1.网页解析器:从网页中提取有价值的数据。
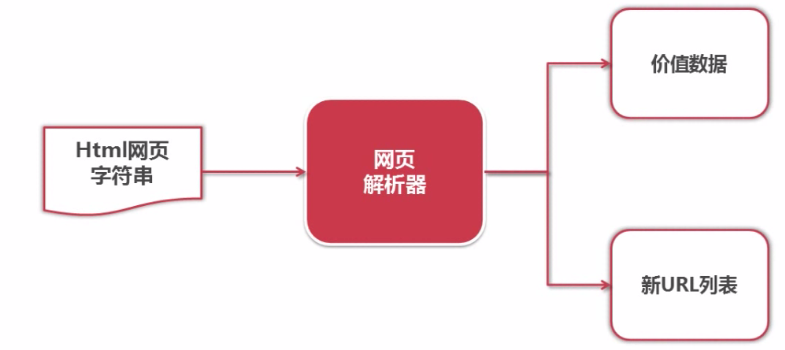
2.python网页解析的方式:
正则表达式、html.parser(python自带)、Beautiful Soup(第三方)、lxml(python自带).
Beautiful Soup可以使用html.parser或者lxml作为解析器
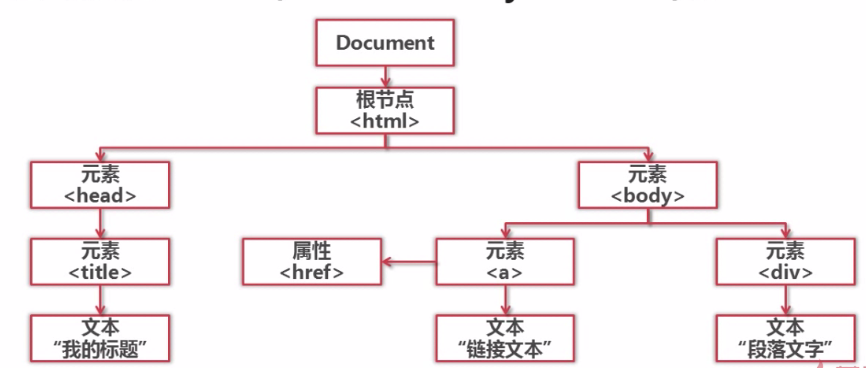
3.网页解析器就是结构化解析-DOM(Document Object Model)树
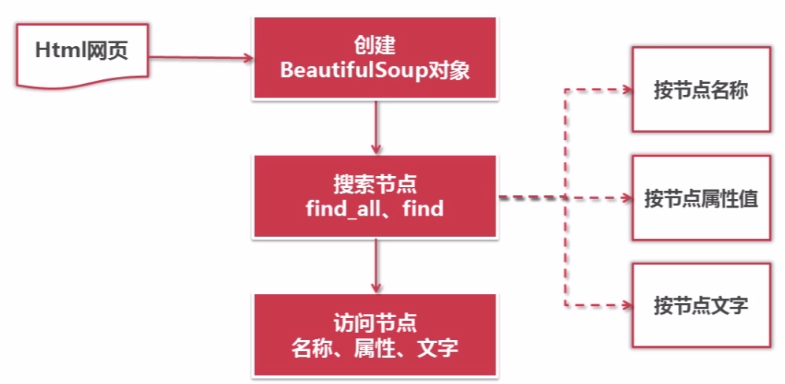
4.安装Beautiful Soup以及官网地址
pip install beautifulsoup4
http://www.crummy.com/software/BeautifulSoup/bs4/doc/
举例说明:
<a href='123.html' class='article_link'>Python </a> 节点名称:a 节点属性:href='123.html'和class='article_link' 节点内容:Python
使用BeautifulSoup解析网页,能够得到一个 BeautifulSoup 的对象,并能按照标准的缩进格式的结构输出:


#-*- coding: utf-8 -*- from bs4 import BeautifulSoup import re html_doc = """ <html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ soup = BeautifulSoup(html_doc) print(soup.prettify())
查看输出:
<html> <head> <title> The Dormouse's story </title> </head> <body> <p class="title"> <b> The Dormouse's story </b> </p> <p class="story"> Once upon a time there were three little sisters; and their names were <a class="sister" href="http://example.com/elsie" id="link1"> Elsie </a> , <a class="sister" href="http://example.com/lacie" id="link2"> Lacie </a> and <a class="sister" href="http://example.com/tillie" id="link3"> Tillie </a> ; and they lived at the bottom of a well. </p> <p class="story"> ... </p> </body> </html>
代码实现:
#-*- coding: utf-8 -*- from bs4 import BeautifulSoup import re html_doc = """ <html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ # 根据HTML网页字符串创建BeautifulSoup # HTML文档字符串 #HTML解析器 #HTML文档的编码 soup = BeautifulSoup(html_doc,'html.parser',from_encoding='utf-8') print ('-------获取所有的连接------------') links = soup.find_all('a') for link in links: print link.name, link['href'], link.get_text() print ('-------获取lacie的连接------------') link_nodes = soup.find_all('a', href='http://example.com/lacie') for link_node in link_nodes: print link_node.name, link_node['href'], link_node.get_text() print ('---------正则匹配----------') link_nodes = soup.find_all('a', href=re.compile(r"ill")) for link_node in link_nodes: print link_node.name, link_node['href'], link_node.get_text() print ('---------获取P段落文字----------') p_nodes = soup.find_all('p', class_="title") # class_是为避免与关键字冲突 for p_node in p_nodes: print p_node.name, p_node.get_text()
查看输出:
-------获取所有的连接------------ a http://example.com/elsie Elsie a http://example.com/lacie Lacie a http://example.com/tillie Tillie -------获取lacie的连接------------ a http://example.com/lacie Lacie ---------正则匹配---------- a http://example.com/tillie Tillie ---------获取P段落文字---------- p The Dormouse's story
转载于:https://www.cnblogs.com/XYJK1002/p/5315871.html
最后
以上就是缓慢书本最近收集整理的关于网页解析器的全部内容,更多相关网页解析器内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复