基于Keras的MLP_AutoEncoder模型
- 什么是AutoEncoder
- 上代码演示
- MLP_AutoEncoder核心代码
- 模型预测代码
- 效果如何呢?
- 结语
什么是AutoEncoder
举个栗子:大家应该或多或少都会看片儿吧,
看啥片儿我就不过多得问了,哈哈,我是不是说多了。
从模拟信号源转化为数字信号源是需要一套编码的,这就是Encoder编译器,
那么我们通过机器或者软件将编译好的片儿读取出来观看,
这个过程就是解码,解码的英文是Decoder。
咱们今天说得这套深度学习AutoEncoder模型也是同理,先将我们得数据进行加噪音浓缩处理,然后优化后再进行预测。
这里是作者给我们的逻辑图,第二幅是我找的一个图片:
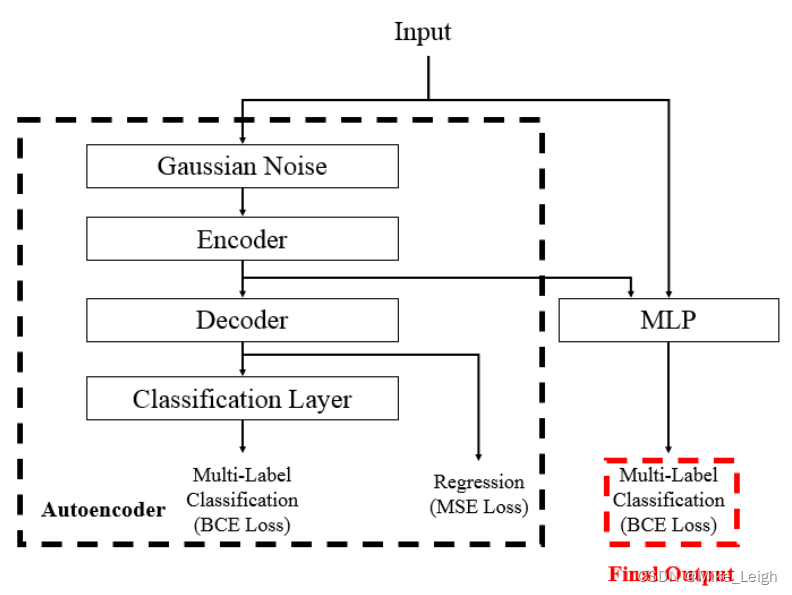
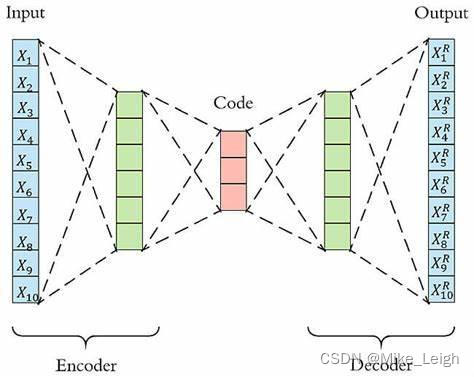
这里是 Kaggle的Jane Street Market Prediction 代码的原文地址。
上代码演示
库导入有点儿离谱哈,凑合看吧。
#import packages
import pandas as pd
import numpy as np
import datetime as dt
import tushare as ts
token=【放入你的tushare密钥,记得加双引号】
pro = ts.pro_api(token)
#to plot within notebook
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
#setting figure size
from matplotlib.pylab import rcParams
rcParams['figure.figsize'] = 20,10
rcParams['font.sans-serif'] = ['SimHei']
rcParams['axes.unicode_minus']=False
# keras
from keras.layers import
Input,
BatchNormalization,
GaussianNoise,
Dense,
Activation,
Dropout,
Concatenate
from keras.models import Model
from keras.optimizers import Adam
from keras.losses import MeanSquaredError, BinaryCrossentropy
from keras.metrics import MeanAbsoluteError, AUC
from keras.callbacks import ReduceLROnPlateau #, ModelCheckpoint, Callback, EarlyStopping
# sklearn
from sklearn.preprocessing import MinMaxScaler
### KNN 和 LSTM 都会用到归一法,先提前预设好函数
scaler = MinMaxScaler(feature_range=(0, 1))
封装的一个获取数据的函数
# 股票或指数行情数据下载
# 你可以把常看的股票编辑放在这里
def get_raw_data():
tickers = {
'沪深300':'399300.SZ',
'上证':'000001.SH',
'诺德':'600110.SH',
'仁智':'002629.SZ',
'双良':'600481.SH',
'明阳':'601615.SH',
'鞍重':'002667.SZ',
'道森':'603800.SH',
'梅花':'600873.SH',
'新安':'600596.SH',
'隆基':'601012.SH',
}
code = tickers['诺德']
if code.startswith('399'):
_df = pro.index_daily(ts_code=code,start_date='20121231',end_date='')
elif code == "000001.SH":
_df = pro.index_daily(ts_code=code,start_date='20121231',end_date='')
else:
_df = pro.daily(ts_code=code, start_date='20121231', end_date='')
return _df
清洗数据这一块我是从zhugby大佬这边获取的,有需要的朋友请自行去购买下载,不能做断人财路/侵犯他人权益的事儿。zhugby大佬的代码分享一共给大家展示了4种机器学习和深度学习的模型,我个人是觉得非常优秀的,让我收获颇丰。强烈建议大家去学习一下,而且也为我的数据准备打下了很夯实的基础。
MLP_AutoEncoder核心代码
def create_ae_mlp(num_columns,
num_labels,
hidden_units,
dropout_rates,
ls = 1e-2,
lr = 1e-3):
# 定义输入
inputs = Input(shape = (num_columns, ))
x0 = BatchNormalization()(inputs)
# 高斯加噪
noise_x0 = GaussianNoise(dropout_rates[0])(x0)
# 编码器
encoder = Dense(hidden_units[0])(noise_x0)
encoder = BatchNormalization()(encoder)
encoder = Activation('swish')(encoder)
# 解码器
decoder = Dropout(dropout_rates[1])(encoder)
decoder = Dense(num_columns, name = 'decoder')(decoder)
# Classification Layer
x_ae = Dense(hidden_units[1])(decoder)
x_ae = BatchNormalization()(x_ae)
x_ae = Activation('swish')(x_ae)
x_ae = Dropout(dropout_rates[2])(x_ae)
# Autoencoder的分类器
out_ae = Dense(num_labels,
activation='sigmoid',
name = 'ae_action')(x_ae)
# 拼接原始输入和编码器输入
x = Concatenate()([x0, encoder])
# MLP的网络层
x = BatchNormalization()(x)
x = Dropout(dropout_rates[3])(x)
for i in range(2, len(hidden_units)):
x = Dense(hidden_units[i])(x)
x = BatchNormalization()(x)
x = Activation('swish')(x)
x = Dropout(dropout_rates[i + 2])(x)
# MLP的分类器
out = Dense(num_labels, activation = 'sigmoid', name = 'action')(x)
# 定义输入输出
model = Model(inputs = inputs, outputs = [decoder, out_ae, out])
# 定义优化器,损失函数和Metrics
model.compile(optimizer = Adam(learning_rate = lr),
loss = {'decoder': MeanSquaredError(),
'ae_action': BinaryCrossentropy(label_smoothing = ls),
'action': BinaryCrossentropy(label_smoothing = ls),
},
metrics = {'decoder': MeanAbsoluteError(name = 'MAE'),
'ae_action': AUC(name = 'AUC'),
'action': AUC(name = 'AUC'),
},
)
return model
不得不说原作者“Mingjie Wang"的代码功力是真漂亮:工整,清晰,明确!具体的参数调整请大家自己学习修改,非常有趣!
模型预测代码
def prediction_AE():
#creating train and test sets
new_data = new_data_0.copy()
new_data.drop('trade_date', axis=1, inplace=True)
dataset = new_data.values
slice_ratio = 0.8
slicer = (len(new_data) * slice_ratio).__int__()
train_MLP = dataset[:slicer,:]
valid_MLP = dataset[slicer:,:]
#converting dataset into x_train and y_train 归一化
scaled_data = scaler.fit_transform(dataset)
x_train, y_train = [], []
for i in range(60,len(train_MLP)):
x_train.append(scaled_data[i-60:i,0])
y_train.append(scaled_data[i,0])
x_train, y_train = np.array(x_train), np.array(y_train)
x_train = np.reshape(x_train, (x_train.shape[0],x_train.shape[1],1))
### 参数可以自己去调整,如果你知道自己在干嘛,你大概是需要什么!
MLP_params = {
'num_columns': x_train.shape[1],
'num_labels': 1,
'hidden_units': [96, 96, 896, 448, 448, 256],
'dropout_rates': [0.03528, 0.038425, 0.4241, 0.1043, 0.4923, 0.32, 0.2717, 0.438],
'ls': 1e-2,
'lr': 1e-3,
}
model = create_ae_mlp(**MLP_params)
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.9, patience=5, min_lr=0.000001, verbose=1) # 磐创AI
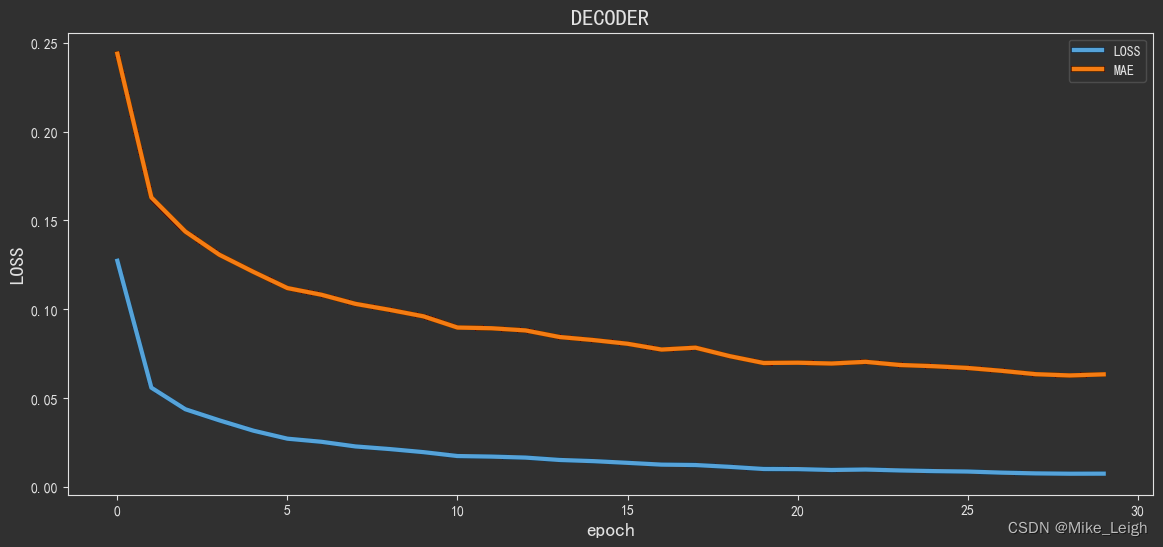
# 从图上分析来看,30次epoch似乎是一个比较理想的数值,看看batch_size多少更理想些吧。
_history = model.fit(x_train, y_train, epochs=30, batch_size=8, verbose=1, callbacks=[reduce_lr])
inputs = new_data[len(new_data) - len(valid_MLP) - 60:].values
inputs = inputs.reshape(-1,1)
inputs = scaler.transform(inputs)
X_test = []
for i in range(60,inputs.shape[0]):
X_test.append(inputs[i-60:i,0])
X_test = np.array(X_test)
X_test = np.reshape(X_test, (X_test.shape[0],X_test.shape[1],1))
closing_price = model.predict(X_test)
preds = scaler.inverse_transform(closing_price[1])
rms=np.sqrt(np.mean(np.power((valid_MLP-preds),2)))
return preds, rms, _history
history = prediction_AE()[2]
valid_0['Pre_MLP'] = prediction_AE()[0]
valid_0.tail()
效果如何呢?
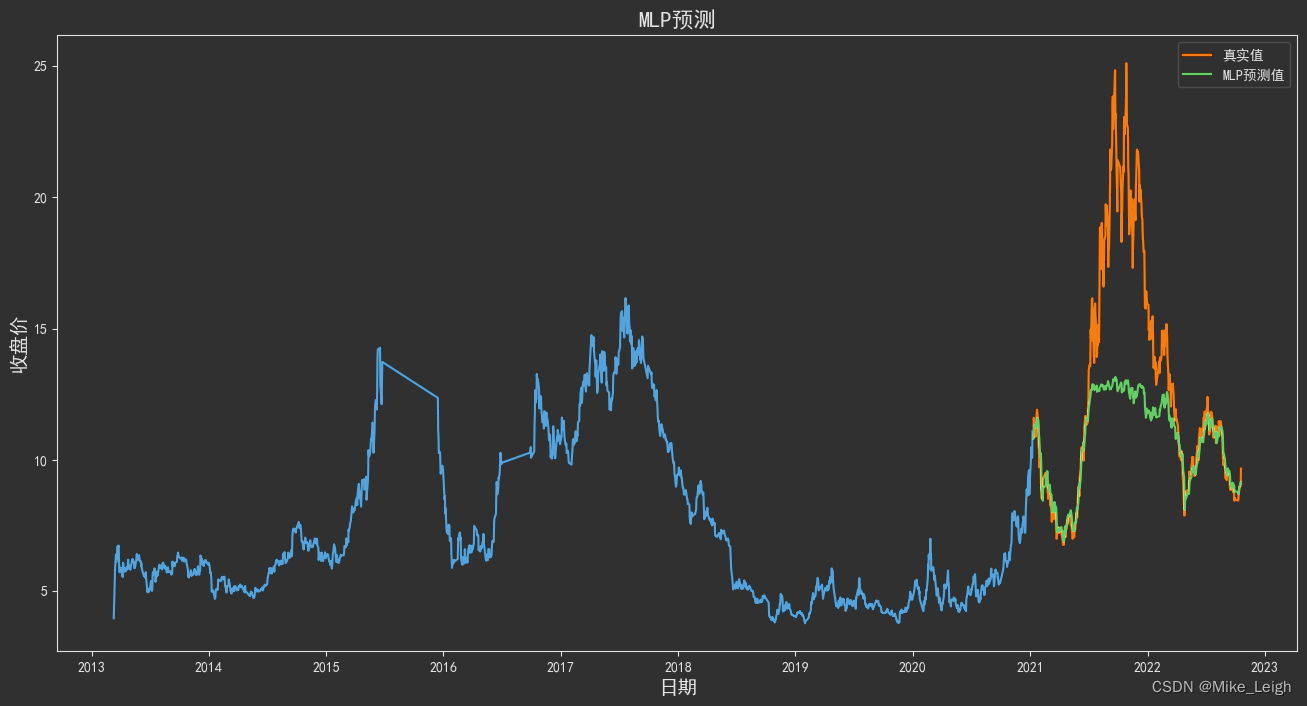
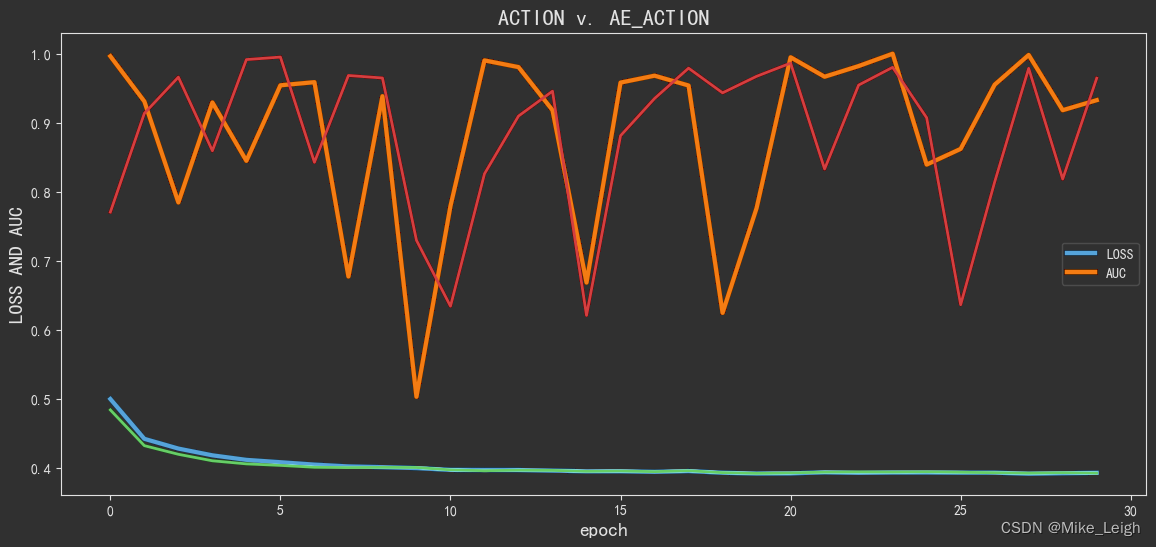
也许是我的80%训练预测比例有点儿劲儿使狠了,从图上看:在诺德股份2021年冲高的那段拟合程度并不是很好,其实也说明了一点就是这一波市场的情绪还是比较激进的,锂电板块亦是如此。从过去的数据计算方式来看并没有能够预判出来。
结语
- 机器学习和深度学习(ML & DL)是非常好的金融量化工具,预测只是一方面,我们还可以用模型去优化我们的因子,测试因子的有效程度,这都是可以实现的,就看大家怎么去用这个好工具。
- 千万不要迷信这玩意儿,ML和DL模型更多的是用在金融以外的时间排序数据处理上,在金融领域上运用的并不是很理想,毕竟金融市场并不是什么一两个模型就能预判和左右的(尤其像咱们大A这种市场,都懂的)。
- 最后推一波我导师的博客。他是咱天朝暨南大学非常优秀的金融学博士,在金融领域很有建树。他在我的量化学习的道路上给予了非常大的帮助,包括但不限于理论/代码/书籍等方方面面的指导学习。
最后
以上就是耍酷台灯最近收集整理的关于【手把手教你基于Keras的AutoEncoder模型拟合预测股票走势】什么是AutoEncoder结语的全部内容,更多相关【手把手教你基于Keras内容请搜索靠谱客的其他文章。

![[Python人工智能] 三十六.基于Transformer的商品评论情感分析 (2)keras构建多头自注意力(Transformer)模型](https://www.shuijiaxian.com/files_image/reation/bcimg16.png)






发表评论 取消回复