - pos), axis=-1, keepdims=True)
neg_dist = K.sum(K.square(anc - neg), axis=-1, keepdims=True)
basic_loss = pos_dist - neg_dist + TripletModel.MARGIN
loss = K.maximum(basic_loss, 0.0)
print "[INFO] model - triplet_loss shape: %s" % str(loss.shape)
return loss
参考文献:
[1] Momentum Contrast for Unsupervised Visual Representation Learning, 2019, Kaiming He Haoqi Fan Yuxin Wu Saining Xie Ross Girshick
[2] Dimensionality Reduction by Learning an Invariant Mapping, 2006, Raia Hadsell, Sumit Chopra, Yann LeCun
最后
以上就是无情犀牛最近收集整理的关于孪生网络入门(上) Siamese Net及其损失函数的全部内容,更多相关孪生网络入门(上)内容请搜索靠谱客的其他文章。



![[keras] triplelet loss](https://www.shuijiaxian.com/files_image/reation/bcimg2.png)




发表评论 取消回复