作者:北溟小鱼hk
链接:https://www.zhihu.com/question/47686258/answer/107209140
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
一、引子
这是关于一把玄铁重剑,一本经书,和一套轻功步法的故事。
让我们先从普通程序猿们的日常工作内容说起,
一般来说,程序猿们大部分时间关注的可能不是研发某个具体算法,这是算法工程师/数学家们擅长的东东。程序猿的工作主要是通过调用编程环境中现成的工具函数或接口来实现具体的应用功能,将各个底层接口或算法模块用代码有秩序地拼装联接起来,实现酷炫好用的产品功能,如同组装一件乐高玩具一样。

<img src="https://pic1.zhimg.com/50/f18f94860ee3886b39c618e7df84ee20_hd.jpg" data-rawwidth="450" data-rawheight="405" class="origin_image zh-lightbox-thumb" width="450" data-original="https://pic1.zhimg.com/f18f94860ee3886b39c618e7df84ee20_r.jpg">序猿的很多工作往往不是围绕某个高大上的具体算法(“我们不生产算法,我们只是算法的搬运工”),而是像代码界的城管、或者清洁工一样,关注怎样组织文件结构,怎样理清编程思路,怎样命名变量,怎样降低代码耦合度,怎样提高代码的复用性和一致性,提高代码的可读性和健壮性,怎样优化分工协作、减少沟通成本等等。不管是OOP、FP等编程思想,还是MVC等设计模式、或是各种编程语言下的应用开发框架,很多都是为了帮助程序猿完成这些脏活、累活儿。
具体到web应用开发而言,react以及他的好基友redux都是程序猿们出色的好帮手,因此让众多前端开发者一见倾心,俺也不例外。
<img src="https://pic3.zhimg.com/50/fc7c13b8ae407494d6c9d99d1bae4a4f_hd.jpg" data-rawwidth="450" data-rawheight="500" class="origin_image zh-lightbox-thumb" width="450" data-original="https://pic3.zhimg.com/fc7c13b8ae407494d6c9d99d1bae4a4f_r.jpg">
和一般前端框架相比,react有两个显著特点:
- react的性能很好,可以满足实际生产环境下的绝大部分性能需求。
- react从使用的角度来说非常轻量级,因此很容易和其他顺手常用的工具搭配使用,而没有任何违和感。(如果你发现react可以和backbone、angular等框架很轻松地放到一起使用,请保持高冷,无需惊讶~)
事实上,react和redux从使用的角度来说,是如此轻量舒适,以至于我们可以不把它们当作“开发框架”,而是一种编程模式,或是编程的“脚手架”,用起来非常“小清新”。这一点和angularjs这类“重口味”框架有很大区别(我不推荐使用angularjs,当然每个人口味不同,最好自己上手体验再做取舍)。其实本人接触react比较晚,但一试用就有种血槽猛涨的感觉,强烈建议还没上手react的前端程序猿们试用一下!
<img src="https://pic3.zhimg.com/50/bdf28c38b74ebbd9a747ad2493feac81_hd.jpg" data-rawwidth="450" data-rawheight="225" class="origin_image zh-lightbox-thumb" width="450" data-original="https://pic3.zhimg.com/bdf28c38b74ebbd9a747ad2493feac81_r.jpg">
其实,关于react的具体开发实践,知乎上已有很多优秀的文章,例如[ react 有哪些最佳实践? - 前端开发],不再赘述。这里只想分享一下我在学习react过程中的一点体会, 捋一下react以及flux背后思想的来龙去脉,从而能够让大家更加自然地接受react开发模式。
二、正文
我们首先举两个栗子:
(一)江湖旧事1
在web1.0的纯网页时代,前端开发其实是比较happy的,这是因为网页上几乎不需要什么交互,前端开发者基本上只需要根据后台提供的数据将网页内容排版呈现出来即可。用户的交互行为一般仅限于填写一个表单,然后把数据提交到服务器,提交成功后,直接刷新整个页面。
我们以常见的todoList为例,当需要添加一条todo任务的时候,用web1.0的思路,典型的流程是这样的:
<img src="https://pic3.zhimg.com/50/1a187d2cdbf86dc563ac4cd4941b39d7_hd.jpg" data-rawwidth="690" data-rawheight="648" class="origin_image zh-lightbox-thumb" width="690" data-original="https://pic3.zhimg.com/1a187d2cdbf86dc563ac4cd4941b39d7_r.jpg">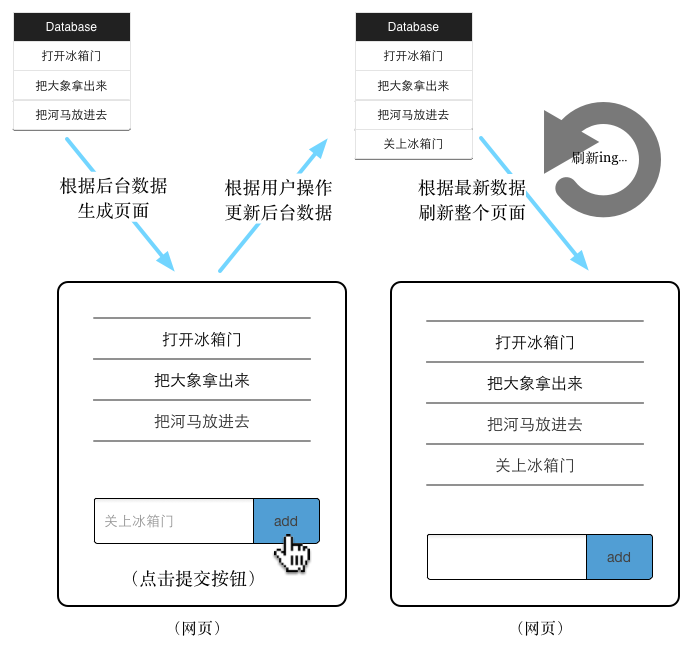
通过这张图,我们再仔细揣摩一下为什么web1.0条件下前端开发是比较轻松的:这是因为所有和数据(大体上等价于state)相关的操作,都已经由服务器完成了,前端开发只需要根据state来决定view(页面)。也就是说,这个时候前端开发者的思维是一个从state到view的 “单向流”。(当state变化时,只要简单粗暴地整体刷新页面就OK了。)
然而,当页面交互变得丰富细腻、内容变得庞大复杂之后,这种基于服务器维护state,然后页面整体刷新的web1.0方式存在两个严重的缺陷:
- 反复刷新页面,尤其是内容复杂的页面,对浏览器的渲染性能消耗很大。一个很小的局部交互动作,就会引起整个页面的刷新,显然对于浏览器性能是非常大的浪费。同时,由于页面刷新,导致不必要的等待和“闪屏”,这些对于有节操的产品汪或者程序猿都是难以容忍的。
- 由交互产生的很多细腻的前端数据,其实也很难交给后台处理,因为这是我们无处安放的临时状态。例如一个菜单是收起还是打开,一个面板是隐藏还是弹出,如果前端不去记录这些view对应的状态,那么后台就要记录这些状态,否则页面刷新后,这些状态信息就会丢失。即使我们不在乎页面和服务器之间通信的时间浪费,我们也很难想象有什么理由要在服务器上记录这些只和view相关的临时状态,毕竟这些状态不对应任何后台业务数据。
正是由于这两个显著缺陷,才导致ajax技术的出现。自从有了ajax通信和局部页面更新的机制以后,妈妈再也不用担心我们页面整体刷新导致的用户体验问题了!于是前端开发大踏步地进入web2.0时代,大量交互细腻,内容丰富的SPA(single page application)也应运而生。但与此同时,前端开发的工作也从此变得苦逼起来。。。因为现在根据后台数据排版生成页面,现在只是最基本的工作。当用户进行某种交互操作引起页面状态变化之后,为了避免页面整体刷新,我们需要小心翼翼地将各个相关的页面局部元素拣选出来,做适当修改,再放回原处,动作一般不会太优雅。(脑补一下《加勒比海盗》中,把眼球拿出来擦一擦又塞回去的那个海盗。。)
当页面逻辑简单,交互行为较少时,这种局部修改也许很容易搞定;然而,一旦页面中各个元素的关系变得复杂,各种交互操作耦合起来之后,这种局部修改就会消耗大量脑细胞,并且我们需要同时对用户操作和服务器反馈做出响应,并确保页面状态和服务器状态的一致性,于是我们就很容易变得左支右绌、顾此失彼。相信不少前端工程师都有过类似的体验。
总之,从上面的例子我们得出两个经验:- 根据确定的交互状态(state),一股脑儿决定页面的呈现(view),这种“单向流”的开发状态对程序员来说是思维清晰、比较轻松的;一旦我们需要不断手动更新view,并且改变state和view的代码还纠缠在一起,我们的内心往往是崩溃的。
- 为了让前端开发不感到崩溃,就把所有state交给后台来维护,简单粗暴地通过重新加载页面来实现view的更新是不靠谱的(后台的内心独白:我招谁惹谁了啊!!),我们需要找到新的方法,来实现view的自动更新。
(二)江湖旧事2
其实,通过改变state,来让view自动更新,这个想法一点也不新鲜。css中各种基于className的样式声明,就是典型代表(改变div的className相当于改变它对应的state, 尤其是css3引入transition和animation之后,这种用css来偷懒的做法越来越常见),我们再举个例子,比如说我们要做一个菜单:
<img src="https://pic4.zhimg.com/50/c783e25f64e5474356a31830de6f292a_hd.jpg" data-rawwidth="330" data-rawheight="420" class="content_image" width="330">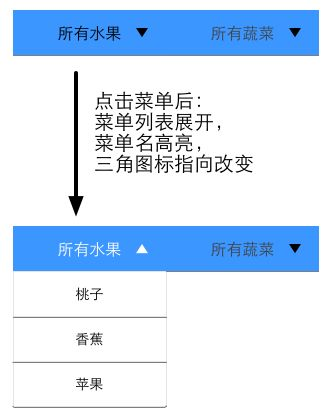
生手碰到这个问题,也许会这样做:
当用户点击按钮的时候,先改变菜单名的色值,再改变按钮的背景图(由向下箭头,改成向上箭头),最后改变下拉列表的显示状态,有必要的话,还需要做个列表下拉的动画。当用户再次点击按钮的时候,把所有操作倒着来一遍,恢复菜单收起的状态,ok?
然而,对于好逸恶劳的前端老司机们来说,一般会这样做:对整个菜单的容器定义两个className,比如一个是"menu-close",一个是“menu-open”。在menu-close的状态下,菜单名的色值为黑色,按钮背景图为向下箭头,下拉列表是隐藏状态;在menu-open的状态下,菜单名的色值为白色,按钮背景图是向上箭头,下拉列表是显示状态;需要的话,再用css3 transition给下拉列表加个动画过渡效果。当用户点击按钮的时候,只需要改变整个菜单容器的className即可。所有的交互效果都用css“平铺”的方式声明出来,这样做不仅节省了多个手工步骤,而且更改整个容器的className是个单点操作,因此也方便维护和修改。这也是bootstrap框架里惯用的一招,非常好使。
通过这个例子,我们看到“改变state,让view自动更新”的开发思想在纯粹的前端领域也由来已久。它可以让开发者思维更加清晰,代码更好维护,幸福指数飙升!
然而用css className来实现state功能,其应用范围是非常有限的。原因很简单,css只能改变DOM元素的样式,却不能改变网页中DOM tree本身的结构(例如,例子1中todoList的增删操作就涉及li元素的append或者remove),更没有办法直接和具体的业务数据相关联。于是,knockoutjs、angularjs等前端框架纷纷登场,这些框架可以系统地实现view 和 state(一般在这些框架里称为ViewModel)的相互绑定,从而使代码更有秩序,帮前端开发省去不少麻烦。即便这些框架约定很多,有些束手束脚的感觉,但如果没有另一件大杀器重出江湖,程序猿们也可以将就过了,奈何既生瑜,何生亮。。这是后话。
(三)重剑无锋
好,抛开knockout、angular这些框架,现在如果让我们自己设计一套根据states(包括后台业务数据和前端临时数据,例如表单input值、某个面板的显隐状态等等)自动更新页面的机制,我们该怎么办呢?
对于每一种特定场景,我们也许有很多种代码方式来根据state自动更新页面的某个局部view。但是,如果页面交互足够复杂,以至于我们需要在页面的很多地方不断修修补补,并且这些“补丁”对应的state可能还彼此重叠,或者我们希望能一劳永逸地解决所有view自动更新的问题,并且还不引入更多繁琐的约定,似乎除了刷新整个页面没有更好的办法(这有点像逐帧动画的原理,我们一般不会真的根据物体运动轨迹一点一点修改画面,形成运动效果,而是直接一帧一帧*重绘整个画布,形成动画效果!)
但前面我们说过,像web1.0的做法一样,重绘整个页面对浏览器的性能损耗是很严重的,用户体验也很糟糕。。怎么办?怎么办?!我脑补着facebook的某个程序员在一个月黑风高的晚上坐在公司电脑前,抿了一口浓浓的咖啡,突然灵光一现,伴着屏幕上忽明忽暗的幽幽蓝光,在文本编辑器里写下这么一行文字:可不可以把浏览器里的DOM tree克隆一份完整的镜像到内存,也就是所谓的“virtual DOM”,当页面的state发生变化以后,根据最新的state重新生成一份virtual DOM(相当于在内存里“刷新”整个页面),将它和之前的virtual DOM做比对(diff),然后在浏览器里只渲染被改变的那部分内容,这样浏览器的性能损耗和用户体验不就都不成问题了吗?而我们知道在绝大部分网页应用中js引擎的性能和内存完全没有被充分利用,我们正好可以火力全开,利用js的这部分性能红利,实现内存中virtual DOM的diff工作,完美!
于是React横空出世。
话虽简单,不过单单是在内存中模拟整个DOM tree,这个工作想想就觉得头大,所以不得不佩服facebook的那些前端大神们!表面上react花了很大气力却只做了view层跟virtual DOM相关的工作,但所谓“大巧不工、重剑无锋”,实际上facebook祭出的这件大杀器让“改变state,view自动更新”这种直观朴素的想法有了坚实的基础,“state-view”的开发模式从此一马平川!正因为如此,伴随着react的崛起,类似于redux这些专注于管理state的轻量级框架也变得炙手可热起来。
有了React这把重剑,前端开发们第一次感觉到似乎又回到了web1.0美好的田园时代!而react非常具有表达力的jsx语法和完善的模块化结构,又让我们觉得像生活在酷炫的未来时代!这是我们的下一话题。( 此处应有《Back to The Future》的电影配乐)
(四)庖丁解牛(view的模块化)
view的组件化和模块化非常有利于分工协作、代码的积累复用以及单元测试。这对于提高团队开发的效率无疑具有非常重要的意义,这也是react广受青睐的重要原因之一,这一点就不再赘述。这里想换个角度,聊一下react的模块化机制,对于开发者个体来说有什么好处?
前面我们提到,由于React的“state-view”模式可以让开发者的大脑得到一种“单向流”的舒适体验。那为什么单向流的思维状态更加舒适呢?
这是因为在**单向流**状态下,要解决的问题如同一个函数映射,已知什么(比如state)是固定不变的,要得到什么(比如view)是定义明确,而人的思维非常习惯于这种定义明确的、没有“分叉”和“环路”的函数式问题。
也就是说,让人抓狂崩溃的往往是那些包含“分叉”或“环路”的非函数式问题,这个时候大脑不得不思前想后,谋划全局,进入一种“多线程”工作状态,而“单线程”作业对于大脑来说一般才是更加轻松高效。所谓“单线程”,就是每时每刻只专注于一个问题 —— one at a time! React的"state-view"模式帮助我们在开发view的时候,只需要专注于view(即关注页面布局样式。view上的交互行为怎样对state产生反馈作用,我们稍后再来讨论),而React简便的“模块化”机制(即只需要写很少量的boilerplate代码,就可以定义或引用一个新模块),让我们可以根据需要,将整个页面的布局样式工作进一步拆分成各个小模块(view component),或者将各个小模块组装成大模块,从而进一步深入贯彻“one at a time”的原则,给大脑减负,因此这时程序猿很容易进入一种舒适高效的状态(心理学中甚至有个“心流”的概念用来描述这种状态)。决定页面呈现的state可以通过模块属性(props)从父模块传递到子模块。这种"树状"分流机制,有点像植物将养分(state)从根部不断运输到细枝末叶的过程,如图所示:
<img src="https://pic2.zhimg.com/50/a6fa072f1c55533464fe616cbb06c67f_hd.jpg" data-rawwidth="300" data-rawheight="195" class="content_image" width="300">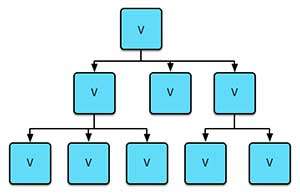
简便的“模块化”机制客观上鼓励了迅速上手、边走边看的敏捷开发方式。也就是说,前端开发者在做页面布局样式工作的时候,可以根据自己的经验或视角,随意挑选一块比较“容易上手”的区域作为一个模块的出发点,迅速开工,而无需事先瞻前顾后、谋划全局。当挑选的区域中,有某一块内容需要仔细打磨、细化功能的时候,我们可以迅速将这块内容拆分为一个子模块,然后专注于这个子模块的开发,当若干模块开发完毕后,我们也可以将各个模块组装成大模块,最终形成整个页面。这种开发体验,有点像拼乐高或者创作雕塑:比如说我们要做一个人物雕塑群,我们可以先从单个人物开始。当我们在做单个人物的时候,我们可以先粗线条地捏出整体形态,在需要的时候,我们可以换用更称手的工具来雕琢细节,比如人物的五官表情或者衣服的褶皱,如果一上来我们需要谋划雕塑群中每一个人物的每一个表情细节才能开工,显然这个任务是很难完成的。
好,到目前为止,我们看到react已经几乎完美地帮我们理顺了从state到view的开发流程。但是前面的讨论过程中,似乎还有一朵“小乌云”没清理,那就是怎样实现从view到state的反馈流程。也就是说,用户在view上的交互行为(比如点击提交按钮等)应当引起state改变的时候,这个流程该怎么处理?这是我们要聊的下一话题。
(五)易筋经(flux思想)
a. 几点说明
如果要用一门武林绝学比喻flux思想,我首先想到的是易筋经。此功虽无固定招式,但意会之后,就会有种打通全身经络、气血通畅的感觉,并且可以将前端开发中的其他武功串联起来,运用自如 : )
关于flux首先有几点需要说明:- flux与react没有直接的关系,二者是完全独立的概念。
- flux不是一个js库,而是一种前端代码的组织思想,比如说redux库可以认为是一种flux思想的实现。
- flux的核心思想和代码实现虽然很简单(基本上就是一个event dispatcher而已),但在“state-view”开发模式中,却是非常重要的一个环节,所以facebook给这个思想特意起了这么一个“高大上”的名字。
b. MVC模式
在讲flux之前,我们不得不首先提一下大名鼎鼎的MVC开发模式。
所谓MVC开发模式, 主要讲的是在开发交互应用时,怎样将不同功能的代码拆分到不同文件或区块,以便降低代码的耦合度,提高代码的可读性和健壮性。简单理解就是:要将 Model-View-Controller 这三部分代码拆分到不同文件。
对于服务器端开发,Model指的是和处理业务数据相关的代码,例如通过ORM实现数据库的增删改查等操作;View指的是和页面组装相关的代码,主要是和各种模版引擎(例如Java Velocity、PHP Smarty、nodejs ejs等等)相关的代码部分;Controller指的是和用户交互行为相关的代码,具体到网站后台应用,指的就是对各种http请求的handler,也就是根据不同**url路径和http请求的参数**,将数据和模版绑定到一起,最终形成页面呈现给用户。
对于网站前端开发,在web1.0时代,由于js基本上只是个跑龙套的小角色,所以不需要什么设计模式;但是随着web应用功能变得越来越丰富、越来越复杂,js的地位也越来越靠近舞台中心。在目前情况下,如果没有一定的设计模式作为指导,其实很难开发出真正大型复杂的html5应用,也很难实现分工协作和持续维护。
于是MVC模式被很自然地引入到前端开发领域。也许某种意义上,前端开发的整个MVC,仅仅对应于后台开发眼中的View部分;但其实,如今前端MVC思想的深入性和重要性,对于整个web应用来说,其实一点也不逊色于服务器端的MVC。
具体而言,前端开发的Model相当于后台数据的镜像或缓存池,它和服务器端MVC中的Model概念一脉相承;View对应页面的呈现,主要指的是和html、css相关的代码,它和服务器端MVC中的View概念也非常相近。
显著的差别来自于controller:在后台应用中,用户和服务器之间的交互是通过http请求实现的,因此后台controller的表达形式是http请求的handler,并且和router(定义网站的url规则)紧密相关; 而前端应用中,用户和网页之间的交互主要是通过操作事件(例如点击鼠标、键盘输入等)实现的,因此前端的controller这里可以简单理解为各种交互事件的handler。
当然, 前端controller的概念是个大杂烩,比如angularjs中的controller被定义为一个作用域($scope)的闭包, 参考 AngularJS文档,这个闭包可以和一段html模版绑定在一起,最终将数据渲染到模版中形成页面。大约正是因为这种将数据和模版绑定的功能,非常类似于后台应用中的controller,因此很多框架包括angular将这种功能模块称为controller。为避免混淆,强调一下:后面我们用controller指代 “凡是和交互事件handler相关的代码单元”
backbonejs 是一个广受欢迎的轻量级MVC前端框架,我们先来看一个 Backbone.js Todo Example,下面是其View组件的代码片断:
<img src="https://pic4.zhimg.com/50/456c0ccb94fa025b9b3bd39069e8cbce_hd.jpg" data-rawwidth="470" data-rawheight="518" class="origin_image zh-lightbox-thumb" width="470" data-original="https://pic4.zhimg.com/456c0ccb94fa025b9b3bd39069e8cbce_r.jpg">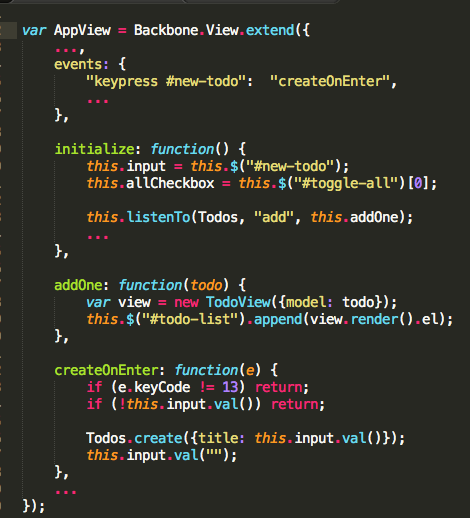
注意到这里createOnEnter是对键盘输入事件的响应,因此可视为一小段controller代码(即controller是“内嵌”在View组件中的),并且这段代码中对Todos (Model)进行了直接操作,即 View直接对Model产生修改(这是个危险的信号!因为前面我们在讨论“state-view单向流”的时候提到:一旦改变state和改变view的代码纠缠在一起,程序猿的内心就比较容易崩溃...)。也就是说backbone框架的MVC模式可以用下图表示:
<img src="https://pic1.zhimg.com/50/2592ffa0ebca6a9ba63ebf7cb23e9790_hd.jpg" data-rawwidth="480" data-rawheight="129" class="origin_image zh-lightbox-thumb" width="480" data-original="https://pic1.zhimg.com/2592ffa0ebca6a9ba63ebf7cb23e9790_r.jpg">
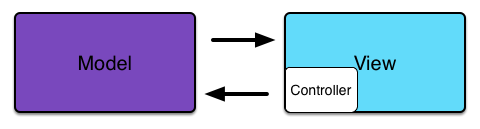
我们再来看angularjs的todoList实例 ( AngularJS Example:),可以发现其MVC模式(也有人称angular的模式为MVVM,这么细腻的区分感觉没太大必要)也完全符合上面的图示。
虽然这种View对Model直接修改的方式非常直截了当,适合小型web应用,然而一但web应用中存在多个Model,多个View,那么Model和View之间的决定关系就可能变得混乱,难以驾驭,如下图所示:
<img src="https://pic1.zhimg.com/50/df2d758b3fe498d20be49c6d3523066c_hd.jpg" data-rawwidth="426" data-rawheight="417" class="origin_image zh-lightbox-thumb" width="426" data-original="https://pic1.zhimg.com/df2d758b3fe498d20be49c6d3523066c_r.jpg">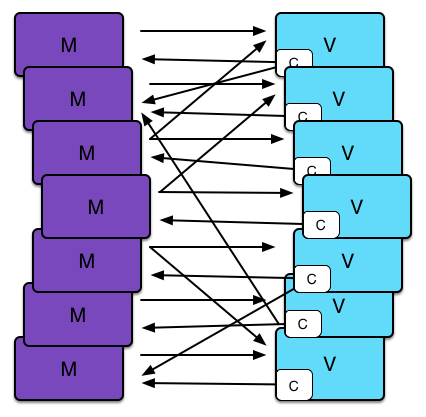
也就是说类似于上述代码片断中常见的MVC模式,阻碍了Model和View的组件化拆分(只有Model和View个数较少的时候,依赖关系才比较清晰)。因此,facebook团队总结说: MVC模式难以scale up! [参考链接]( Facebook: MVC Does Not Scale, Use Flux Instead [Updated])
怎么破??
c. Flux模式
前面我们提到“单向流”的思维状态可以让大脑更加轻松驾驭,本质上而言,这也是为什么上面这种杂乱的双向图示让我们感到无所适从的原因。我们注意到:之所以图示中 Model-View (MVC中的Model大体上可以看作是前面提到的State)的“单向流”被破坏,是由于修改Model的Controller代码像一把黄豆一样散落在了各个View组件的内部,如果可以用某种方式把这些散落的代码单独收拢到一起,是不是就让这可以让这张图示恢复秩序呢?好,我们顺着这个思路想下去。
现在我们又可以从服务器端的MVC模式中获得灵感了!因为我们注意到,服务器端的controller通常也需要对很多Model产生修改,但在代码结构中却集中在一起,没有散落一地。原因很简单,由于server和client是远程通信的关系,因此为了尽量减少通信耦合,client每个操作的全部信息都以http请求的形式被概括成了精简的“作用量”(action)。请求的url路径约定了用户的操作意图(当然RESTful概念中,请求的method也可以反映操作意图),request参数表征了该“意图”的具体内容。正是基于这个action的抽象,client端的交互操作才可以被集中转移到server端的controller中做统一响应。
对比之下,我们立刻发现上述代码片断中前端MVC模式的“痛点”所在:不是MVC模式错了,而是我们压根缺少了一个和用户交互行为有关的action抽象!因此,对model的具体操作才没法从各个view组件中被剥离出来,放到一处。
参考http请求,我们将要定义的action,需要一个typeName用来表示对model操作的意图(类似于http请求的url路径),还可能需要其他字段,用来描述怎样具体操作model(类似于http请求的参数)。
也就是说,当用户在view上的交互行为(例如点击提交按钮)应当引起Model发生变化时,我们不直接修改model,而是简单地dispatch一个action(其实跟常见的event机制没有什么区别)以表达修改model的意图,这些action将被集中转移给数据端(models),然后数据端会根据这些action做出需要的自我更新。同时,我们考虑到react中view组件的树状分流结构,所以有如下图所示:
<img src="https://pic2.zhimg.com/50/b3b8c82b1450675e2c1c9acf76825784_hd.jpg" data-rawwidth="600" data-rawheight="343" class="origin_image zh-lightbox-thumb" width="600" data-original="https://pic2.zhimg.com/b3b8c82b1450675e2c1c9acf76825784_r.jpg">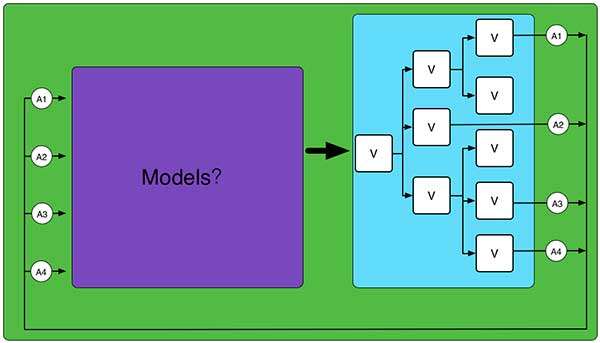
图中A表示Action,V表示View组件,Models部分的结构会进一步讨论。稍微总结一下:从代码层面而言,flux无非就是一个常见的event dispatcher,其目的是要将以往MVC中各个View组件内的controller代码片断提取出来放到更加恰当的地方进行集中化管理,并从开发体验上实现了舒适清爽、容易驾驭的“单向流”模式。 所以我觉得,Flux与其说是对前端MVC模式的颠覆,倒不如说是对前端MVC思想的补充和优化。
但为了区分于以往的MVC模式,并向facebook的贡献表达敬意,后面我们将把这种优化后的 Model-View-Controller 开发模式在React背景下正式称为Flux模式
好,易筋经Flux练到这里,打完收工。到目前为止,我们看到React的独孤九剑可以通过View Component把页面呈现进行“原子化”拆分(即上图中兰色区域的树状分流结构);Flux打通了State-View的任督二脉(绿色区域),并通过action抽象把用户交互行为进行了“原子化”拆分;那么联系上面的图示,我们自然要问数据端(紫色区域)的处理,可否同样被“原子化”拆分?这是我们要聊的下一门武林绝学。
(六)凌波微步(数据端的“原子化”)
redux 登场
凌波微步指的是redux中的reducer机制,可以用来将state端的数据处理过程作“原子化”拆分。redux是来自函数式编程(Functional Programming)的一朵奇葩,据说很有背景([参考链接](Prior Art | Redux) )。本人还没有深究过,但一接触redux,就立刻被其reducer机制的轻盈小巧惊艳到(redux库本身也只有几kb,有必要的化,自己重写也不是难事),因此称其为“凌波微步”。
reducer,从代码上说,其实就是一个函数,具有如下形式:
(previousState, action) => newState
即,reducer作为一个函数,可以根据web应用之前的状态(previousState)和交互行为(通过flux中提到的action来表征),决定web应用的下一状态(newState),从而实现state端的数据更新处理。这个函数行为和大名鼎鼎的“Map-Reduce”概念中的Reduce操作非常类似,因而称这个函数为“Reducer”。
"shut up and show me the code"
ok,我们还是以todoList应用为例, 此处有[完整代码](Example: Todo List)。这里不打算详细讲解Redux的具体使用,而只想通过一个Redux对state数据进行操作的代码片断,管窥一下reducer机制对数据进行拆分和组装的简洁过程。代码片断如下:
<img src="https://pic3.zhimg.com/50/095d385bcdd8b0bd7114ac7bc3e6497f_hd.jpg" data-rawwidth="566" data-rawheight="624" class="origin_image zh-lightbox-thumb" width="566" data-original="https://pic3.zhimg.com/095d385bcdd8b0bd7114ac7bc3e6497f_r.jpg">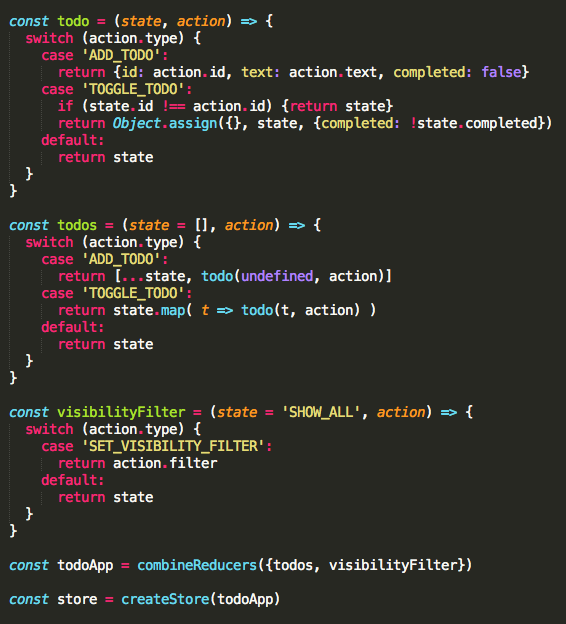
其中的todos是和任务列表数据相关的reducer,todo是和单条任务数据有关的reducer。注意:在todos的函数体内调用了todo,并将action作为参数原样传递给了todo,这种干净利落地通过函数调用将action由 “parent reducer” 传递给 “child reducer”,是redux实现数据处理拆分的普遍方式。回味一下,我们应该可以体会到, 这种数据处理“原子化”拆分的方式和react中view组件的拆分有异曲同工之妙,二者都会形成一种“树状”分流结构(在react的view hierarchy中,数据通过props的直接赋值实现单向流;在redux的reducer hierarchy中,数据通过action的函数传参实现单向流)。
visibilityFilter是和列表显示状态相关的另一个reducer;combineReducers将visibilityFilter和todos合并为整个应用的reducer,也就是todoApp。这个过程,从感觉上也和react中view组件的合并过程非常相像。
createStore是一个工厂函数。通过它,todoApp(相当于一个数据处理的引擎)被装配到整个应用的state容器,也就是store中。可以通过store的getState方法获取整个应用的state;同时,store也是一个event dispatcher,可以通过其dispatch和subscribe方法,分别实现触发action事件和注册对action事件的响应函数。总言之,从概念上来说 Redux = Reducer + Flux
三、总结
全体亮相
好,现在React开发模式中的几个核心概念已经全部出场亮相。我们俯瞰一下整个开发流程:首先,react框架为我们理顺了 store --> view 的“单向”工作流(store是state的容器);然后,redux框架为我们理顺了 view --> store 的**“单向”**工作流。并且,react和redux都以组件化的形式可以将各自负责的功能进行灵活地组装或拆分,最大程度上确保我们“一次只需要专注于一个局部问题”。具体来说,分为以下步骤:
- 单例store的数据在react中可以通过view组件的属性(props)不断由父模块**“单向”**传递给子模块,形成一个树状分流结构。如果我们把redux比作整个应用的“心肺” (redux的flux功能像心脏,reducer功能像肺部毛细血管),那么这个过程可以比作心脏(store)将氧分子(数据)通过动脉毛细血管(props)送到各个器官组织(view组件)
- 末端的view组件,又可以通过flux机制,将携带交互意图信息的action反馈给store。这个过程有点像将携带代谢产物的“红细胞”(action)通过静脉毛细血管又泵回心脏(store)
- action流回到store以后,action以参数的形式又被分流到各个具体的reducer组件中,这些reducer同样构成一个树状的hierarchy。这个过程像静脉血中的红细胞(action)被运输到肺部毛细血管(reducer组件)
- 接收到action后,各个child reducer以返回值的形式,将最新的state返回给parent reducer,最终确保整个单例store的所有数据是最新的。这个过程可以比作肺部毛细血管的血液充氧后,又被重新泵回了心脏
- 回到步骤1
用图示的方式来表达,即,
<img src="https://pic4.zhimg.com/50/1f81a280ccdbedf6a3c6757f7ff4d9c7_hd.jpg" data-rawwidth="600" data-rawheight="345" class="origin_image zh-lightbox-thumb" width="600" data-original="https://pic4.zhimg.com/1f81a280ccdbedf6a3c6757f7ff4d9c7_r.jpg">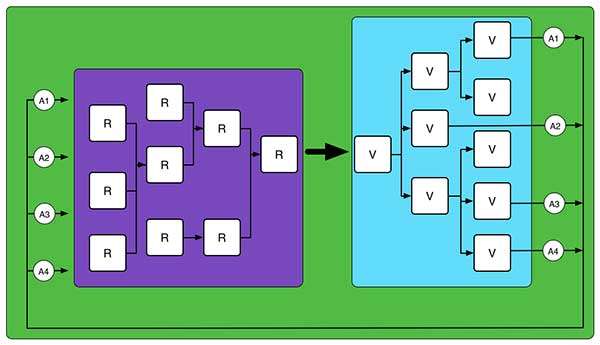
图中A表示Action,V表示View组件,R表示Reducer。为了确保我们比较容易理解程序的全局行为,或者说提高程序行为的确定性(predictable),我们一般期望具有类似职能的代码片断被“平铺”着摆放在一。因此图示中相同颜色区域的代码通常会被放到同一个文件夹/文件中。另外,同样出于提高程序的确定性,redux所遵循的函数式编程鼓励我们使用pure function和immutable。(函数式编程是另一个漫长的故事,这里就不再展开)
要你命三千
当然实际的react-redux开发步骤中也有不少变通,例如为了能在适当条件下节省些参数传递的代码,redux中提供了provider机制,它像《星际迷航》中的瞬间传送机一样,可以绕过view组件的hierarchy把state一步到位地传递到末端view组件;再比如redux虽然鼓励使用pure function(即不含side effect的函数), 但我们一般还是会通过side effect实现store和服务器端的通信。这些变通,觉得是好事。毕竟再严格的框架,也经不起胡乱使用;再完美的框架,也很难说能包治百病,倒不如提供一些台阶,让程序猿们去自由发挥吧。
除了React、Reducer、Flux这三驾马车的主线情节外,react开发模式的周边生态也有很多振奋人心的新鲜事物,例如:拥抱函数式编程和模块化的es6语法,日趋成熟的模块资源管理工具npm,自动化编程及打包神器webpack, 让初始化性能和SEO不再成为问题的server-side rendering方案,将触角伸到原生开发领域的React-Native系列项目等等,这些零零总总加起来,不由得让人想起《国产凌凌漆》中集各种武器于一身的终极武器 “要你命三千”!
<img src="https://pic1.zhimg.com/50/07bbeff3e0379855a772fe3d40cf2612_hd.jpg" data-rawwidth="400" data-rawheight="225" class="content_image" width="400">

<img src="https://pic1.zhimg.com/50/b4203f67905e47e8d80bc3dc1e0d3946_hd.jpg" data-rawwidth="400" data-rawheight="280" class="content_image" width="400">

一把玄铁重剑,一本易筋经,一套轻功步法,以及“要你命三千”!实乃居家旅行、应用开发必备良药!
转载于:https://www.cnblogs.com/dreamingbaobei/p/8476984.html
最后
以上就是幽默小鸭子最近收集整理的关于理顺react,flux,redux这些概念的关系的全部内容,更多相关理顺react,flux,redux这些概念内容请搜索靠谱客的其他文章。








发表评论 取消回复