声明:本文中所将的spark内存模型是1.6+的版本,新的内存模型会在新的文章中讲到。
不久前我在StackOverflow上回答了一系列关于Apache Spark架构相关的问题。这似乎是由于网上缺乏好的Spark整体架构的文章。甚至是官网指导中也没有很多详细的介绍,当然也缺少好的架构图。“Learning Spark”这本书和官方资料中也一样没有。
本文我将尝试解决这个问题并在整体上提供Spark架构相关以及经常被提及的先关概念一些问题的一站式指导。这篇文章并不完全是针对Spark初学者的:文中不会提供Spark主要抽象编程的深入讲解(如RDD和DGA),但是需要大家具备这方面的知识。
下面我们先看看官方的架构图(http://spark.apache.org/docs/1.3.0/cluster-overview.html):
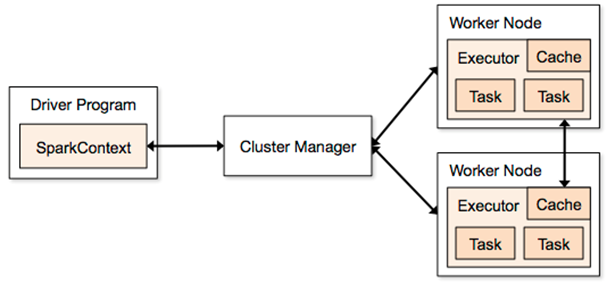
如上图所示,它一次性介绍了很多概念:executor、task、Cache、Worker Node等等。我以前开始学习Spark概念的时候,这张图几乎就是网上所能看到的唯一样关于Spark架构的图了,但是目前这种情况依然没有改变。我个人并不喜欢这张图,因为它并没有展示一些重要概念或者并没有将它们以最好的形式展示出来。
让我们从头开始。任何工作在我们集群上或者本地机器上的Spark进程都是一个JVM进程;而对于任何JVM进程我们都可以通过JVM参数-Xmx和-Xms来配置堆栈大小。那么这个进程如何使用堆栈以及为什么需要堆栈?这里有一张Spark在JVM堆中的内存分布图:
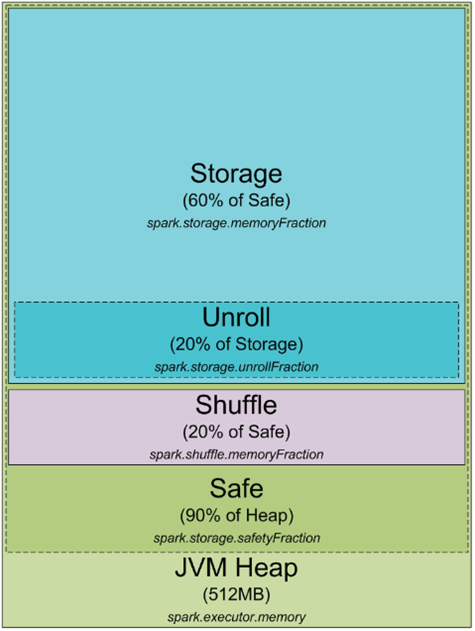
默认情况下,Spark的启动是JVM堆内存大小为512M。从安全方面考虑以及避免OOM错误,Spark只允许利用堆内存的90%,这比例通过Spark的spark.storage.safetyFraction参数控制。好吧,我们可能还听说过Spark作为一个内存池工具可以让我们将一些数据放入缓存中。如果我们已经读过之前关于Spark误区的文章(译注:Spark误区)就会明白Spark并不是真正的内存工具,它只是使用内存作为它的LRU缓存(http://en.wikipedia.org/wiki/Cache_algorithms)。其中一些缓存作为保留用来保存正在处理的数据,这部分区域通常占安全区域(safe heap,译注:JVM对内存的90%那部分内存)的60%,这个比例可以通过spark.storage.memoryFraction参数控制。因此,如果我们想知道可以将多少数据放入Spark缓存中,我们需要减去所有executor所占的对内存总和,再乘以safetyFraction和storage.memoryFraction参数;默认情况下为0.9 * 0.6 = 0.54,也就是说我们有54%的堆内存供Spark使用。
接着我们稍微多讲下shufle内存。它通过堆大小 * spark.shuffle.safetyFraction *spark.shuffle.memoryFraction计算公式得出。spark.shuffle.safetyFraction的默认值为0.8或者80%,spark.shuffle.memoryFraction的默认值为0.2或者20%;因此,我们可以使用的shuffle内存大小为0.8 * 0.2 = 0.16,也就是JVM堆内存的16%。但是Spark如何使用这个内存?我们可以在这里看到更多细节https://github.com/apache/spark/blob/branch-1.3/core/src/main/scala/org/apache/spark/shuffle/ShuffleMemoryManager.scala,Spark使用这些内存来执行shuffle所需要的任务;当shuffle执行完成后,有时我们需要对数据进行排序;当我们排序时需要将排过序的数据放入缓存中(但是请谨记,我们不能修改这些在LRU缓存中的数据,因为它们会在随后被重用)。所以需要一些内存来存放已排序的数据块。那么如果没有足够的内存来存放这些排过序的数据时会怎么样?有一个广泛使用的算法叫做“外部排序”(http://en.wikipedia.org/wiki/External_sorting)可以让我们将数据一块一块的排序,然后将最终结果合并在一起。
内存中最后一部分还没有被提及的是“unroll”内存。这块可以被unroll进程使用的内存大小通过spark.storage.unrollFraction *spark.storage.memoryFraction * spark.storage.safetyFraction计算公式得出,默认大小为0.2 * 0.6 * 0.9 = 0.108或者是10.8%。这块内存就是将数据展开到内存中时可以使用的内存。究竟为何我们需要unroll数据?因为Spark可以让我们将数据以序列化或非序列化的形式存储;以序列化的形式存储的数据是不能直接使用的,所以我们需要在用它之前将其展开,这就是这块内存的作用;这块内存是和Spark存储数据所用的内存共享的,所以当我们展开数据的时候可能会引起LRU缓存中存储的一些数据被清理。
非常好,现在我们了解了Spark进程是怎么样的以及如何利用JVM进程的堆内存。接着我们来看看集群模式:当我们打开一个Spark集群时,它看起来到底是什么样的?我比较喜欢YARN,所以我将讲讲它是怎么在YARN中运行的,但其实这在其他集群中也都是一样的:
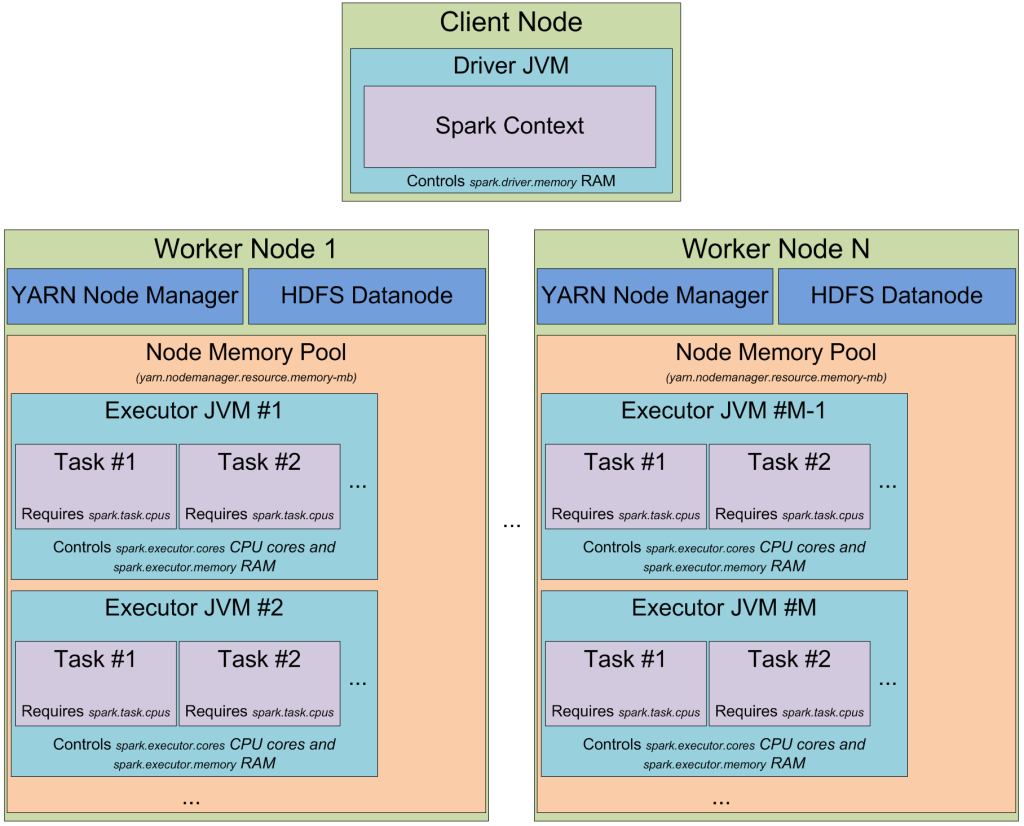
在YARN集群中,有一个YARN资源管理守护进程来管理集群中的资源(尤其是内存)、有一系列运行在集群节点上的YARN节点管理器以及控制节点上的资源利用。从YARN的角度上来看,每一个节点都代表一个我们可以控制的内存池。当我们从YARN资源管理器中请求一个资源时,它可以为我们调出executor容器;其中每个executor容器都是一个具有一定堆内存大小的JVM;而JVM得位置则由YARN资源管理器来决定我们不能直接控制选择哪个JVM----如果一个节点有64G的内存在YARN的控制之下(通过yarn-site.xml中yarn.nodemanager.resource.memory-mb参数配置),那么当我们发起10个执行请求每个4G时,如果有一个很大的集群,则这10个executor都可以很容易在单个YARN节点上执行。
当我们在YARN上构建Spark集群时,我们需要指定执行器的数量(-num-executors标记或spark.executor.instances参数)、每个executor的内存大小(-executor-memory标记或者spark.executor.memory参数)、每个executor所允许的核心数(-executor-cores标记或者spark.executor.cores参数)、为每个任务的执行分配的核心数(-spark.task.cpus参数)。同时我们还需要指定驱动程序所使用的内存大小(-driver-memory标记或者spark.driver.memory参数)。
当我们在Spark集群中发起执行命令时,我们的工作会被分为不同的阶段,每个阶段又会被拆分为task。每个task都会被单独调度,我们可以认为每个JVM都被用作执行器(executor)来作为task执行的任务池;每个executor又提供了spark.executor.cores 或spark.task.cpus参数来为每个task设置执行槽;并通过spark.executor.instances参数设置每个机器上所允许的executor数。这里有一个例子:有一个集群中有12个运行了YARN资源管理器的节点,每个节点64G内存、32核CPU(拥有超线程的16核物理CPU);这样的话每个节点可以启动两个executor,每个26G内存(因为要留一些内存给系统进程和YARN NM以及数据节点),每个executor分配12核CPU用来执行任务(因为要留一些内存给系统进程和YARN NM以及数据节点);因此这个集群可以处理12台机器 * 2个executor/机器 * 12个核心/executor * 1个核心/task = 288个任务槽,也就是说这个Spark集群可以最多并行执行288个任务并占满集群中的所有资源。而集群中可以被用来缓存数据的内存大小为 0.9 spark.storage.safetyFraction * 0.6 spark.storage.memoryFraction* 12台机器 * 2executor/每台机器 * 26G内存/executor = 336.96 GB。虽然不是很多,但大部分情况下就够用了。
目前一切顺利,我们Spark如何利用内存以及集群中执行槽是什么。但我们可能还注意到,我并没停留在有关细节上来解释“task”到底是什么。这是下一篇文章里要讲到的,但是基本上task是Spark进行作业的最小执行单位,并且作为executor JVM中的一个线程来执行;这就是Spark下job启动延迟低的秘密----在JVM内部fork一个额外的线程远比在Hadoop启动MapReduce作业时重新启动一个完整的虚拟机要快的多。
下面我们来关注Spark的另一个抽象“分区(partition)”。我们在Spark中使用的所有数据都会被拆分为分区。什么是分区?它是由什么决定的?分区的大小完全是由我们所使用的数据源大小决定的。在Spark大多数读取数据的方法中我们都可以指定想要在RDD中生成的分区数。当我们从HDFS中读取一个文件时,可以使用Hadoop的InputFormat来实现,默认情况下被InputFormat拆分出来的输入块在RDD中都会被封装为分区。对于HDFS中的大多数文件来说每个输入分片都会生成对应的块(block)存储在HDFS系统中,每个块大约在64M到128M。这里用大约是因为HDFS是使用字节来准确切分块,但处理的时候是根据记录来切分的;对于文本文件来说是通过换行符切换的,而对于序列文件又是根据块切分的等等。这里唯一个列外就是压缩文件----如果我们将整个文本文件压缩,那么它就不能按记录来切分,那么整个文件就会作为一个单一的切分从而导致Spark只会为其生成单个分区,这种情况下我们只能手动来切分。
接下来事情就变得很简单了----将每个分区中的数据通过离数据位置(这里指Hadoop中块的位置或者Spark中缓存的分区的位置)最近的任务槽中通过task来处理。
这篇文章中已经讲了很多信息了。下篇文章将讲讲Spark如何将执行进程拆分为不同阶段并将每阶段放入task中执行?Spark如何在集群中shuffle数据?以及其他一些有用的东西。
1. 本文由程序员学架构翻译
2.原文链接:http://0x0fff.com/spark-architecture/
2. 转载请务必注明本文出自:程序员学架构(微信号:archleaner)
3. 更多文章请扫码:









发表评论 取消回复