一:单表查询
SELECT查询语句语法结构:
SELECT [DISTINCT] 字段名1[,字段名2,...] FROM 表名WHERE 过滤条件
GROUP BY 分组依据
HAVING 过滤条件
ORDER BY 排序依据
LIMIT 数字
各关键字执行顺序:
FROM-->WHERE-->GROUP BY-->HAVING-->ORDER BY-->SELECT-[DISTINCT]-->LIMIT
1,DISTINCT
DISTINCT 应用于所有列而不仅是其后面的第一个列
如:distinct vend_id 取出所有不同的vend_id;distinct vend_id,prod_name 取出不同的vend_id和prod_name的组合,只有当vend_id和prod_name都相同时,才会去掉
2,字段名
字段:包括表中的列,计算字段,拼接字段
计算字段:字段间进行运算(+、-、*、/)产生的,子查询得到的、使用数据处理函数或聚集函数得到的新字段
拼接字段:使用concat()函数进行拼接得到的新字段
用 AS 给计算字段和拼接字段取别名:计算或拼接成的新字段只有值没有名字,无法被应用程序引用,可以取个别名解决
3,WHERE
| 操作符 | 说明 | 操作符 | 说明 |
| = | 等于 | IS NULL | 为空值 |
| <> | 不等于 | IS NOT NULL | 不为空值 |
| != | 不等于 | AND | 逻辑 全部条件匹配成功,才算匹配成功 |
| < | 小于 | OR | 逻辑或 有一个条件匹配成功,就算匹配成功 |
| <= | 小于等于 | NOT | 逻辑非,条件取反 |
| > | 大于 | IN | IN(a,b,c) 功能与OR相当 指定条件范围,逐个进行匹配 |
| >= | 大于等于 | LIKE | 用于通配符搜索 (% 、_) |
| BETWEEN...AND | 在两个值之间 | REGEXP | 正则表达式 |
like操作符:用于通配符搜索
通配符:wildcard 用来匹配值的一部分的特殊字符
百分号 % 匹配任意个字符,包括0个字符
下划线 _ 匹配单个字符,不能多也不能少
使用通配符的技巧:
1,不要过分使用通配符,如果其他操作符能达到相同的目的,应该使用其他操作符
2,尽量不要在搜索模式的开始处使用通配符,把通配符置于搜索模式的开始处搜索起来是最慢的
3,仔细注意通配符的位置
正则表达式:REGEXP '匹配字符'
SELECT * FROM t1
WHERE name REGEXP 'ock';
4,GROUP BY & HAVING
GROUP BY 子句可以包含任意数目的列
大多数SQL实现不允许GROUP BY列带有长度可变的数据类型(如文本)
除聚集计算语句外,select语句中的每个列都必须在GROUP BY 子句中给出
GROUP BY 子句必须出现在WHERE子句之后,ORDER BY子句之前。
HAVING 过滤分组; WHERE 过滤行; 它俩的句法是相同的
WHRER用于分组前过滤; HAVING一般用于分组后过滤
5,ORDER BY
排序,默认升序 ASC
降序,需指定 DESC 关键字;想在多个列上进行降序排序,必须对每个列指定DESC关键字
--方式一:
SELECT prod_id,prod_price,prod_name
FROM Products
ORDER BY prod_price,prod_name;
--方式二:按相对列位置进行排序,该相对位置必须在select清单中
SELECT prod_id,prod_price,prod_name
FROM Products
ORDER BY 2,3 [DESC];6,LIMIT
LIMIT 5; 限制返回5行
LIMIT 5,5; 指示从行5(即第6行)开始取5行(第一行为行0)
LIMIT 4 OFFSET 3; 从行3开始取4行 同 LIMIT 3,4;
二:数据处理函数与聚集函数
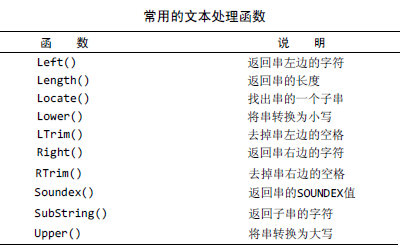
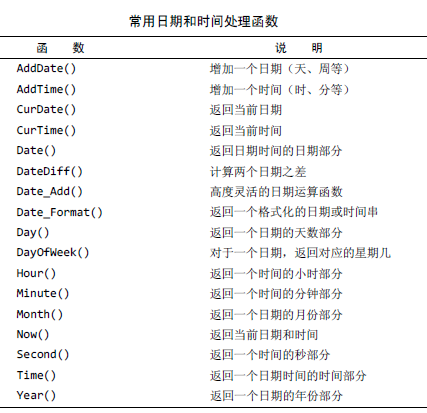
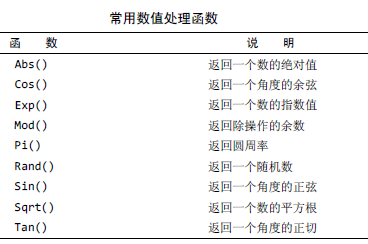
1,数据处理函数
2,聚集函数
聚集函数:aggregate function 运行在行组上,计算和返回单个值的函数
| 函数 | 说明 |
| AVG() | 返回某列的平均值 |
| COUNT() | 返回某列的行数 |
| MAX() | 返回某列的最大值 |
| MIN() | 返回某列的最小值 |
| SUM() | 返回某列值之和 |
COUNT(*) 对表中的行的数目进行计数,包括NULL
COUNT(column) 对特定列中具有值的行进行计数,忽略NULL
三:子查询
子查询:subquery 嵌套在其他查询中的查询
可用于where子句的IN操作符中和创建计算字段
1,用于where子句的IN操作符中
SELECT cust_id FROM orders
WHERE order_num IN (SELECT order_num
FROM orderitems
WHERE prod_id = 'TNT2');2,用于创建计算字段
SELECT cust_name,cust_state,(SELECT COUNT(*)
FROM orders
WHERE orders.cust_id = customers.cust_id) AS orders
FROM customers
ORDER BY cust_name;在SELECT语句中,子查询总是从内向外处理;对于能嵌套的子查询的数目没有限制,不过在实际使用时由于性能的限制,不能嵌套太多的子查询
四:表的联结、多表查询与组合查询
联结是利用SQL的SELECT能执行的最重要的操作!!!
在联结两个表时,实际上做的是将第一个表中的每一行与第二个表中的每一行配对;WHERE子句作为过滤条件,所有结果只包含那些匹配给定条件的行。
联结表不是物理实体,即它在实际的数据库表中不存在,只存在于查询的执行当中
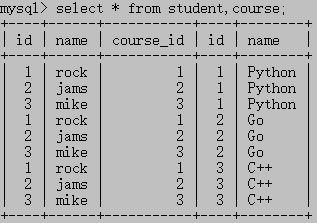
笛卡尔积:由没有联结条件的表关系返回的结果为笛卡尔积。检索出的行的数目将是第一个表中的行数乘以第二个表中的行数。(样例见下图)
1,内部联结:也叫等值联结,它基于两个表之间的相等测试
1.1 两种联结形式:
--形式一:
SELECT vend_name,prod_name,prod_price
FROM vendors,products
WHERE vendors.vend_id = products.vend_id;
--形式二:使用INNER JOIN关键字联结表,推荐使用这种方式
SELECT vend_name,prod_name,prod_price
FROM vendors INNER JOIN products
--关键字ON给出联结条件
ON vendors.vend_id = products.vend_id; 1.2 自联结:两张相同的表相联结,这时为了避免表名的二义性,需要给表取别名
可以给表起别名;表别名只在查询执行中使用,与列别名不一样,表别名不返回到客户机
SELECT c1.cust_id,c1.cust_name,c1.cust_contact
FROM customers AS c1,customers AS c2
WHERE c1.cust_name = c2.cust_name AND c2.cust_contact = 'Jim Jones';2,外部联结
联结包含了那些在相关表中没有关联行的行,这种类型的联结称为外部联结;外部联结分两种类型:左外部联结与右外部联结
左外部联结:即包含了左表中那些与右表没有关联关系的行
--左外部联结:使用关键字 LEFT OUTER JOIN
SELECT customers.cust_id,orders.order_num
FROM customers LEFT OUTER JOIN orders
ON customers.cust_id = orders.cust_id;
--右外部联结:RIGHT OUTER JOIN3,组合查询
组合查询:使用UNION操作符来组合数条SQL查询,并将它们的结果组合成单个结果集返回
UNION规则:
(1) UNION 中的每个查询必须包含相同的列、表达式或聚集函数(次序可以不同)
(2) UNION 从查询结果集中自动去除了重复的行;如果想返回所有匹配行,可使用UNION ALL
(3) 只能使用一条ORDER BY 子句来排序,在最后一条SELECT语句之后使用。
SELECT customers.cust_id,orders.order_num
FROM customers LEFT OUTER JOIN orders
ON customers.cust_id = orders.cust_id
UNION
SELECT customers.cust_id,orders.order_num
FROM customers RIGHT OUTER JOIN orders
ON customers.cust_id = orders.cust_id;五:数据的插入、更新、删除
1,数据的插入 INSERT INTO
--方式一:高度依赖于表中列的定义次序,各个列必须以它们在表定义中出现的次序填充
INSERT INTO customers
VALUES
(value1,value2,...);
--方式二:在表名后的括号里明确地给出列名
(推荐使用这种写法!)
INSERT INTO customers(cust_id,cust_name,...)
VALUES
(value1,value2,...);--同时插入多行数据
INSERT INTO customers(cust_id,cust_name,...)
VALUES
(value1_1,value1_2,...),
(value2_1,value2_2,...);--插入检索出的数据:INSERT SELECT
INSERT INTO customers(cust_id,cust_name,...)
--不一定要求列名匹配,填充数据使用的是列的位置
SELECT cust_id,cust_name,...
FROM custnew;
--使用INSERT SELECT从custnew中将所有数据导入customers;表custnew有多少行就插入多少行
--MySQL中复制表:
CREATE TABLE newt1 as
SELECT * FROM t1;2,数据的更新 UPDATE
语法:
UPDATE 表名 SET 列名1 = 值1,
列名2 = 值2
WHERE 过滤条件; (不要忘了使用WHERE子句,不然就会更新表中的所有行)
--更新一列
UPDATE customers
SET cust_email = 'elmer@fudd.com'
WHERE cust_id = 10005;
--更新多列
UPDATE customers
SET cust_name = 'Fudds',
cust_email = 'elmer@fudd.com'
WHERE cust_id = 10005;
--为了删除某个列的值,可设置它为NULL(假定允许NULL值)
UPDATE customers
SET cust_email = NULL
WHERE cust_id = 10005;3,数据的删除 DELETE
语法:
DELETE FROM 表名 WHERE 过滤条件;
DELETE FROM customers
WHERE cust_id = 10006;最后
以上就是落后蜜粉最近收集整理的关于MySQL基础(二):数据的查询、插入、更新与删除的全部内容,更多相关MySQL基础(二):数据内容请搜索靠谱客的其他文章。








发表评论 取消回复